Python爬虫51job
Python爬虫51job
最近闲的没事来爬个51job,爬取了一千条数据。
结果如图:
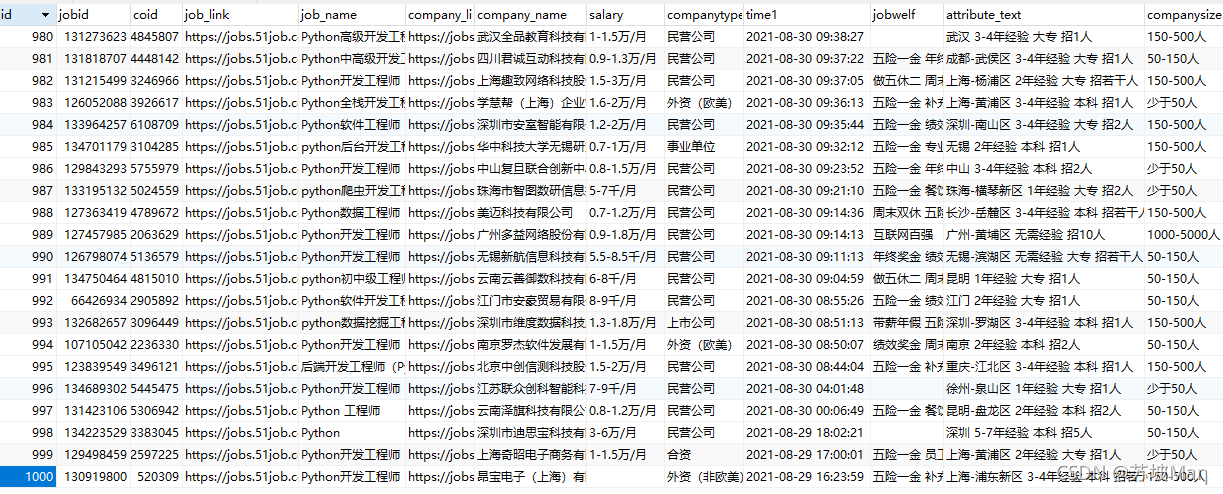
暂时只是将里面的职位爬取出来放到了mysql数据库,后续再做其他更改。
方法也很简单,就获取网页,解析网页,存储数据到数据库。
1.获取网页
先引入需要的包:
import pymysql
import re
from bs4 import BeautifulSoup
import urllib.request,urllib.error,urllib.parse
在51job网页中,具体搜索网址如下:
https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,1.html
在这个网址中,前面的000000,000000分别是城市编码,地区编码,后面的99是指薪资范围。比如重庆渝中区就是060000,060100。这些不是太重要,python是指你搜索的内容,比如我就是爬取的python相关的岗位。1.html是指你搜索的内容的第1页。
那么如果我们要查询在重庆市渝中区python相关的职位,那么需要的网址就是:
https://search.51job.com/list/060000,060100,0000,00,9,02,python,2,1.html
但是如果我们要找大数据相关的职位,网址就变成了:
https://search.51job.com/list/060000,060100,0000,00,9,99,%25E5%25A4%25A7%25E6%2595%25B0%25E6%258D%25AE,2,1.html
这里的%25E5%25A4%25A7%25E6%2595%25B0%25E6%258D%25AE就是指大数据三个字,这里对大数据进行了二次编码,代码:
def keyword(key):newkey = urllib.parse.quote(key) #%E5%A4%A7%E6%95%B0%E6%8D%AEnewkey1 = urllib.parse.quote(newkey) #二次编码,结果:%25E5%25A4%25A7%25E6%2595%25B0%25E6%258D%25AEreturn newkey1
那么就先来写主函数main():
def main():key = "python" #key是指要搜索的内容newkey = keyword(key)baseurl=r"https://search.51job.com/list/000000,000000,0000,00,9,99,"+newkey+",2,"endurl=".html"datalist=getData(baseurl,endurl)saveData(datalist)
在51job每页中有50条数据,要获取1000条,就需要拿到20页。一个具体的网页就是:
url=baseurl+str(pagenum)+endurl
