爬取51job网站的数据分析
文章目录
- 爬取数据
- 岗位数据综合分析
- 读取所有岗位信息
- 合并数据
- 数据预处理
- 处理空值和缺失值
- 重复值处理
- 异常值处理
- 重置索引
- 绘制图表
- 图表数据准备
- 数据总揽
- 工作地区对于招聘情况的影响
- 工作经验对于招聘情况的影响
- 公司类型对于招聘情况的影响
- 学历对于招聘的影响
- 绘制词云
- 数据准备
- 封装jieba分词以及生成词云的函数
- 岗位要求词云
- 岗位福利词云
爬取数据
# -*- coding:utf-8 -*-
# @Time : 2020-11-10 20:57
# @Author : BGLB
# @Software : PyCharmimport csv
from decimal import Decimal
import hashlib
import json
import logging
import logging.config
import os
import random
import re
import time
from urllib import parsefrom lxml import html
from requests import getetree = html.etreeheaders = {"Host": "search.51job.com","User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3756.400 QQBrowser/10.5.4043.400",
}def time_logging(func):"""记录函数运行时间的装饰器:param func: 需要记录的函数名:return:"""def wrapper(*args, **kw):start_time = time.time()func_result = func(*args, **kw)runtime = time.time()-start_timeif runtime < 60:runtime = "{:.2f}s".format(runtime)elif runtime < 3600:runtime = "{:.2f}m".format(runtime/60)else:runtime = "{:.2f}h".format(runtime/3600)content = '[{0:^15}] - 运行时间 - [{1:^6}]'.format(func.__name__, runtime)# print(content)logging.info(content)with open("./log/runtime.log", 'a', encoding='utf8') as f:f.writelines(content+'\n')return func_resultreturn wrapperdef search_job(job_key, page_num=1):"""搜索上海 广州 深圳 武汉 四个城市的岗位信息一页有五十个岗位,"""url = "https://search.51job.com/list/020000%252C030200%252C040000%252C180200,000000,0000,00,9,99,{},2,{}.html"response = get(url.format(parse.quote(parse.quote(job_key)), page_num), headers=headers)html = response.content.decode(response.encoding)eroot = etree.HTML(html)table_list = eroot.xpath('//script[@type="text/javascript"]')# print(table_list[2].text)# print(table_list[2].text.split("=",1)[-1])json_str = json.loads(table_list[2].text.split("=", 1)[-1])return json_str@time_logging
def parse_job_msg(search_result):"""解析搜索到的岗位信息解析一个列表"""print("-------------正在解析第{}个页面数据--------------".format(search_result["curr_page"]))job_msg_list = search_result["engine_search_result"] # 一页50个岗位csv_list = []for job_msg in job_msg_list:# 工作idjobid = job_msg["jobid"]# 公司idcoid = job_msg["coid"]# 工作urljob_href = job_msg["job_href"]if job_href.split("/")[2].split(".")[0] == "jobs":job_detail_str = get_job_msg(job_href)else:pattern = re.compile(r'<[^>]+>', re.S)job_detail_str = pattern.sub('', get_51rz_json("job_detail", {"jobid": jobid}))# 工作名称job_name = job_msg["job_name"]# 公司urlco_href = job_msg["company_href"]# 公司名称co_name = job_msg["company_name"]# 薪资情况 处理成 最高 最低 平均值money = job_msg["providesalary_text"]# 工作地点workarea = job_msg["workarea_text"]# 公司类型co_type = job_msg["companytype_text"]# 发布时间update_time = job_msg["issuedate"]# 工作福利jobwelf = job_msg["jobwelf"]if money == "" or money is None:logging.error("{}的工作薪资{}获取失败".format(job_href, money))continue# 'attribute_text': ['上海-闵行区', '1年经验', '大专', '招2人']job_attr = job_msg["attribute_text"]job_po_tmp = job_year_tmp = ""job_education = "不限"for x in job_attr:if '招' in x:job_po_tmp = xif '经验' in x:job_year_tmp = xif x in "高中大专本科博士硕士":job_education = xpanter = re.compile(r'\d+')if len(panter.findall(job_po_tmp)) > 