软件工程第四次作业 猫狗大战挑战赛
软件工程第四次作业 猫狗大战挑战赛
第一部分谷歌 Colab 上完成猫狗大战VGG模型的迁移学习
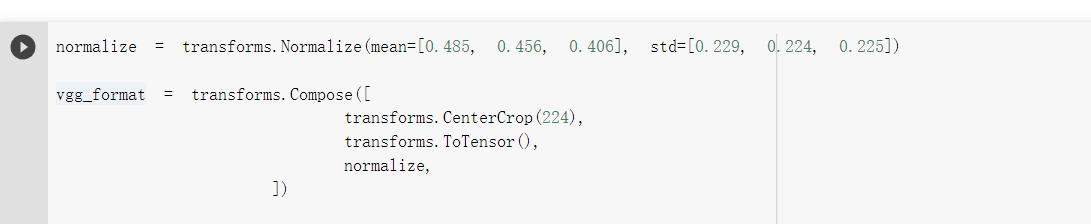
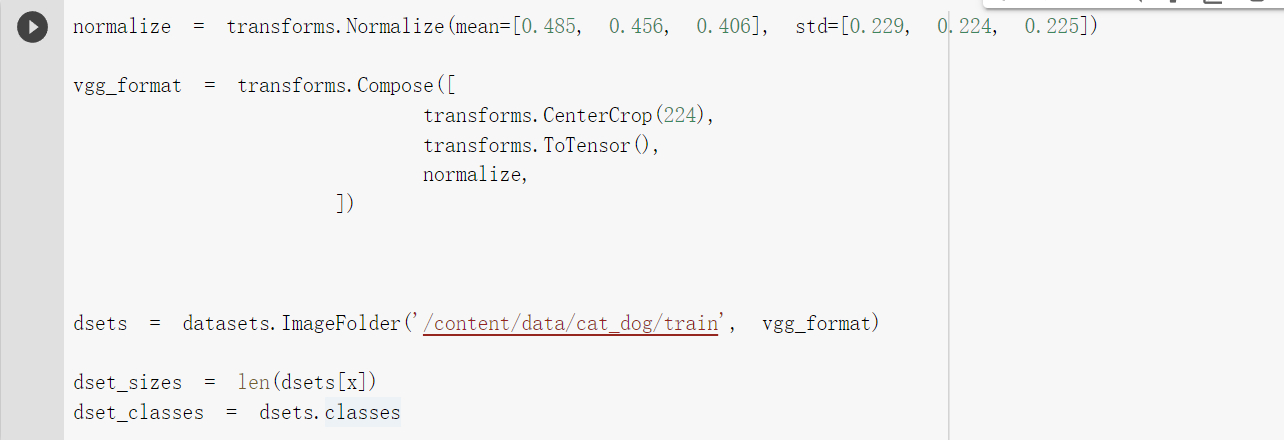
对图像归一化进行处理
然后在图像中间进行裁剪
进行灰度 在对图像进行归一化处理 不知道这个参数是怎么来的 前面用过 mean=(0.5 0.5 0.5)std=(0.5,0.5,0.5)刚好讲最大值和最小值放缩到(-1,1)

按照之前定义的vgg_format形式读取数据
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-733MzEsS-1666103871080)(C:\Users\zzf\AppData\Roaming\Typora\typora-user-images\image-20221017135906884.png)]
制作训练集和测试集
训练集 一个batch是64 打乱顺序可以提高准确率
测试集一个batch是5 测试的时候可以按顺序
多线程来加速

loader_valid一共2000张 一个batch是5所以进行400轮

可以看到这个图片的标签 和这个图片的大小 数量
因为之前截取的是中间的224 所以是两个224 然后一组有5个

这里定义了一个展示图片的小程序

讲第一组batch组合成为一张图片并且输出 图片和label
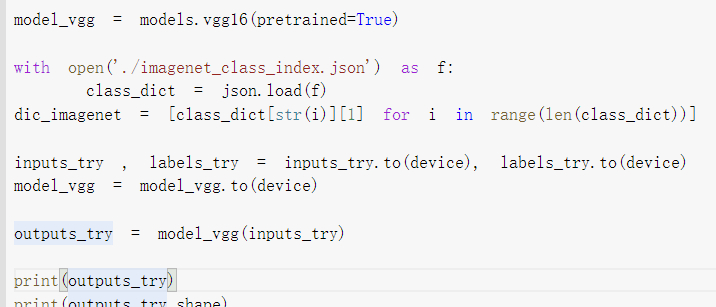
这次实验是直接用了训练好的vgg模型
对于我们上一步展示的图片进行预测
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RgRzn6Dk-1666103871082)(C:\Users\zzf\AppData\Roaming\Typora\typora-user-images\image-20221017162239305.png)]
打印结果看一下
发现最后的结果是5*1000的矩阵
这里是神经网络训练的比较强大 有1000个类别
这里只需辨别是猫还是狗
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UoE3ijuI-1666103871082)(C:\Users\zzf\AppData\Roaming\Typora\typora-user-images\image-20221017162621985.png)]
上一轮结果很难懂是什么意思
但我们做分类问题 将函数归一化
dim=1 按行处理
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rkEqvVud-1666103871082)(C:\Users\zzf\AppData\Roaming\Typora\typora-user-images\image-20221017164119783.png)]
这里归一化的总和是1
打印训练的最大概率
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-beUT34US-1666103871083)(C:\Users\zzf\AppData\Roaming\Typora\typora-user-images\image-20221017164222961.png)]
最后的结果和标签检查 发现正确率很好