那么先来解析一个网页:
def askUrl(url):head = {"User-Agent": "Mozilla / 5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 92.0.4515.159 Safari / 537.36"} # 用户代理,表示告诉51job服务器,我们是什么类型的机器,浏览器(本质上是告诉浏览器,我们可以接收什么水平的文件内容)request = urllib.request.Request(url, headers=head)html = ""try:response = urllib.request.urlopen(request)html = response.read().decode("gbk")#51job网页源码里面可以看到是用的gbk编码# print(html)except urllib.error.URLError as e:if hasattr(e, "code"):print(e.code)if hasattr(e, "reason"):print(e.reason)return html
这样我们就获取了一整个网页的内容,可以看一下这个html:
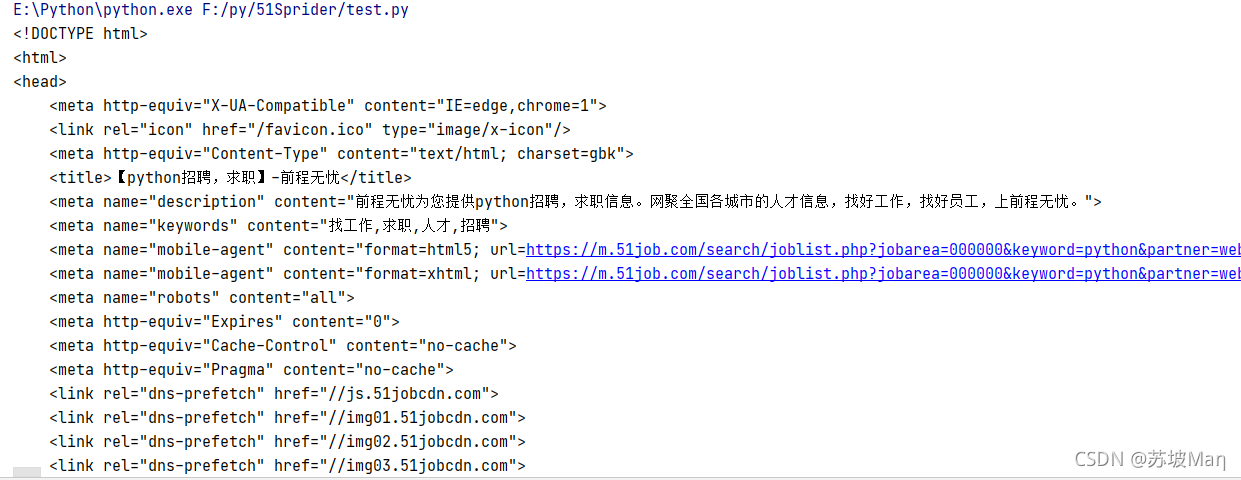
html中的内容很多,而我们要找到自己需要的职位信息,找一下,在script里面:


这样的数据一个html中有五十条,因此我们要获取这50多条数据的信息,怎么获取?使用正则表达式:
jobid = re.compile(r'"jobid":"(\d*)"')
coid=re.compile(r'"coid":"(\d*)"')
job_link=re.compile(r'"job_href":"(.*?)"')
job_name=re.compile(r'"job_name":"(.*?)"')
company_link=re.compile(r'"company_href":"(.*?)"')
company_name=re.compile(r'company_name":"(.*?)"')
salary=re.compile(r'providesalary_text":"(.*?)"')
companytype_text=re.compile(r'"companytype_text":"(.*?)"')
time=re.compile(r'"issuedate":"(\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2})"')
jobwelf=re.compile(r'"jobwelf":"(.*?)"')
attribute_text=re.compile(r'"attribute_text":\[(.*?)\]')
companysize=re.compile(r'"companysize_text":"(.*?)"')
