【深度学习】激活函数合集
神经网络中激活函数的主要作用是提供网络的非线性建模能力,如不特别说明,激活函数一般而言是非线性函数。假设一个示例神经网络中仅包含线性卷积和全连接运算,那么该网络仅能够表达线性映射,即便增加网络的深度也依旧还是线性映射,难以有效建模实际环境中非线性分布的数据。加入(非线性)激活函数之后,深度神经网络才具备了分层的非线性映射学习能力。
本文代码链接:23种激活函数示例及可视化代码
目录
一、ELU
二、Hardshrink
三、Hardsigmoid
四、Hardtanh
五、Hardswish
六、LeakyReLU
七、LogSigmoid
八、PReLU
九、ReLU
十、ReLU6
十一、RReLU
十二、SELU
十三、CELU
十四、GELU
十五、Sigmoid
十六、SiLU
十七、Mish
十八、Softplus
十九、Softshrink
二十、Softsign
二十一、Tanh
二十二、Tanhshrink
二十三、Threshold
参考
一、ELU
paper:Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs)
特点:
1、输出有负值,使得其输出的平均值为0;
2、右侧的正值特性,可以像relu一样缓解梯度消失的问题;
3、ELU在负值时是一个指数函数,具有软饱和特性,对噪声更鲁棒;
公式:
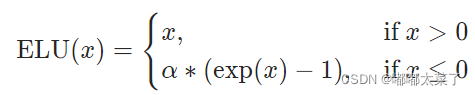
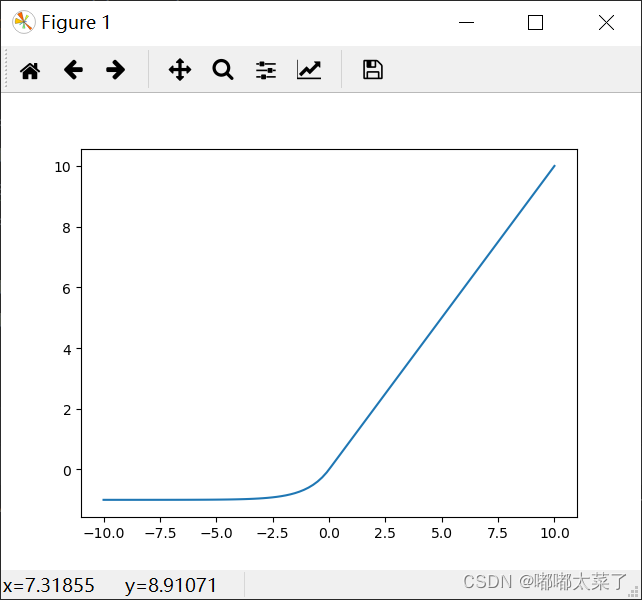
图像:
二、Hardshrink
公式:
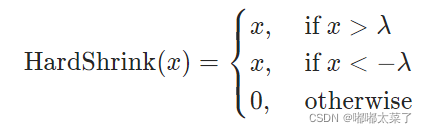
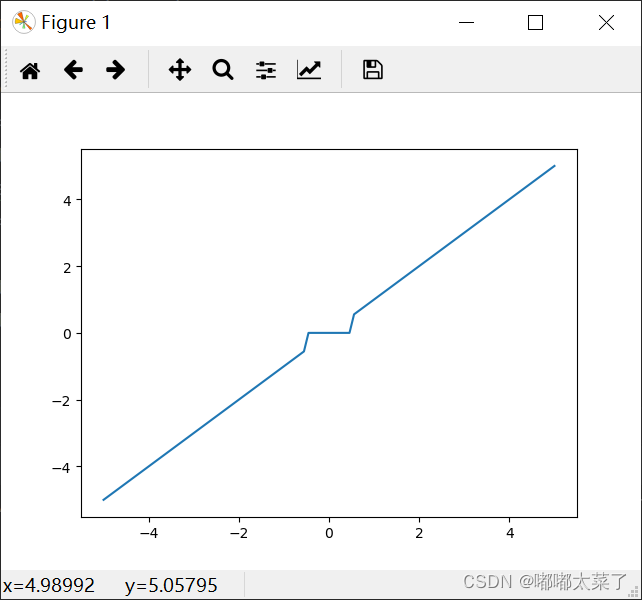
图像:
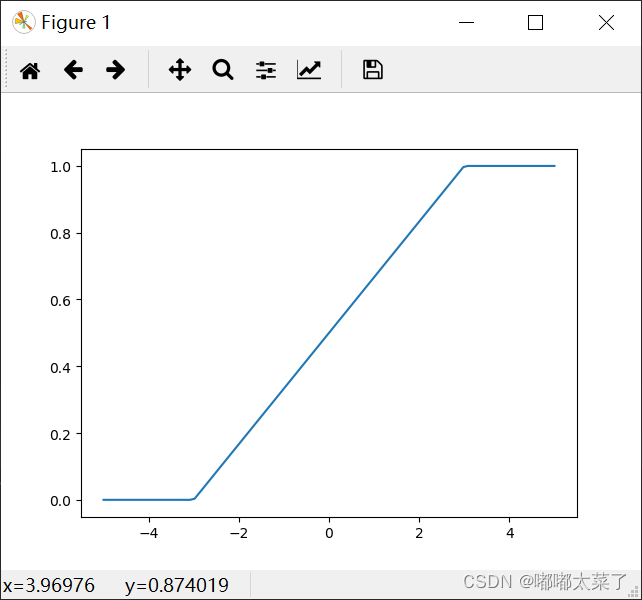
三、Hardsigmoid
特点:
1、sigmoid的近似,计算速度很快;
2、x在[-3,3]范围内,梯度固定;
公式:
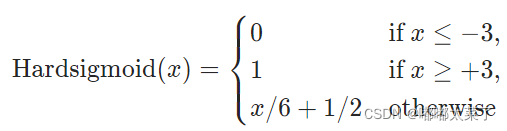
图像:
