python爬虫-爬取蜂鸟上的图片
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟浏览器发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
在使用python之前,得先安装一些python库来支持爬虫的运行
from bs4 import BeautifulSoup #网页解析,获取数据
import requests #发起请求,接收响应
import os #对爬取数据的路径,文件进行处理
import re #正则表达式,进行字符串匹配这些库都可以通过命令行输入:pip install 库名进行安装,如果安装好了还不能用,那就有可能是版本较低或编译环境不是使用系统默认的环境(我就使用vscode没选择系统环境,为此花了大把时间)
爬虫项目:
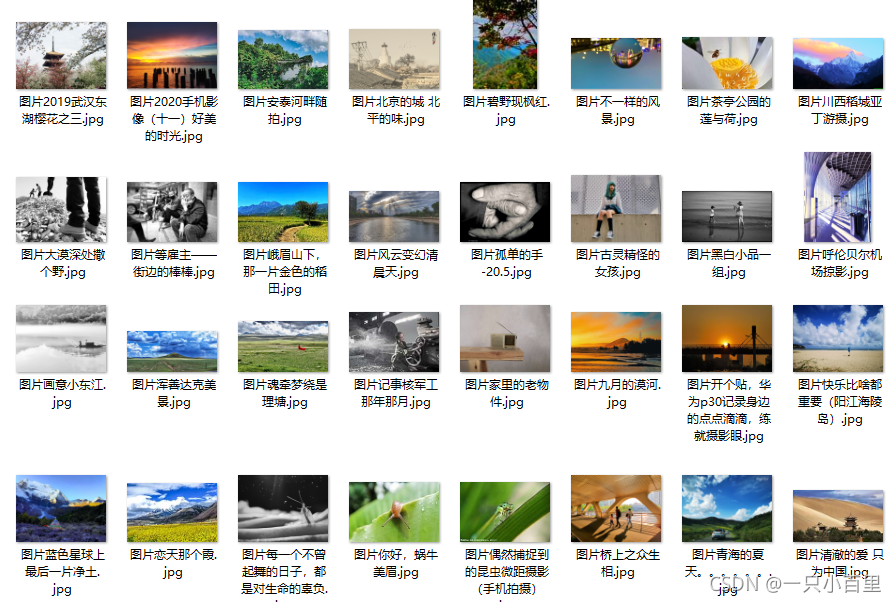
爬取蜂鸟网上的壁纸,并将其保存在D盘里https://photo.fengniao.com/https://photo.fengniao.com/![]() https://photo.fengniao.com/ 爬取效果如下图:
https://photo.fengniao.com/ 爬取效果如下图:
图一是终端运行截图:

python代码:
from bs4 import BeautifulSoup
import requests
import os
import re
urlHead = 'https://photo.fengniao.com/' #爬取网站地址
url = 'https://photo.fengniao.com/pic_48723655.html' #网站中一张图片地址,即爬取的初始位置def getHtmlurl(url): # 获取网址try:r = requests.get(url)# 解决解析乱码问题r.raise_for_status()r.encoding = r.apparent_encodingreturn r.textexcept:return ""
def getpic(html): # 获取图片地址并下载,再返回下一张图片地址# 指定BeautifulSoup的解析器为:html.parsersoup = BeautifulSoup(html, 'html.parser')all_img = soup.find('a', class_='downPic')img_url = all_img['href']reg = r'(.*?)
' # 找到网页源代码中图片链接的位置,使用 正则表达式截取图片链接r'(.*)' # 正则表达式reg_ques = re.compile(reg) # 编译一下正则表达式,运行的更快image_name = reg_ques.findall(html) # 匹配正则表达式urlNextHtml = soup.find('a', class_='right btn')urlNext = urlHead + urlNextHtml['href']print('正在下载:' + img_url)root = 'D:\图片'path = root + image_name[0] + '.jpg'try: # 创建或判断路径图片是否存在并下载if not os.path.exists(root):os.mkdir(root)if not os.path.exists(path):r = requests.get(img_url)with open(path, 'wb') as f:f.write(r.content)f.close()print("图片下载成功")else:print("文件已存在")except:print("爬取失败")return urlNext
# 主函数
def main():html = (getHtmlurl(url))print(html)return getpic(html)# 循环下载图片!
if __name__ == '__main__':for i in range(1, 50):url = main()爬取步骤:
1.请求网址
2.获取网址
3.解析网页
4.保存数据
但大多数网站都是有反爬取机制的,这时我们需要伪装成浏览器或者使用代理等方式。
设置headers信息,模拟成浏览器https://blog.csdn.net/Nurbiya_K/article/details/104957301![]() https://blog.csdn.net/Nurbiya_K/article/details/104957301
https://blog.csdn.net/Nurbiya_K/article/details/104957301
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!