0:job_po = int(panter.findall(job_po_tmp)[0])else:job_po = 0if len(panter.findall(job_year_tmp)) > 0:job_year = int(panter.findall(job_year_tmp)[0])else:job_year = 0# 公司人数co_people = job_msg["companysize_text"]# 公司经营范围co_jx = job_msg['companyind_text']ss_s = money.split("-")if len(ss_s) < 2:money_min = money_max = 0else:money_min, money_max = parse_money(money)csv_dict = {"职位名称": job_name,"最低薪资(千/月)": money_min,"最高薪资(千/月)": money_max,"招聘人数": job_po,"工作经验(年)": job_year,"最低学历": job_education,"工作地点": workarea.split("-")[0],"工作福利": jobwelf,"职位描述和详细条件": job_detail_str,"公司名称": co_name,"公司类型": co_type,"公司人数": co_people,"公司经营范围": co_jx,"职位详情url": job_href,"公司详情url": co_href,"发布时间": update_time,}csv_list.append(csv_dict)return csv_listdef parse_money(money_text):money_min = money_max = 0ss_s = money_text.split("-")if len(ss_s) >= 2:money_min = Decimal(ss_s[0])money_max = Decimal(ss_s[1].split("/")[0][:-1])if money_text.split('/')[0][-1] == "万":money_min = 10*money_minmoney_max = 10*money_maxif money_text.split('/')[-1] == "年":money_max /= 12money_min /= 12return [money_min.quantize(Decimal("0.00")), money_max.quantize(Decimal("0.00"))]def init_params(oparams):"""通过对js的解析 复写出初始化查询参数的方法"""key = "tuD&#mheJQBlgy&Sm300l8xK^X4NzFYBcrN8@YLCret$fv1AZbtujg*KN^$YnUkh"keyindex = random.randint(4, 40)sParams = json.dumps(oparams)md5 = hashlib.md5()md5.update(("coapi"+sParams+str(key[keyindex:keyindex+15])).encode("utf8"))sign = md5.hexdigest()# print(md5.hexdigest())return {"key": keyindex,"sign": sign,"params": sParams}@time_logging
def get_51rz_json(interface: str, params: dict):"""针对对51rz.51job 的接口进行封装查询工作列表 job_list查询工作详情 job_detail {"jobid":126817691}查询公司列表 commpany_list查询公司详情 commpany_detail {"coid":}查询工作条件 job_condition查询工作时间表 job_time_table"""url_interface = {"job_list": "https://coapi.51job.com/job_list.php","job_detail": "https://coapi.51job.com/job_detail.php","commpany_list": "https://coapi.51job.com/co_list.php","commpany_detail": "https://coapi.51job.com/job_company.php","job_condition": "https://coapi.51job.com/job_condition.php", # 工作条件"job_time_table": "https://coapi.51job.com/job_schedule.php", # 工作时间表}header = {"Host": "coapi.51job.com","Referer": "https://51rz.51job.com/","User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36"}url = url_interface[interface]res = get(url, init_params(params), headers=header)# print(res.url)res_str = res.content.decode("utf8")filename = "{}".format(interface)for x in params.values():filename += str("_"+x)res_json = res_str.split("(", 1)[-1][0:-1]res_dict = dict(json.loads(res_json))res_dict["html_url"] = res.urlwrite_file(filename, "json", res_dict)# print(res_dict["resultbody"]["jobinfo"])return res_dict["resultbody"]["jobinfo"]@time_logging