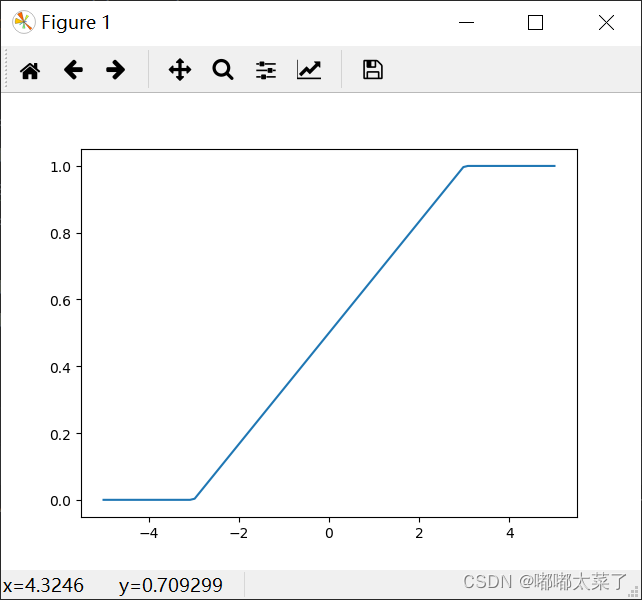
四、Hardtanh
特点:
1、tanh的近似函数;
2、x在[-1,1]范围内梯度值固定;
公式:
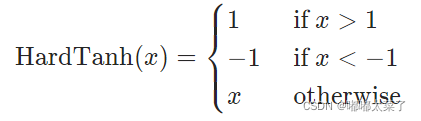
图像:
五、Hardswish
论文:Searching for MobileNetV3
特点:
1、swish激活函数的近似函数,简化计算;
2、在更深的层中使用才能体现效果;
公式:
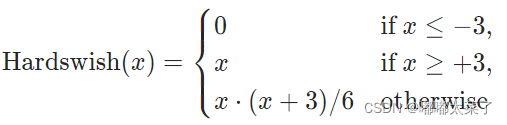
图像:
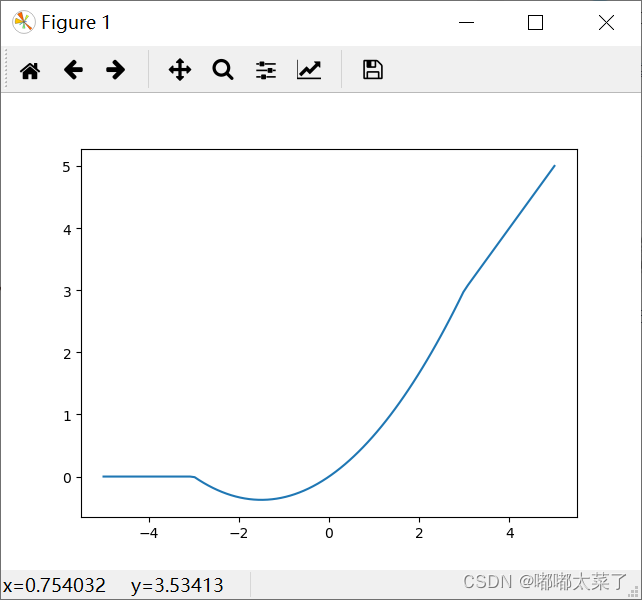
六、LeakyReLU
特点:
1、对于ReLU, 当输入为负值时,其输出为0,在反向传播时梯度为0,对应的神经元参数将无法更新,如果所有的输入都是负值,那么网络将无法学习,LeakyReLU可以解决该问题;
公式:
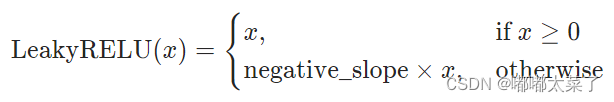
