Winner or Loser -------李宏毅机器学习HW2
作业说明
数据:train.csv test.csv correct_answer.csv
资料:github李宏毅作业
收集到一些美国人的年龄、学历、地区等资料给你,如果是训练集,会在同一个csv中以‘income’告诉你这些人的工资收入是否超过50K。如果是测试集,工资收入会在correct_answer中,以Label形式告诉你是否为“ >50K”。

我们要做的是,通过人的14项基本信息,预测他的工资是否上50K,从而判断他是WInner or Loser。
数据清洗
我们在拿到数据的时候,其实可以看到数据集中有缺少的数据(在表格中以‘?’代替的数据)。如图,我们可以直接删除此行数据,这种方式叫做数据清洗。

但是如果在训练集中我们进行了数据清洗,其'income'的同时删去,对训练没有坏的影响。但是在测试集中也有数据不全的部分,如果我们对test清洗了,那么在test的人数会变少,就无法对于correct_answer中的答案。所以我们可以将test、correct_answer合并之后再做清洗。
数据分析
在机器学习中,我们能直接处理的都是数字,现在首要问题是将这些数据都转换成一个个数值。我们该如何处理呢?先把表格中是数字、是字符的区分开吧,分为A数据集与B数据集。
在B数据集中我们发现 'sex' 和 ‘income’ 这两列都只有两种结果,直接布尔化处理。
trainData['sex'] = (trainData['sex'] == 'male')trainData['income'] = (trainData['income'] == ' >50K')但是B数据集中其他数据我们就需要使用一个特别的函数,pd.get_dummies(B数据集)。这个函数的具体介绍参考:特征提取之pd.get_dummies()。
这里我们简略的解释一下,pd.get_dummies()就是将离散型特征的每一种取值都看成一种状态,若你的这一特征中有N个不相同的取值,那么我们就可以将该特征抽象成N种不同的状态,one-hot编码保证了每一个取值只会使得一种状态处于“激活态”,也就是说这N种状态中只有一个状态位值为1,其他状态位都是0。
B = pd.get_dummies(B) # 处理非字符的数据集trainData = pd.concat([A, B], axis=1) # 将数据集A、B连接起来
在执行代码之后,我们发现原先为15列的trainData变成了100多列。这就是pd.get_dummies()导致的。他将一列的不同值也转变成了单独的一列。我们可以从下图看到,这是我中途保存的csv。

这样的数据我们还不能直接使用,因为此案例中,训练的列数会比测试的列数多一列:native_country_ Holand-Netherlands。我们要把此列删除,使测试时参数数目对应。
trainData = trainData.drop(['native_country_ Holand-Netherlands'], axis=1).values
训练
我们使用Logistic Regression逻辑回归设想这个问题。Logistic Regression和Linear Regression的差别主要在前者的输出范围是0-1,后者是任何值。我们可以这样理解,其实Logistict Regression就是将Linear Regression的公式外面再套一个函数,导致其输出在0-1之间。具体推导可以看李宏毅的机器学习视频。

| 
|
由图右可知,我们先求出u1, u2, E1, E2(由E1, E2有权相加,得到E)。由于我不会打公式,都直接上图吧。u与E的公式如下: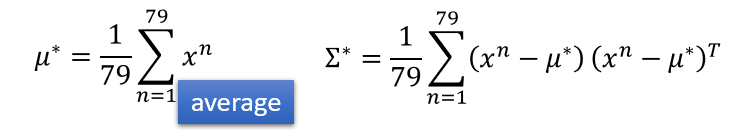 。79是逻辑回归的两分类中一份分类的数目,各自u、E的数目不一样的。
。79是逻辑回归的两分类中一份分类的数目,各自u、E的数目不一样的。
此公式的训练代码
def g_train(X, Y):# 我们需要u1, u2, E1, E2来计算 z=w*x+b的w、bnum = X.shape[0]cnt1 = 0cnt2 = 0sum1 = np.zeros((X.shape[1],)) # (101,)sum2 = np.zeros((X.shape[1],))for i in range(num):if Y[i] == 1:sum1 += X[i]cnt1 += 1else:sum2 += X[i]cnt2 += 1u1 = sum1 / cnt1u2 = sum2 / cnt2 # 找到了平均值E1 = np.zeros((X.shape[1], X.shape[1])) # (101, 101)E2 = np.zeros((X.shape[1], X.shape[1])) # (101, 101)for i in range(num):if