def get_job_msg(job_detail_url):"""工作职位描述和详细条件"""try:job_detail_res = get(job_detail_url, headers=headers)html = job_detail_res.contenteroot = etree.HTML(html)job_name = eroot.xpath("/html/body/div[3]/div[2]/div[2]/div/div[1]/h1[1]/text()")[0]co_name = eroot.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[1]/a[1]/@title')[0]jobid = eroot.xpath('//*[@id="hidJobID"]/@value')[0]_content = eroot.xpath('//div[@class="tCompany_center clearfix"]//text()')except Exception as e:logging.error("解析[{}]-失败- {}".format(job_detail_url, e))return ""filename = "{0}-{1}-{2}".format(job_name, co_name,jobid).replace("(", "").replace(")", "").replace("/", "_").replace("*", "")# print(_content)# write_file(filename, "html", _content)# 工作职位描述和详细条件job_msg_str = eroot.xpath("//div[@class='bmsg job_msg inbox']/p/text()")# 简单的数据清洗for i in range(len(job_msg_str)):job_msg_str[i] = "".join(job_msg_str[i].split())return "".join(job_msg_str)def write_file(filename, fileext, datas):"""写入文件"""fileext_ignore = ["html", "log"] # 忽略输出的文件后缀if not os.path.exists("./data/{}".format(fileext)):os.makedirs("./data/{}".format(fileext))filenames = "{0}.{1}".format(filename, fileext).replace("/", "_").replace("\\", "_")filepath = "./data/{0}/{1}".format(fileext, filenames)is_write = os.path.exists(filepath)try:with open(filepath, 'a', encoding="utf8", newline="") as f:if fileext not in fileext_ignore:print("正在写入文件-[{0}].....".format(filenames))if fileext == "csv":if 'dict' in str(type(datas[0])):header = [x for x in datas[0].keys()]# print(type(header), header)# 提前预览列名,当下面代码写入数据时,会将其一一对应。writer = csv.DictWriter(f, fieldnames=header)if not is_write:writer.writeheader() # 写入列名writer.writerows(datas) # 写入数据elif 'list' in str(type(datas[0])):writer = csv.writer(f)writer.writerows(datas)else:csv.writer(f).writerows(datas)elif fileext == 'json':json.dump(datas, f, ensure_ascii=False)else:f.writelines(datas)if fileext not in fileext_ignore:print("[{}]-共写入{}条数据".format(filenames, len(datas)))logging.info("文件-[{0}]-写入成功,共有{1}条数据".format(filenames, len(datas)))except Exception as e:logging.error("文件-[{}]-写入出错:{},数据详情:数据{},数据长度{}".format(filenames, e, datas, len(datas)))@time_logging
def parse_key(key, pages=1):"""爬取并处理某一个关键字的岗位信息:param key: 关键字:param pages: 爬取页数:return:"""search_job_dict = search_job(key)try:total_page = int(search_job_dict["total_page"])except TypeError as e:total_page = 0print("不存在与{}相关的岗位,请尝试换个关键字".format(key))logging.error("不存在与{}相关的岗位,请尝试换个关键字,{}".format(key, e))print("----------------与{}相关的岗位一共有{}个页面----------------".format(key, total_page))if pages > total_page:pages = total_pagefor i in range(1, pages+1):try:job_json = search_job(key, i)job_data = parse_job_msg(job_json)write_file("{}_{}".format(key, i), "json", job_json)write_file(key+"相关岗位", "csv", job_data)except Exception as e:logging.error("处理-{}-第{}个页面时出错-{}".format(key, i, e))logging.info("{0}相关岗位信息爬取完毕!".format(key))@time_logging
def main(key_list, count):""":param key_list: 关键字列表:param count: 页码:return:"""logging_init("./config/logconfig.json")for key in key_list:print("-----------------开始搜索{}相关的岗位信息------------------".format(key))parse_key(key, count)rename_dir() # 为了下次还能够保存数据。