图像(绘图时为了方便看出负值,系数取0.1,一般LeakyReLU负值斜率为0.01):
七、LogSigmoid
公式:
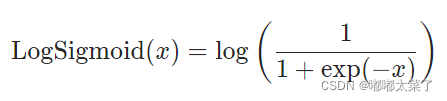
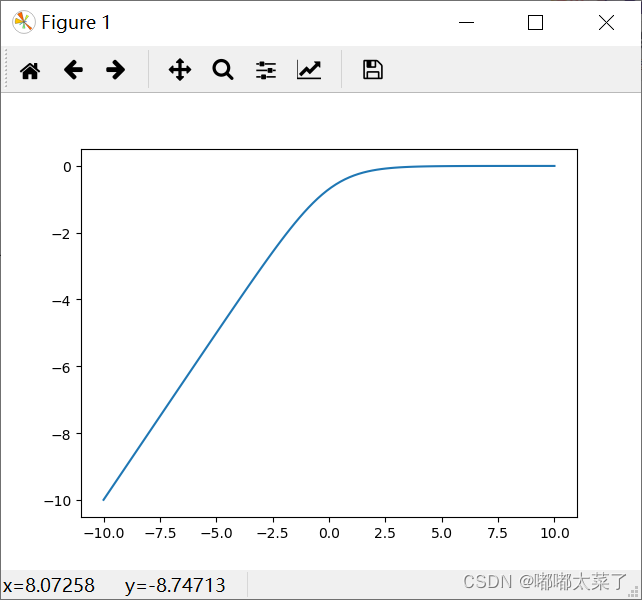
图像:
八、PReLU
公式:
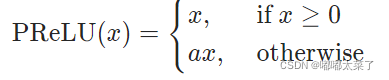
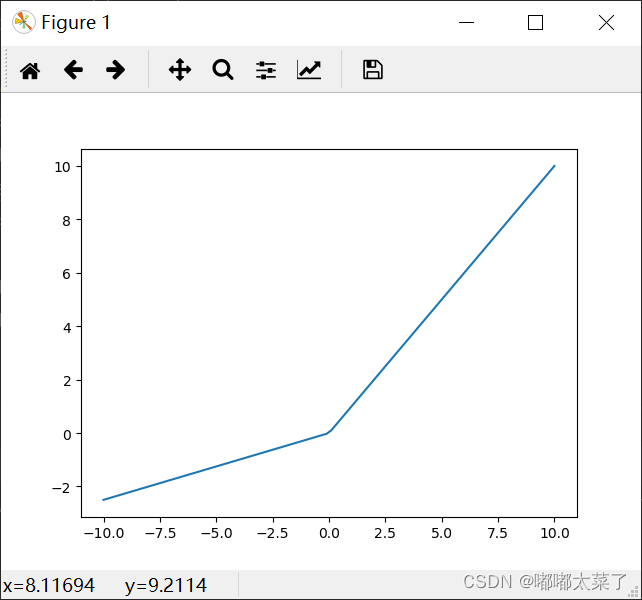
图像:
九、ReLU
特点:
1、当输入大于0时,梯度为1,能够有效避免链式求导法则梯度相乘引起的梯度消失和梯度爆炸;
2、计算成本低;
3、当输入都小于0时,输出全部为0,梯度为0,神经元将全部“死亡”,参数无法更新。
公式:
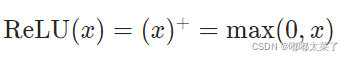
图像:
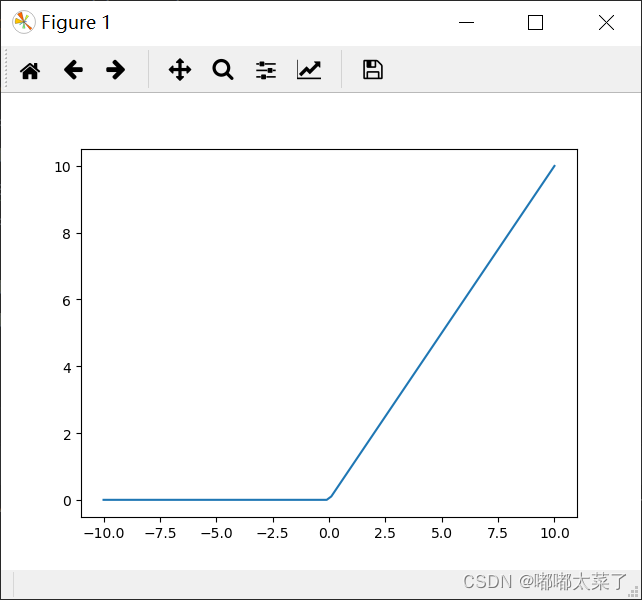
十、ReLU6
公式:
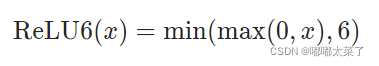