打印一下这个神经网络
特征提取的参数不需要修改
修改一下分类的函数
之前是分成1000类
现在只需要分成两类
因为用的这个模型 最后分类比较多 所以我们让最后一个全连接层的为2,我们只需要区分猫和狗就行
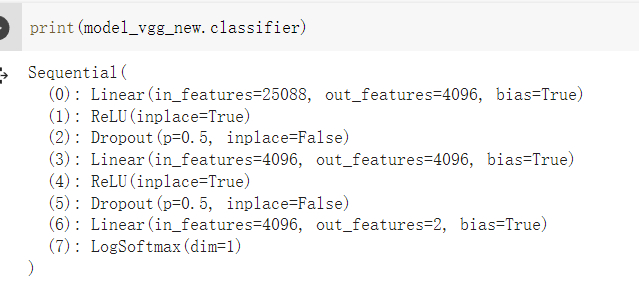

修改后和修改前

损失函数和学习率 一般都是定义好的 学习率一般都是0.001
采用梯度下降的方法
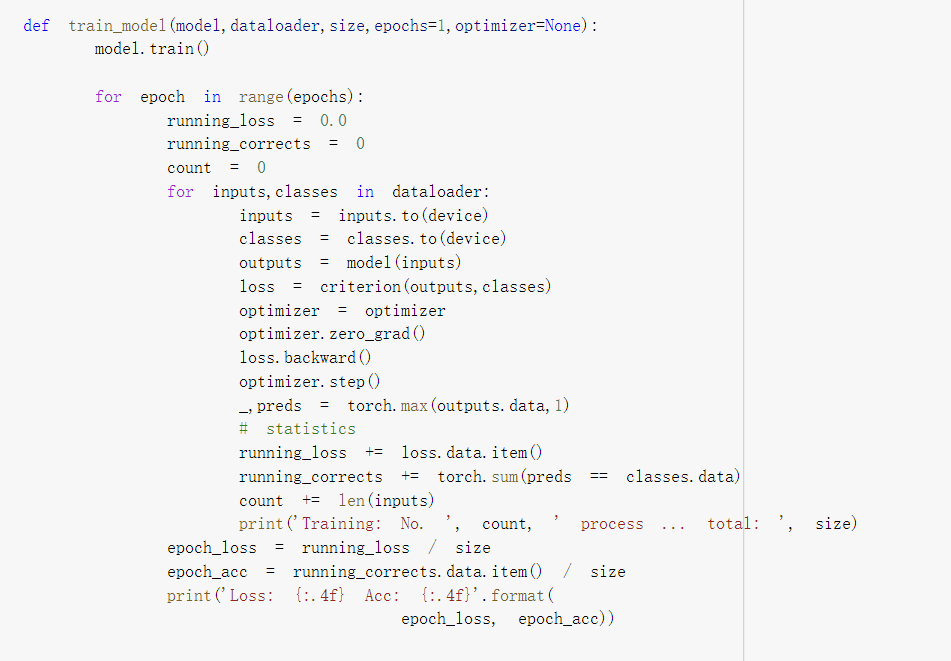
定义这个训练函数
传入定义好的模型 数据 数据大小 epochs 和优化函数
开始训练
将标签和输入传入
得到输出结果
这里好像没有用损失函数 不知道直接调用这个criterion是默认的损失函数吗
然后是优化函数
先将梯度归零 optimizer.zero_grad()
然后反向传播计算得到每个参数的梯度值loss.backward()
最后通过梯度下降执行一步参数更新optimizer.step()
传统的学习方式
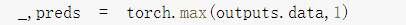
得到预测最大可能性的下标
因为只有0和1
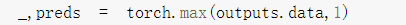
统计数据计算失误率和准确率