更改data 文件夹的名称 为data_{当前的时间戳}print("列表关键字已爬取完毕!")logging.info("列表关键字已爬取完毕!")def rename_dir():if os.path.exists("./data"):try:os.rename("./data", "./data_{}".format(int(time.time())))except OSError as e:logging.error("{}更改文件夹名称无管理员权限".format(e))print("-------尝试更改data文件夹名称失败,请手动更改data文件夹名称-【防止下次爬取时数据重写】--------")def logging_init(path, default_level=logging.INFO):"""日志初始化:param path: 日志配置文件路径:param default_level: 如果没有日志配置 默认的日志等级:return:"""if not os.path.exists("./log"):os.makedirs("./log")if os.path.exists(path):# print("ri")with open(path, "r") as f:config = json.load(f)logging.config.dictConfig(config)logging.getLogger("runtime")else:logging.basicConfig(level=default_level)logging.info("{}不存在,使用默认的日志配置!".format(path))if __name__ == '__main__':keywords = ["python", "java", "c#", "web前端", "c/c++", "linux"]pages = 300main(keywords, pages)
岗位数据综合分析
读取所有岗位信息
import pandas as pd
data_dir = "data_1605456747"
data_read_python = pd.read_csv("./{}/csv/python相关岗位.csv".format(data_dir), encoding="utf8")
data_read_csharp = pd.read_csv("./{}/csv/c#相关岗位.csv".format(data_dir), encoding="utf8")
data_read_c = pd.read_csv("./{}/csv/c_c++相关岗位.csv".format(data_dir), encoding="utf8")
data_read_linux = pd.read_csv("./{}/csv/linux相关岗位.csv".format(data_dir), encoding="utf8")
data_read_java = pd.read_csv("./{}/csv/java相关岗位.csv".format(data_dir), encoding="utf8")
data_read_web = pd.read_csv("./{}/csv/web前端相关岗位.csv".format(data_dir), encoding="utf8")
data_read_python["岗位类型"] = "python"
data_read_csharp["岗位类型"] = "c#"
data_read_c["岗位类型"] = "c/c++"
data_read_linux["岗位类型"] = "linux"
data_read_java["岗位类型"] = "java"
data_read_web["岗位类型"] = "web"
合并数据
# 合并数据并删除重复值
data_sourse = pd.concat([data_read_c, data_read_csharp, data_read_java,data_read_linux, data_read_python, data_read_web]).drop_duplicates() len(data_sourse)
data_sourse.columns
Index(['职位名称', '最低薪资(千/月)', '最高薪资(千/月)', '招聘人数', '工作经验(年)', '最低学历', '工作地点','工作福利', '职位描述和详细条件', '公司名称', '公司类型', '公司人数', '公司经营范围', '职位详情url','公司详情url', '发布时间', '岗位类型'],dtype='object')
数据预处理
处理空值和缺失值
- 工作福利和职位描述都有缺失值或者存在空值 但不做处理 这些数据对于后期分析影响不大
# 查看是否有空值缺失值
data_sourse.isna()# 可以发现 工作福利和职位描述都有缺失值或者存在空值 但不做处理 这些数据对于后期分析影响不大
重复值处理
重复值在读取数据的时候已经处理过了
- 处理方法 :直接删除
- 原因 : 爬虫过程中数据重复写入的问题
异常值处理
- 由于学历 招聘岗位不同 影响了 薪资高低 所以不属于异常值
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif'] = ["SimHei"] # 防止画图中文乱码
plt.rcParams['axes.unicode_minus'] = False
%matplotlib inline
# data_scoure
# data_chart_warehouse = data_scoure.loc[:10,["最低薪资(千/月)","最高薪资(千/月)","招聘人数","工作经验(年)","最低学历","工作地点","公司类型"]]
abnormal_col = ["最低薪资(千/月)", "最高薪资(千/月)", "招聘人数", "工作经验(年)", ] # 可能出现异常数据的列
data_sourse.boxplot(abnormal_col) # 异常值箱型图
rule_drop = (data_sourse["最低薪资(千/月)"] ==0) | (data_sourse["最高薪资(千/月)"] == 0) # 需要删除的数据
data = data_sourse.drop(data_sourse[rule_drop].index, axis=0, inplace=False)
len(data)
70679
# 招聘人数 工作经验等与招聘情况有关, 因此不处理
data.boxplot(abnormal_col[0]) # 最低薪资异常值箱型图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W95R7K60-1606032463525)(https://blog.bglb.work/img/output_14_1.png?x-oss-process=style/blog_img)]
data.boxplot(abnormal_col[1]) # 最高薪资异常值箱型图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZOspDYSO-1606032463527)(https://blog.bglb.work/img/output_15_1.png?x-oss-process=style/blog_img)]
重置索引
data = data.reset_index()
data.boxplot(abnormal_col[:2])
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4diZNafO-1606032463530)(https://blog.bglb.work/img/output_23_0.png?x-oss-process=style/blog_img)]