我只需要这些数据,就只写了只写正则表达式。正则表达式可以去自己学习一下。
现在来获取数据:
def getData(baseurl,endurl):dataList=[]for pagenum in range(1,21):url=baseurl+str(pagenum)+endurl #完整的网页urlhtml=askUrl(url) #解析urlsoup=BeautifulSoup(html,"html.parser") #html解析item=soup.select('body script') #找到我们需要的数据的大致位置item=str(item) #soup.select()获取的数据是bs4.element.Tag类型,需要转成str类型item = re.sub(r"\\", "", item) #去掉item中的//jobid1 = re.findall(jobid, item)coid1 = re.findall(coid, item)jobname1=re.findall(job_name,item)job_link1 = re.findall(job_link, item)company_link1 = re.findall(company_link, item)company_name1 = re.findall(company_name,item)salary1 = re.findall(salary,item)companytype_text1 = re.findall(companytype_text,item)time1 = re.findall(time,item)jobwelf1 = re.findall(jobwelf,item)attribute_text1 = re.findall(attribute_text,item)for i in range(len(attribute_text1)):#去掉attribute_text里面的"和,attribute_text1[i] = re.sub(r'"',"",attribute_text1[i])attribute_text1[i] = re.sub(r',', " ", attribute_text1[i])companysize1 = re.findall(companysize,item)for i in range(50):data = []data.append(jobid1[i])data.append(coid1[i])data.append(job_link1[i])data.append(jobname1[i])data.append(company_link1[i])data.append(company_name1[i])data.append(salary1[i])data.append(companytype_text1[i])data.append(time1[i])data.append(jobwelf1[i])data.append(attribute_text1[i])data.append(companysize1[i])dataList.append(data)return dataList
一个data就是一条招聘信息,而dataList里面存储了所有的1000条data,可以看一下dataList里面的内容

现在已经获取到这一千条数据了,只需要把他们存入mysql数据库就行了。
初始化并创建一个数据库:
def init_db():conn=pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123456', db='51wang', charset='utf8')c=conn.cursor()sql='''create table job(id INTEGER primary key auto_increment,jobid numeric ,coid numeric ,job_link varchar(255),job_name varchar(255),company_link varchar(255),company_name varchar(255),salary varchar(255),companytype_text varchar(255),time1 DATETIME ,jobwelf varchar(255),attribute_text varchar(255),companysize varchar(255));'''c.execute(sql)conn.commit()conn.close()c.close()
插入数据:
def saveData(dataList):init_db()conn=pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123456', db='51wang', charset='utf8')c=conn.cursor()for data in dataList:# for index in range(len(data)):for i in range(len(data)):data[i] = "'"+data[i]+"'" #为每个数据元素加个'',进行数据库的插入print(data)sql='''insert into job(jobid,coid,job_link,job_name,company_link,company_name,salary,companytype_text,time1,jobwelf,attribute_text,companysize) values (%s)''' %",".join(data)print(sql)c.execute(sql)conn.commit()print("执行成功")c.close()conn.close()
好了就这样。
完整代码:
import pymysql
import re
from bs4 import BeautifulSoup
import urllib.request,urllib.error,urllib.parsejobid = re.compile(r'"jobid":"(\d*)"')
coid=re.compile(r'"coid":"(\d*)"')
job_link=re.compile(r'"job_href":"(.*?)"')
job_name=re.compile(r'"job_name":"(.*?)"')
company_link=re.compile(r'"company_href":"(.*?)"')
company_name=re.compile(r'company_name":"(.*?)"')
salary=re.compile(r'providesalary_text":"(.*?)"')
companytype_text=re.compile(r'"companytype_text":"(.*?)"')
time=re.compile(r'"issuedate":"(\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2})"')
jobwelf=re.compile(r'"jobwelf":"(.*?)"')