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-shkXofnK-1666103871085)(C:\Users\zzf\AppData\Roaming\Typora\typora-user-images\image-20221017184947262.png)]
开始训练
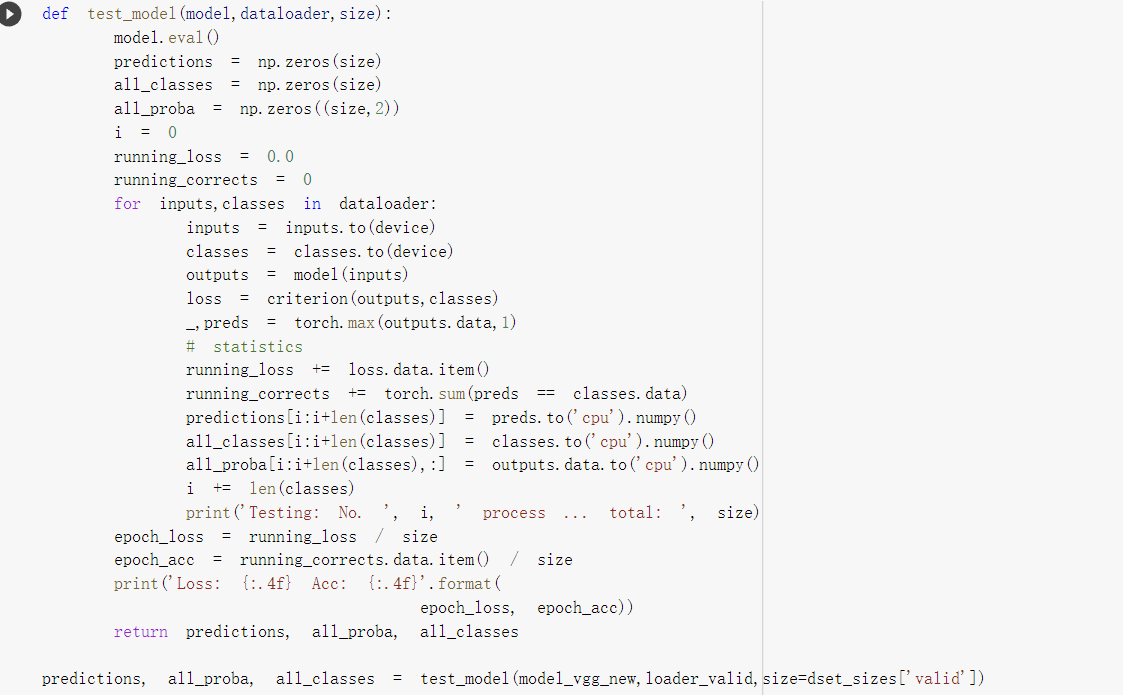
定义测试函数 和之前的差别不大


这里展示了一下测试的结果
将8张图片制作成一张然后输出
第二部分

下载数据指定目录
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yTTAhH6n-1666103871086)(C:\Users\zzf\AppData\Roaming\Typora\typora-user-images\image-20221017201225516.png)]
解压
发现colab好像没有装解压rar的工具 下载一下就好

开始制作lader数据集
我们发现
这里的数据结构不能直接调用datasets.ImageFolder 这个封装好的函数
所以我们现在有两种办法 一是将文件目录结构改为官方接口的形式
二是自己重写dataset函数
我选择的第一种 比较简单的一个选择分类
import os
import shutilpathlist=os.listdir('/content/data/cat_dog/train')for x in pathlist:res=x[:3]dir='/content/data/cat_dog/train'if res=="cat" :shutil.move(os.path.join(dir, x),'/content/data/cat_dog/train/cats')else : shutil.move(os.path.join(dir, x),'/content/data/cat_dog/train/dogs')
这里是一个简单的分类 将文件是cat的放入cats文件夹
是dog放入dogs文件夹

对文件做好分类我们就开始制作数据集

可以打印一些结果康康

我们可以看出 64一个batch 224*224

打出一个batch看一下
用vgg模型修改训练的输出层获得结果
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZgrxvdHs-1666103871088)(C:\Users\zzf\AppData\Roaming\Typora\typora-user-images\image-20221018143525718.png)]
虽然很不理解 训练的数据多了 为什么结果还没之前的优秀
接下来我们对测试集进行训练

这里就无所谓标签了
我们对数据进行简单dataset 用的还是之前的接口

我们对图片进行预测
得到结果
我们要输出一个csv
然后字典序就是 0 1 10 100 这样的顺序
我们可以看看dataloder里面的数据排序
然后做一个和里面顺序一样的一个list
两个list zip()打包一下

用pands里面的dataframe做一个dataframe

可以看一下结果
然后将这个数据输出

不带索引 不带序号的输出
然后就可以提交了

然后我就提交了 莫名的得到了这个分数
后来我仔细的看了一下输出的顺序
答案要求的好像是从0-1999
我这里因为之前用的是str类型
所以排序就是0 1 10 100
这样得顺序
本来应该转换成int在排序一遍
涂了个省事
我直接用excel打开csv
然后手动排序
排完大概是这样.
然后在提交

最后得到了结果
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!