绘制图表
图表数据准备
data_chart = data.loc[:, ["最低薪资(千/月)", "最高薪资(千/月)", "招聘人数", "工作经验(年)", "最低学历", "工作地点", "公司类型", "岗位类型", "发布时间"]]
len(data_chart)
70679
数据总揽
# 按学历分组 求每组的数据总量
chart_pie_data0 = data_chart.groupby("最低学历").count()
chart_pie_data1 = data_chart.groupby("公司类型").count()
chart_pie_data2 = data_chart.groupby("工作地点").count()
chart_pie_data3 = data_chart.groupby("岗位类型").count()fig, axes = plt.subplots(2, 2, figsize=(30, 15))
fig.patch.set_facecolor('#384151')
ax0 = axes[0, 0]
ax1 = axes[0, 1]
ax2 = axes[1, 0]
ax3 = axes[1, 1]ax0.pie(chart_pie_data0.iloc[:, 0], # 取出求得的每组的数据总量labels=chart_pie_data0.index,explode=[0 for x in range(len(chart_pie_data0.index))], # 设置每块的autopct='%3.1f%%', # 数值%pctdistance=0.7, textprops=dict(color='w', fontsize=15,), # 标签的字体labeldistance=1.1, # 锲形块标签的径向距离startangle=-0 # 初始角度)
ax0.set_title(label="学历要求占比图", loc='center', rotation=0, fontsize=20)
ax0.legend(labels=chart_pie_data0.index, loc="upper left", fontsize=15)ax1.pie(chart_pie_data1.iloc[:, 0],labels=chart_pie_data1.index,explode=[0.1, 0.5, 0.5, 0.3, 0, 0.8, 0.1, 0.1, 0.2, 0.1, 0.1],autopct='%3.1f%%',pctdistance=0.7,textprops=dict(color='w', fontsize=15,),startangle=-50)
ax1.set_title(label="公司类型占比图", loc='center', rotation=0, fontsize=20)
ax1.legend(loc="upper left", fontsize=10)ax2.pie(chart_pie_data2.iloc[:, 0],labels=chart_pie_data2.index,explode=[0 for x in range(len(chart_pie_data2.index))],autopct='%3.1f%%',pctdistance=0.7,textprops=dict(color='w', fontsize=20,),labeldistance=1.1, # 锲形块标签的径向距离startangle=-50)
ax2.set_title("工作地点占比图", loc='center', rotation=0, fontsize=20)
ax2.legend(loc="lower right", fontsize=13)ax3.pie(chart_pie_data3.iloc[:, 0],labels=chart_pie_data3.index,explode=[0 for x in range(len(chart_pie_data3.index))],autopct='%3.1f%%',pctdistance=0.7,textprops=dict(color='w', fontsize=20,),labeldistance=1.1, # 锲形块标签的径向距离startangle=-50)
ax3.set_title("岗位类型占比图", loc='center', rotation=0, fontsize=20)
ax3.legend(loc="lower right", fontsize=13)plt.show()
# len(chart_pie_data0.index)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7R3xRsOd-1606032463532)(https://blog.bglb.work/img/output_23_0.png?x-oss-process=style/blog_img)]](https://img-blog.csdnimg.cn/20201122161210747.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0JhbkdlbkxhbkJhaQ==,size_16,color_FFFFFF,t_70#pic_center)
#
chart_bar_data_area = data_chart.groupby("工作地点")chart_bar_data_area_gw = chart_bar_data_area.apply(lambda item: item.groupby("岗位类型").count())chart_bar_data_area_gs = chart_bar_data_area.apply(lambda item: item.groupby("公司类型").count())chart_bar_data_area_gz = chart_bar_data_area.apply(lambda item: item.groupby("岗位类型").mean())chart_bar_data_area_gz = (chart_bar_data_area_gz["最低薪资(千/月)"] + chart_bar_data_area_gz["最高薪资(千/月)"])/2# 初始化画布 设置背景颜色
fig, ax0 = plt.subplots(figsize=(40, 10))
fig.patch.set_facecolor('#384151')
fig, ax1 = plt.subplots(figsize=(40, 10))
fig.patch.set_facecolor('#384151')
fig, ax2 = plt.subplots(figsize=(40, 10))
fig.patch.set_facecolor('#384151')# 列索引转换行索引
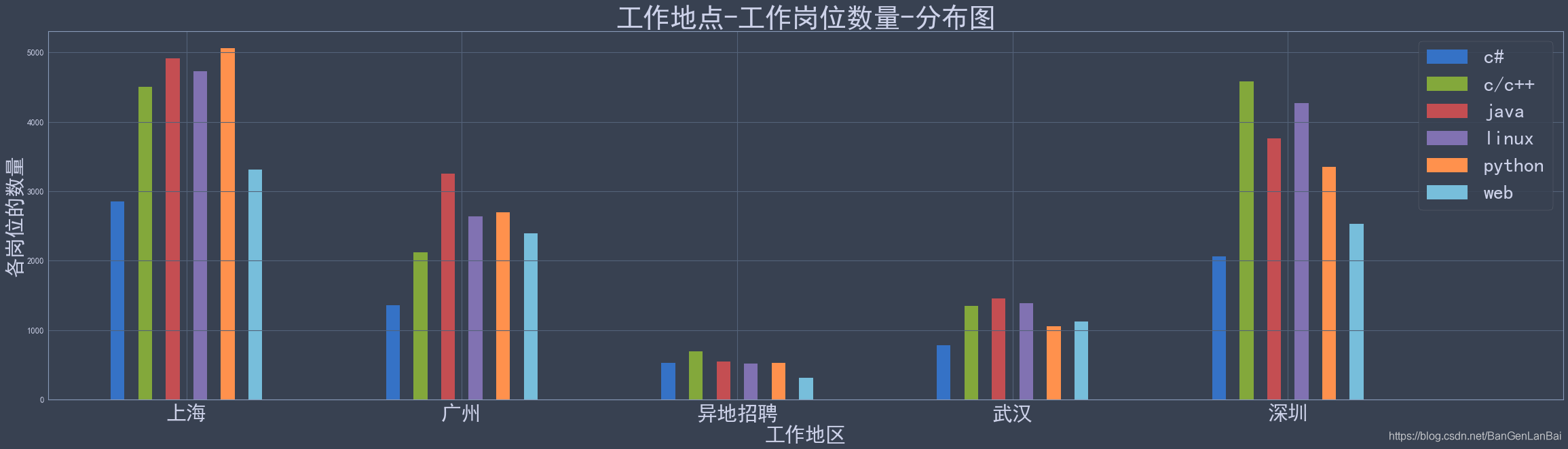