Y[i] == 1:# E1 += np.dot(X[i] - u1, (X[i] - u1).T)E1 += np.dot(np.transpose([X[i] - u1]), [X[i] - u1])else:# E2 += np.dot(X[i] - u2, (X[i] - u2).T)E2 += np.dot(np.transpose([X[i] - u2]), [X[i] - u2])E1 = E1 / float(cnt1)E2 = E2 / float(cnt2)E = E1 * (float(cnt1) / num) + E2 * (float(cnt2) / num)# print ('findParams_U1', u1.shape, u1)# print ('findParams_U2', u2.shape, u2)# print ('findParams_E', E.shape, E)return u1, u2, E, cnt1, cnt2此公式的训练代码
def g_pridict(X, Y, u1, u2, E, N1, N2):E_inv = inv(E) # 居然碰到奇异矩阵的问题w = np.dot((u1 - u2), E_inv)b = (-0.5) * np.dot(np.dot(u1.T, E_inv), u1) + (0.5) * np.dot(np.dot(u2.T, E_inv), u2) + np.log(float(N1)/N2)z = np.dot(w, X.T) + by = sigmoid(z)cnt1 = 0cnt2 = 0y = np.around(y)for i in range(Y.shape[0]):if y[i] == Y[i]:cnt1 += 1else:cnt2 += 1print ('[Generative]测试数据共', Y.shape[0], '个,判断正确', cnt1, '个,判断错误', cnt2, '个')print ('准确率:', float(cnt1) / Y.shape[0]*100, '%')return y剩下我还使用了mini-batch SGD、Discriminative方式。效果如下:
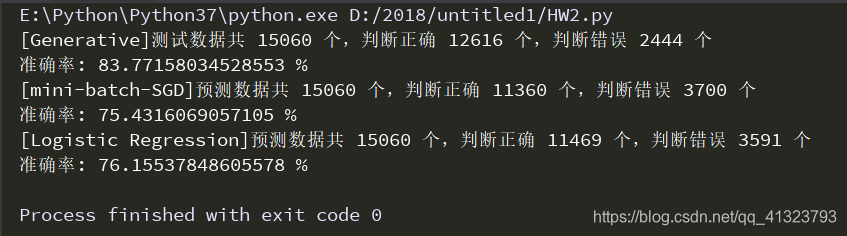
所有代码
#coding=utf-8
import numpy as np
from random import shuffle
from numpy.linalg import inv
from math import floor, log
import matplotlib.pyplot as plt
import os
import argparse
import pandas as pddir = 'F:/machine/HW2/data'
def washData(pathData, pathAnswer='Nothing'):# 14个属性+收入属性# 数据清洗df_x = pd.read_csv(pathData)# 在执行清洗之前,合并数据和答案,方便将行数据对应清洗if(pathAnswer != 'Nothing'): # 表示是测试数据,真的有pathAnswerdf_ans = pd.read_csv(pathAnswer)df_x = pd.concat([df_x, df_ans['label']], axis=1) # 注意训练集里面列名是'income', 这里是'label'df_x.rename(columns={'label': 'income'}, inplace=True) # label -> incomeelse :df_x['income'] = (df_x['income'] == ' >50K')df_x = df_x.replace(' ?', np.nan) # 将数据中存在'?'的行用NAN替代df_x = df_x.dropna() # 将含有NAN的行删除# 修改性别项 和 分离income项df_x['sex'] = (df_x['sex'] == 'male')data_y = df_x[['income']].astype(np.int64) # df_x[[]]两重括号才能保持其DataFrame属性, 一重括号data_y变成Series属性del df_x['income']# 将数据分成数字和非数字 两部分object_columns = [col for col in df_x.columns if df_x[col].dtypes == "object"] # 陷阱:in df.columns可以,in range(df.columns)不行no_object_columns = [col for col in df_x.columns if df_x[col].dtypes == 