图像:
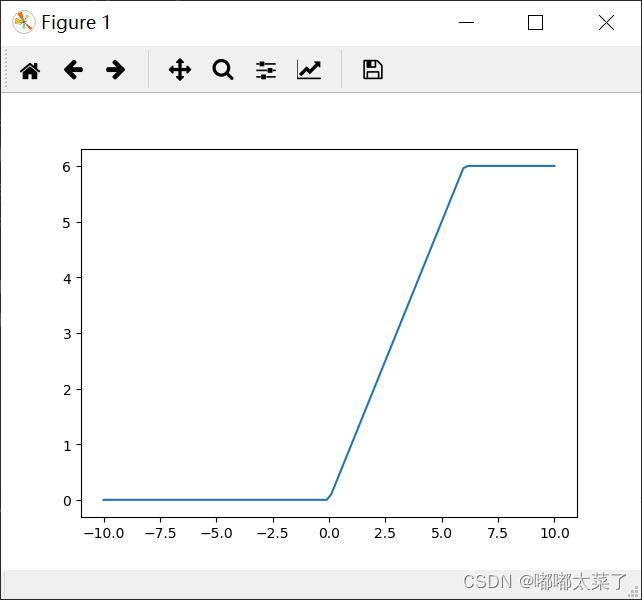
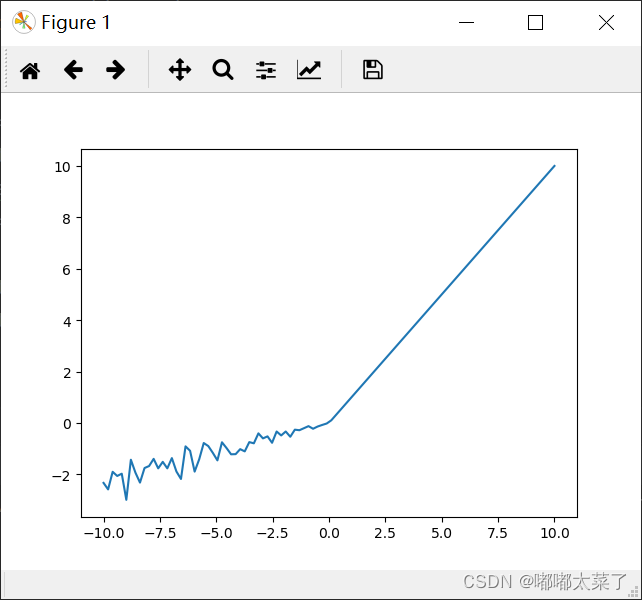
十一、RReLU
paper:Empirical Evaluation of Rectified Activations in Convolutional Network
特点:
1、在训练阶段,负数部分的斜率是一定范围内随机抽样的;
2、推理时,负数部分的斜率固定。
公式:
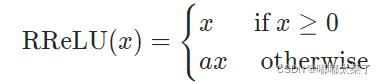
图像:
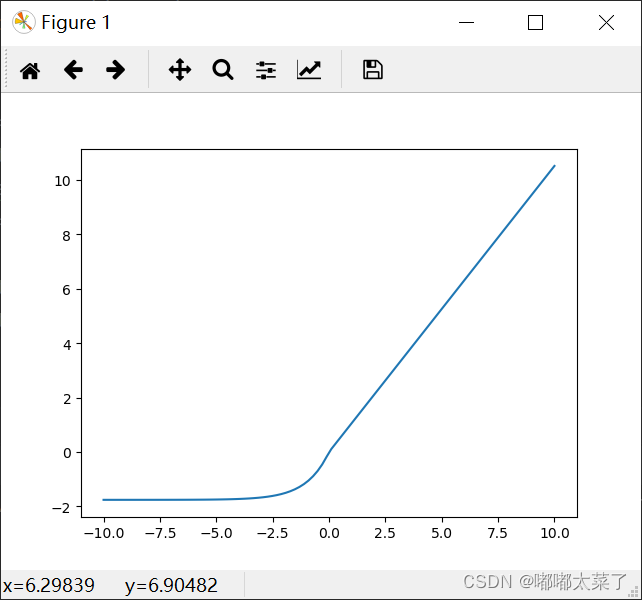
十二、SELU
ELU加上了一个scale。
公式:
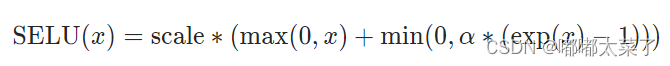
图像:
十三、CELU
ELU当输入小于0时,指数上添加缩放因子。
公式:
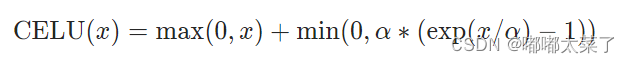
图像:
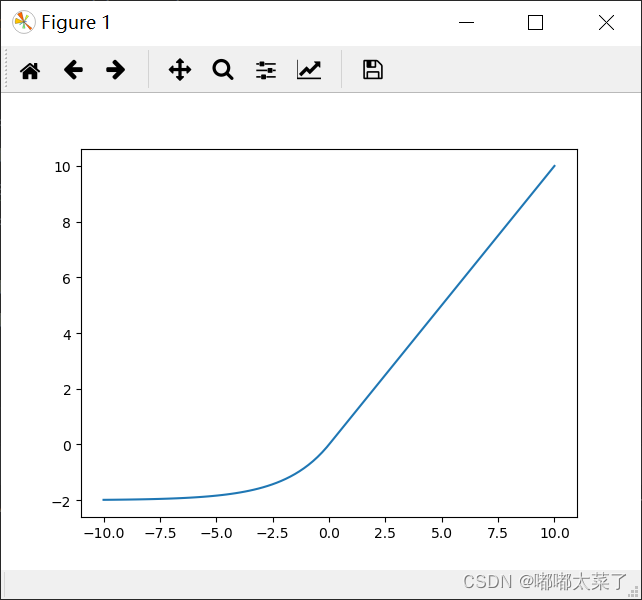
十四、GELU
公式(是高斯分布的累计分布密度函数):
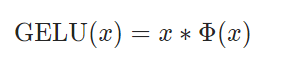
公式近似:
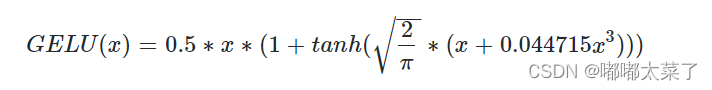
图像:
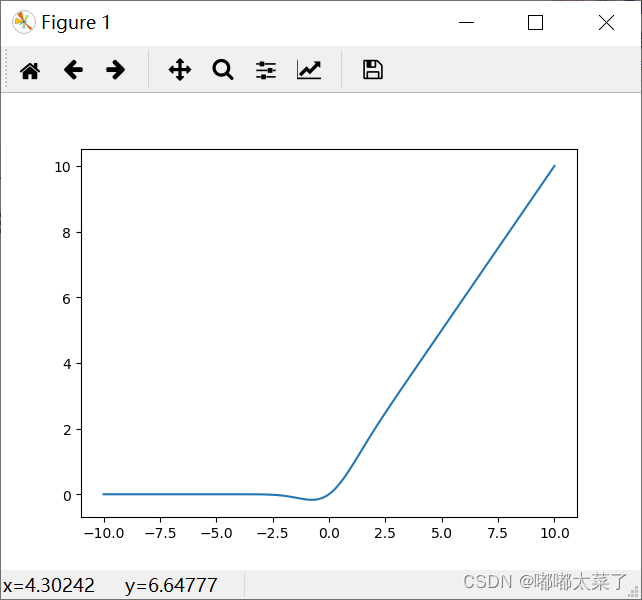
十五、Sigmoid
特点:
1、输出范围(-1,1),是饱和激活函数;
2、梯度最大为0.25(x=0),可能发生梯度消失;
3、常用于输出2分类概率
公式:
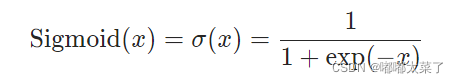
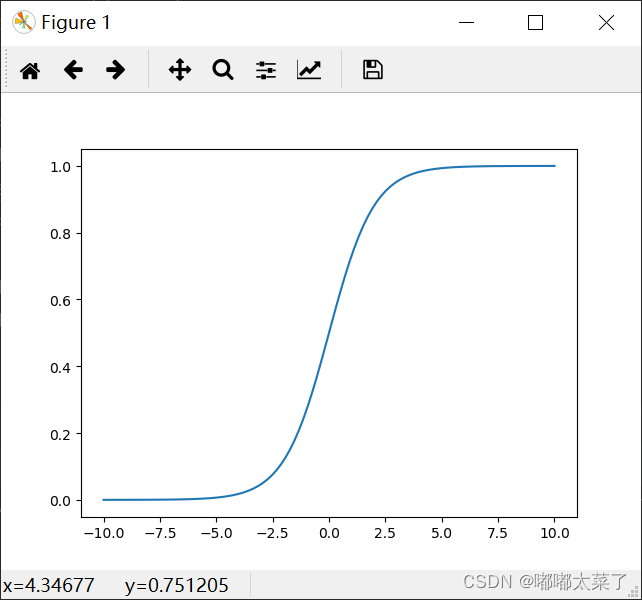
图像:
十六、SiLU
公式:
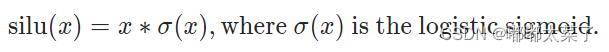
图像:
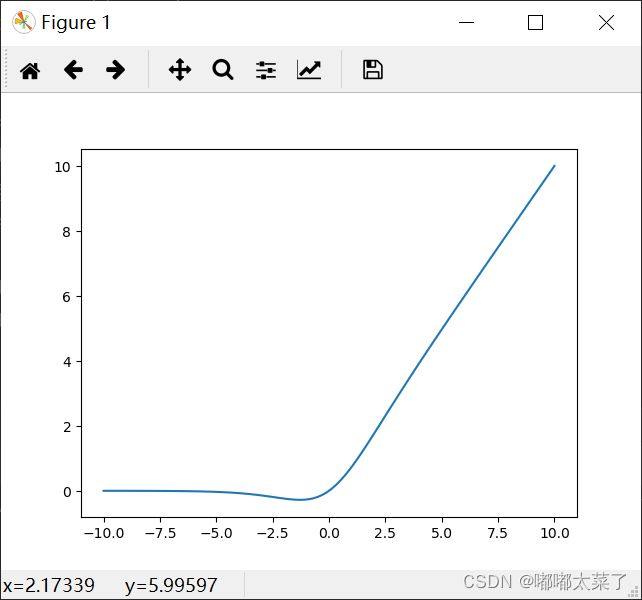
十七、Mish