chart_bar_data_area_gw_count = chart_bar_data_area_gw.iloc[:, 1].unstack(level=1)
x = chart_bar_data_area_gw_count.index
y = chart_bar_data_area_gw_count.columns
x_index = [i for i in range(len(x))]
for j in y:for i in range(len(x)):x_index[i] += 0.1ax0.bar(x_index, chart_bar_data_area_gw_count[j], width=0.05, label=j)
ax0.legend(fontsize=30)
ax0.set_xticks([i+0.35 for i in range(len(x)+1)])
ax0.set_xticklabels(x, fontsize=30)
ax0.set_title(label="工作地点-工作岗位数量-分布图", loc='center', rotation=0, fontsize=40)
ax0.set_xlabel("工作地区", fontsize=30)
ax0.set_ylabel("各岗位的数量", fontsize=30)# 列索引转换行索引
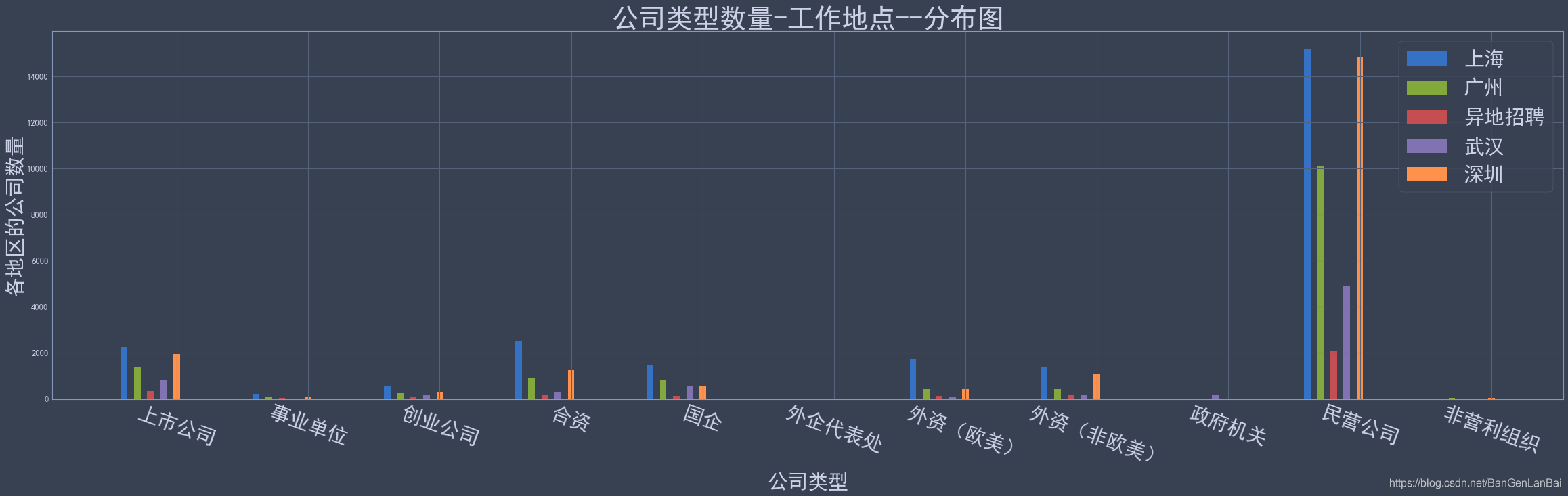
chart_bar_data_area_gs_count = chart_bar_data_area_gs.iloc[:, 1].unstack(level=1)
y = chart_bar_data_area_gs_count.index
x = chart_bar_data_area_gs_count.columns
x_index = [i for i in range(len(x))]
for j in y:for i in range(len(x)):x_index[i] += 0.1ax1.bar(x_index, chart_bar_data_area_gs_count.loc[j], width=0.05, label=j)
ax1.legend(fontsize=30)
ax1.set_xticks([i+0.5 for i in range(len(x))])
ax1.set_xticklabels(x, fontsize=30, rotation=-20)
ax1.set_xlabel("公司类型", fontsize=30)
ax1.set_ylabel("各地区的公司数量", fontsize=30)
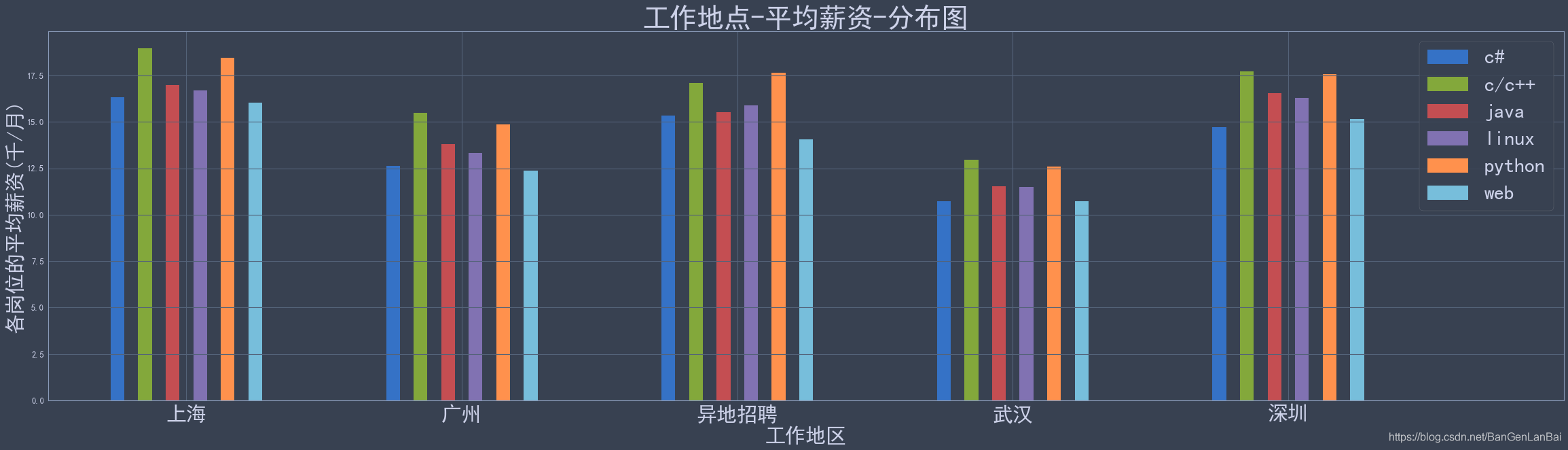
ax1.set_title(label="公司类型数量-工作地点--分布图", loc='center', rotation=0, fontsize=40)chart_bar_data_area_gz_mean = chart_bar_data_area_gz.unstack(level=1)
x = chart_bar_data_area_gz_mean.index
y = chart_bar_data_area_gz_mean.columns
x_index = [i for i in range(len(x))]
for j in y:for i in range(len(x)):x_index[i] += 0.1ax2.bar(x_index, chart_bar_data_area_gz_mean[j], width=0.05, label=j)
ax2.legend(y, fontsize=30)
ax2.set_xticks([i+0.35 for i in range(len(x)+1)])
ax2.set_xticklabels(x, fontsize=30)
ax2.set_xlabel("工作地区", fontsize=30)
ax2.set_ylabel("各岗位的平均薪资(千/月)", fontsize=30)
ax2.set_title(label="工作地点-平均薪资-分布图", loc='center', rotation=0, fontsize=40)plt.show()
# chart_bar_data_area_gz.unstack(level=1)
#
date_index = pd.to_datetime(data_chart.loc[:, "发布时间"].values)
# date_index = date_index
# date_index = data_chart.groupby("发布时间").mean()
chart_date_data = data_chart.set_index(date_index)
fig = plt.figure('', figsize=(20, 5))
fig.patch.set_facecolor('#384151')
plt.margins(0)
plt.title("时间-薪资--趋势图")
plt.plot(chart_date_data["最低薪资(千/月)"])
plt.plot(chart_date_data["最高薪资(千/月)"])
plt.legend(["最低薪资(千/月)", "最高薪资(千/月)"])
plt.xlabel("数据抓取时间")
plt.ylabel("薪资")
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dZ7oNu0E-1606032463535)(https://blog.bglb.work/img/output_25_0.png?x-oss-process=style/blog_img)]](https://img-blog.csdnimg.cn/20201122161314882.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0JhbkdlbkxhbkJhaQ==,size_16,color_FFFFFF,t_70#pic_center)
工作地区对于招聘情况的影响
data_group_area = data_chart.groupby("工作地点")
data_group_area_mean = data_group_area.mean()chart_name = "平均指标-地区-柱状图"
fig = plt.figure(chart_name, figsize=(20, 6))
fig.patch.set_facecolor('#384151')
plt.title(chart_name)
x = data_group_area_mean.index
y1 = data_group_area_mean["最低薪资(千/月)"]
y2 = data_group_area_mean["最高薪资(千/月)"]
y3 = data_group_area_mean["招聘人数"]
y4 = data_group_area_mean["工作经验(年)"]
plt.xlabel("工作地点")