attribute_text=re.compile(r'"attribute_text":\[(.*?)\]')
companysize=re.compile(r'"companysize_text":"(.*?)"')def main():key = "python"newkey = keyword(key)baseurl=r"https://search.51job.com/list/000000,000000,0000,00,9,99,"+newkey+",2,"endurl=".html"datalist=getData(baseurl,endurl)print(datalist)# saveData(datalist)def keyword(key):newkey = urllib.parse.quote(key) #%E5%A4%A7%E6%95%B0%E6%8D%AEnewkey1 = urllib.parse.quote(newkey) #二次编码,结果:%25E5%25A4%25A7%25E6%2595%25B0%25E6%258D%25AEreturn newkey1def getData(baseurl,endurl):dataList=[]for pagenum in range(1,21):url=baseurl+str(pagenum)+endurlhtml=askUrl(url)soup=BeautifulSoup(html,"html.parser") #html解析item=soup.select('body script') #找到我们需要的数据的大致位置item=str(item) #soup.select()获取的数据是bs4.element.Tag类型,需要转成str类型item = re.sub(r"\\", "", item) #去掉item中的//jobid1 = re.findall(jobid, item)coid1 = re.findall(coid, item)jobname1=re.findall(job_name,item)job_link1 = re.findall(job_link, item)company_link1 = re.findall(company_link, item)company_name1 = re.findall(company_name,item)salary1 = re.findall(salary,item)companytype_text1 = re.findall(companytype_text,item)time1 = re.findall(time,item)jobwelf1 = re.findall(jobwelf,item)attribute_text1 = re.findall(attribute_text,item)for i in range(len(attribute_text1)):attribute_text1[i] = re.sub(r'"',"",attribute_text1[i])attribute_text1[i] = re.sub(r',', " ", attribute_text1[i])companysize1 = re.findall(companysize,item)for i in range(50):data = []data.append(jobid1[i])data.append(coid1[i])data.append(job_link1[i])data.append(jobname1[i])# print(jobname1[i])data.append(company_link1[i])data.append(company_name1[i])data.append(salary1[i])data.append(companytype_text1[i])data.append(time1[i])data.append(jobwelf1[i])data.append(attribute_text1[i])data.append(companysize1[i])dataList.append(data)return dataListdef saveData(dataList):init_db()conn=pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123456', db='51wang', charset='utf8')c=conn.cursor()for data in dataList:# for index in range(len(data)):for i in range(len(data)):data[i] = "'"+data[i]+"'"print(data)sql='''insert into job(jobid,coid,job_link,job_name,company_link,company_name,salary,companytype_text,time1,jobwelf,attribute_text,companysize) values (%s)''' %",".join(data)print(sql)c.execute(sql)conn.commit()print("执行成功")c.close()conn.close()def askUrl(url):head = {"User-Agent": "Mozilla / 5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 92.0.4515.159 Safari / 537.36"} # 用户代理,表示告诉豆瓣服务器,我们是什么类型的机器,浏览器(本质上是告诉浏览器,我们可以接收什么水平的文件内容)request = urllib.request.Request(url, headers=head)html = ""try:response = urllib.request.urlopen(request)html = response.read().decode("gbk")# print(html)except urllib.error.URLError as e:if hasattr(e, "code"):print(e.code)if hasattr(e, "reason"):print(e.reason)return htmldef save2db():returndef init_db():conn=pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123456', db='51wang', charset='utf8')c=conn.cursor()sql='''create table job(id INTEGER primary key auto_increment,jobid numeric ,coid numeric ,job_link varchar(255),job_name varchar(255),company_link varchar(255),company_name varchar(255),salary varchar(255),companytype_text varchar(255),time1 DATETIME ,jobwelf varchar(255),attribute_text varchar(255),companysize varchar(255));'''c.execute(sql)conn.commit()conn.close()c.close()if __name__ == '__main__':# html=askUrl("https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,1.html")# print(html)main()
其实获取到的job_link里面的网址可以获取到该职位更加详细的叙述。后面可以在写个函数进入这个网址再爬取数据。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!