paper:Mish: A Self Regularized Non-Monotonic Activation Function
公式(Softplus见下一个激活函数):
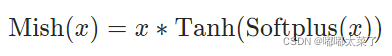
图像:
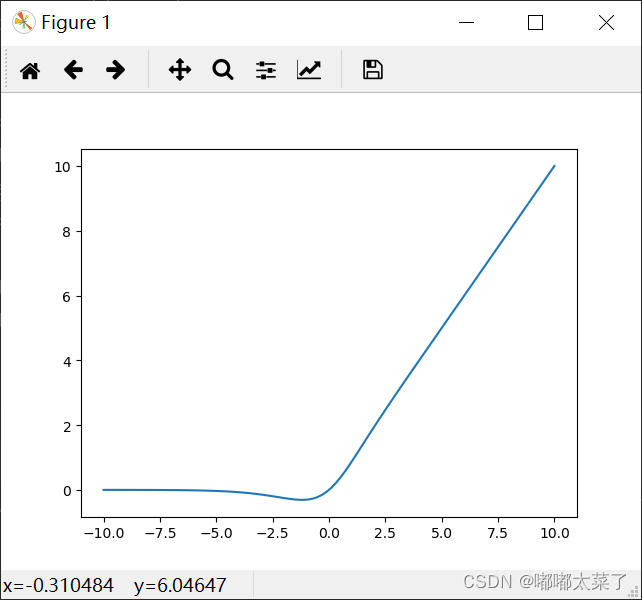
十八、Softplus
公式:
![]()
图像:
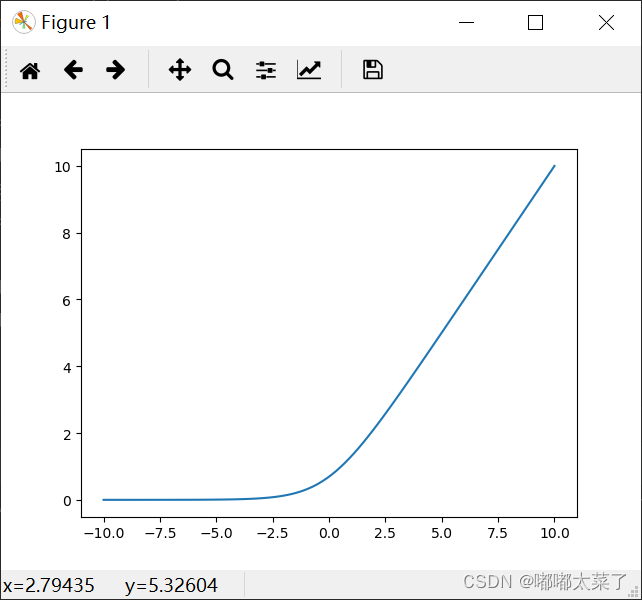
十九、Softshrink
和Hardshrink区别在于是否连续。
公式:
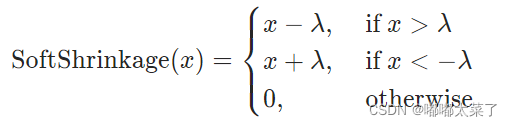
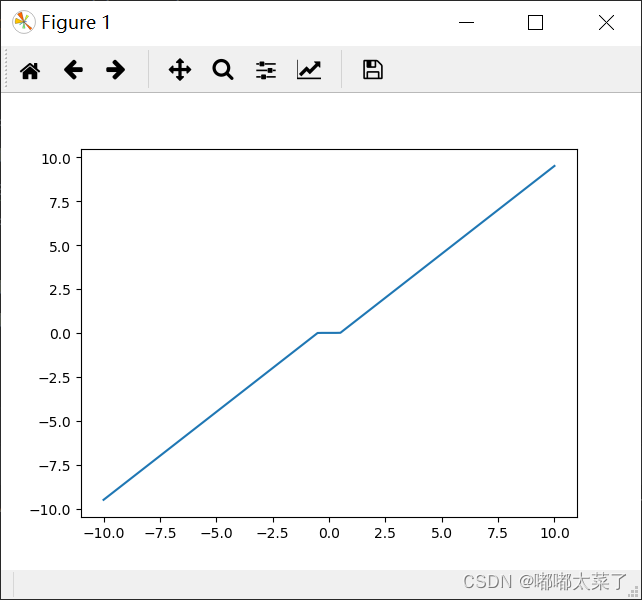
图像:
二十、Softsign
公式:
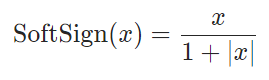
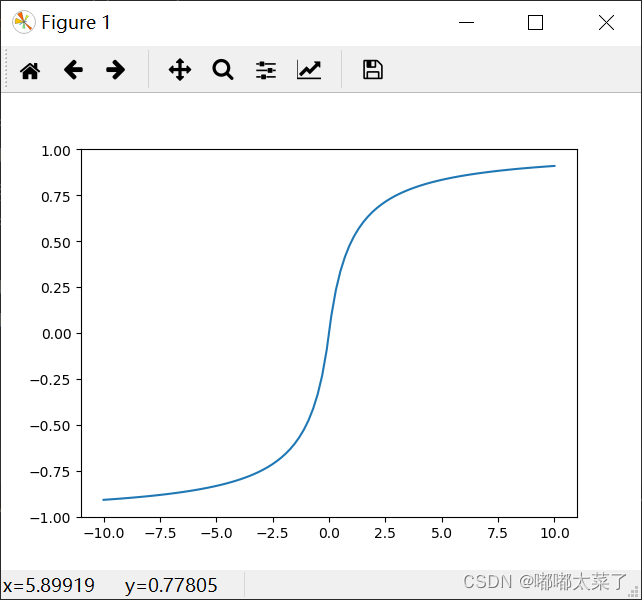
图像:
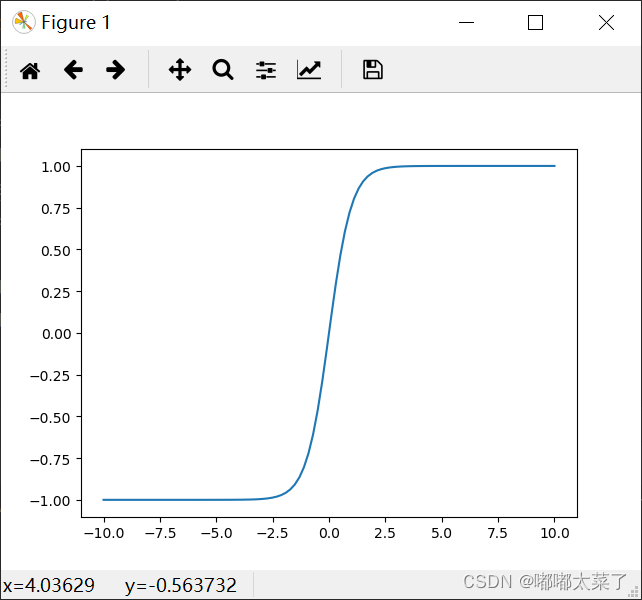
二十一、Tanh
公式:
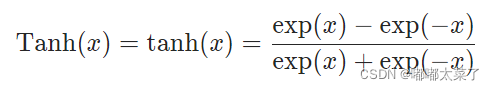
图像:
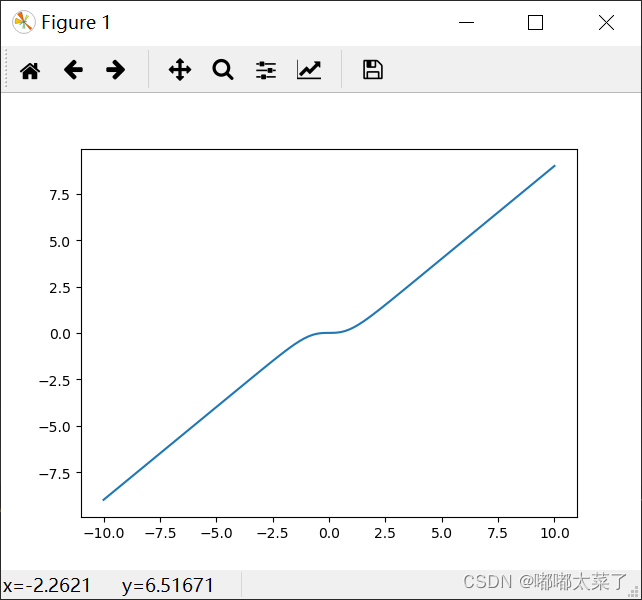
二十二、Tanhshrink
公式:
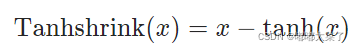
图像:
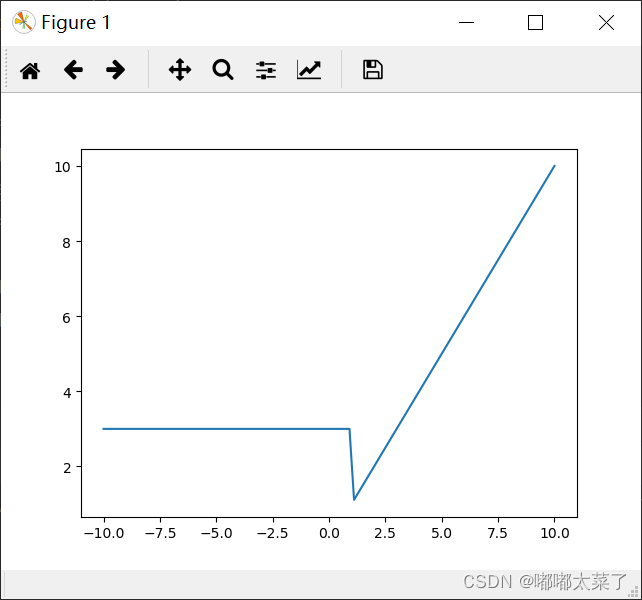
二十三、Threshold
公式:
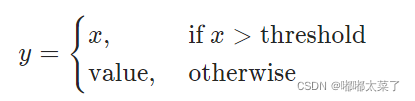
图像(threshold=1, value=3):
参考
1、深度学习中的激活函数 - 简书
2、激活函数(relu,prelu,elu,+BN)对比on cifar10
3、ELU激活函数
4、 本文代码链接:23种激活函数示例及可视化代码
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!