plt.ylabel("平均数据")
width = 0.05plt.bar([i+0.1 for i in range(len(x))], y1, width=width)
plt.bar([i+0.2 for i in range(len(x))], y2, width=width)
plt.bar([i+0.3 for i in range(len(x))], y3, width=width)
plt.bar([i+0.4 for i in range(len(x))], y4, width=width)plt.legend(data_group_area_mean.columns, loc="upper right")
plt.xticks([i+.25 for i in range(len(x)+1)], x)plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fHXVuked-1606032463536)(https://blog.bglb.work/img/output_27_0.png?x-oss-process=style/blog_img)]](https://img-blog.csdnimg.cn/20201122161342270.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0JhbkdlbkxhbkJhaQ==,size_16,color_FFFFFF,t_70#pic_center)
工作经验对于招聘情况的影响
data_group_bg = data_chart.groupby("工作经验(年)")
data_group_bg_mean = data_group_bg.mean()fig = plt.figure('', figsize=(20, 10))
fig.patch.set_facecolor('#384151')
chart_name = "工作经验-线型图"
plt.title(chart_name)
x = data_group_bg_mean.index
y1 = data_group_bg_mean["最低薪资(千/月)"]
y2 = data_group_bg_mean["最高薪资(千/月)"]
y3 = data_group_bg_mean["招聘人数"]
plt.xlabel("工作经验(年)")
plt.ylabel("平均指标")
plt.plot(x, y1)
plt.plot(x, y2)
plt.plot(x, y3)plt.legend(data_group_area_mean.columns, loc="upper right")
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Zd00OBOo-1606032463536)(https://blog.bglb.work/img/output_29_0.png?x-oss-process=style/blog_img)]](https://img-blog.csdnimg.cn/20201122161354490.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0JhbkdlbkxhbkJhaQ==,size_16,color_FFFFFF,t_70#pic_center)
公司类型对于招聘情况的影响
# 通过公司类型进行分组 然后求每组平均值
data_group_gs = data_chart.groupby("公司类型").mean()chart_name = "公司类型-柱状图"
fig = plt.figure(chart_name, figsize=(20, 8))
fig.patch.set_facecolor('#384151')
plt.title(chart_name)
x = data_group_gs.index
y1 = data_group_gs["最低薪资(千/月)"]
y2 = data_group_gs["最高薪资(千/月)"]
y3 = data_group_gs["招聘人数"]
y4 = data_group_gs["工作经验(年)"]
plt.xlabel("公司类型")
plt.ylabel("平均指标")
width = 0.05plt.bar([i+0.1 for i in range(len(x))], y1, width=width)
plt.bar([i+0.2 for i in range(len(x))], y2, width=width)
plt.bar([i+0.3 for i in range(len(x))], y3, width=width)
plt.bar([i+0.4 for i in range(len(x))], y4, width=width)plt.legend(data_group_area_mean.columns, loc="upper right")
plt.xticks([i+.25 for i in range(len(x)+1)], x)
# plt.savefig("./test.png")
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hI0MqFcC-1606032463537)(https://blog.bglb.work/img/output_31_0.png?x-oss-process=style/blog_img)]](https://img-blog.csdnimg.cn/20201122161411232.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0JhbkdlbkxhbkJhaQ==,size_16,color_FFFFFF,t_70#pic_center)
学历对于招聘的影响
data_group_bg = data_chart.groupby("最低学历").mean()chart_name = "学历-柱状图"
fig = plt.figure(chart_name, figsize=(20, 8))
fig.patch.set_facecolor('#384151')
plt.title(chart_name)
x = data_group_bg.index
y1 = data_group_bg["最低薪资(千/月)"]
y2 = data_group_bg["最高薪资(千/月)"]
y3 = data_group_bg["招聘人数"]
y4 = data_group_bg["工作经验(年)"]
plt.xlabel("学历")
plt.ylabel("平均指标")
width = 0.05plt.bar([i+0.1 for i in range(len(x))], y1, width=width)
plt.bar([i+0.2 for i in range(len(x))], y2, width=width)
plt.bar([i+0.3 for i in range(len(x))], y3, width=width)
plt.bar([i+0.4 for i in range(len(x))], y4, width=width)plt.legend(data_group_area_mean.columns, loc="upper right")
plt.xticks([i+.25 for i in range(len(x)+1)], x)
# plt.savefig("./test.png")
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0Obhrrme-1606032463538)(https://blog.bglb.work/img/output_33_0.png?x-oss-process=style/blog_img)]](https://img-blog.csdnimg.cn/20201122161426795.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0JhbkdlbkxhbkJhaQ==,size_16,color_FFFFFF,t_70#pic_center)
绘制词云
数据准备
data_word = data[["职位名称","职位描述和详细条件", "工作福利"]]
data_word = data_word.dropna()
data_word
封装jieba分词以及生成词云的函数
#
from wordcloud import WordCloud
import jieba
import redef parse_text(text_list):"""1.通过正则表达式删除数字标点符号空格回车 2.删除停用词"""re_list = [re.compile(r"[^a-zA-Z]\d+"), re.compile(r"\s+"),re.compile(r"[^0-9A-Za-z\u4e00-\u9fa5]")]for reg in re_list:text = reg.sub("", "".join(text_list))return textdef stopwordslist(filepath):"""读取无意义词汇-(停用词列表)"""stopwords = [line.strip() for line in open(filepath, 'r', encoding="utf8").readlines()]return stopwordsdef seg_sentence(sentence, ignorelist):"""删除停用词 返回切割后的str"""stopwords = stopwordslist('./baidu_tingyong.txt')for stop in stopwords+ignorelist:sentence = sentence.replace(stop, "")outstr = ''sentence_seged = jieba.cut(sentence.strip())for word in sentence_seged:if word != '\t':outstr += wordoutstr += " "return outstrdef cut_words(text_list, ignore_list=[]):text = list(set(text_list))return seg_sentence(parse_text(text), ignore_list)def word_img(cut_words, title, ignorelist):fig = plt.figure("", figsize=(15, 10))fig.patch.set_facecolor('#384151')wordcloud = WordCloud(font_path="./fonts/simkai.ttf", # 字体的路径width=1000, height=600, # 设置宽高background_color='white', # 图片的背景颜色# max_font_size=100,# min_font_size=20,# max_words=300,# font_step=2,stopwords={x for x in ignorelist})plt.title(title, fontsize=20)plt.imshow(wordcloud.generate(cut_words), interpolation='bilinear')plt.axis("off")岗位要求词云
text_dec = data_word["职位描述和详细条件"].values
# 自定义停用词
ignore_dec_list = ["工作", "能力", "开发", "熟悉", "优先", "精通", "熟练", "优先", "负责", "公司", "岗位职责", "用户", "技术", "沟通""软件", "以上", "学历", "专业", "产品", "计算机", "项目", "具备", "相关", "服务", "研发", "管理", "参与", "精神","分析", "岗位", "理解", "需求", "独立", "解决", "业务", "文档", "数据", "编写", "大专", "本科", "团队", "合作", "科","上", "协调", "详细", "设计", "职", "求", "基础", "扎实", "模块", "系统", "学习", "工", "具", "平台", "知识","包括", "压力", "内容", "研究", "周末", "双", "休", "软件", "描述", "国家", "节假日", "法定", "方法", "主流","于都", "年", "验", "控制", "流程"]
text_dec = cut_words(text_dec, ignore_dec_list)
Building prefix dict from the default dictionary ...
Loading model from cache F:\bglb\AppData\Temp\jieba.cache
Loading model cost 0.800 seconds.
Prefix dict has been built successfully.
ignorelist = ["流程", "程序", "大", "数", "库"]
word_img(text_dec, "岗位要求词云", ignorelist)

岗位福利词云
text_fl = data_word["工作福利"].values
text_fl = cut_words(text_fl)
ignorelist = ["定期", "工作"]
word_img(text_fl, "岗位福利词云", ignorelist)

text_name = data_word["职位名称"].values
text_name = cut_words(text_name)
word_img(text_name, "职位名称词云",[])

蓝白社区 欢迎您的加入
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!