'int64']object_data = df_x[object_columns]no_object_data = df_x[no_object_columns]# set every element in object rows as an attributeobject_data = pd.get_dummies(object_data) # 走到这一步其实很多列映射的值都一样# 将数字部分和非数字部分都合并起来,还是我们的数据集data_x = pd.concat([no_object_data, object_data], axis=1)data_x = data_x.astype(np.int64)# 数据都变成了一些数字data_x = (data_x - data_x.mean()) / data_x.std()if pathAnswer == 'Nothing': # 对比train.csv和test.csv发现如下项对应不了,故train.csv中获取的此元素删掉del data_x['native_country_ Holand-Netherlands']return data_x.values, data_y.values # 分别为14列、1列 # 这.values是陷阱啊!!!没有要不得,findParams会取不出数字的def sigmoid(z):z = 1 / (1.0 + np.exp(-z))return zdef g_train(X, Y):# 我们需要u1, u2, E1, E2来计算 z=w*x+b的w、bnum = X.shape[0]cnt1 = 0cnt2 = 0sum1 = np.zeros((X.shape[1],)) # (101,)sum2 = np.zeros((X.shape[1],))for i in range(num):if Y[i] == 1:sum1 += X[i]cnt1 += 1else:sum2 += X[i]cnt2 += 1u1 = sum1 / cnt1u2 = sum2 / cnt2 # 找到了平均值E1 = np.zeros((X.shape[1], X.shape[1])) # (101, 101)E2 = np.zeros((X.shape[1], X.shape[1])) # (101, 101)for i in range(num):if Y[i] == 1:# E1 += np.dot(X[i] - u1, (X[i] - u1).T)E1 += np.dot(np.transpose([X[i] - u1]), [X[i] - u1])else:# E2 += np.dot(X[i] - u2, (X[i] - u2).T)E2 += np.dot(np.transpose([X[i] - u2]), [X[i] - u2])E1 = E1 / float(cnt1)E2 = E2 / float(cnt2)E = E1 * (float(cnt1) / num) + E2 * (float(cnt2) / num)# print ('findParams_U1', u1.shape, u1)# print ('findParams_U2', u2.shape, u2)# print ('findParams_E', E.shape, E)return u1, u2, E, cnt1, cnt2def g_pridict(X, Y, u1, u2, E, N1, N2):E_inv = inv(E) # 居然碰到奇异矩阵的问题w = np.dot((u1 - u2), E_inv)b = (-0.5) * np.dot(np.dot(u1.T, E_inv), u1) + (0.5) * np.dot(np.dot(u2.T, E_inv), u2) + np.log(float(N1)/N2)z = np.dot(w, X.T) + by = sigmoid(z)cnt1 = 0cnt2 = 0y = np.around(y)for i in range(Y.shape[0]):if y[i] == Y[i]:cnt1 += 1else:cnt2 += 1print ('[Generative]测试数据共', Y.shape[0], '个,判断正确', cnt1, '个,判断错误', cnt2, '个')print ('准确率:', float(cnt1) / Y.shape[0]*100, '%')return ydef sgd_train(X, Y, batchSize=300, eta=0.0001, lambdaL2=0.0): # 用梯度求这个,是错误方向?w = np.zeros(X.shape[1]) # (101, )b = 0.0list_cost = []for i in range(0, X.shape[0] // batchSize * batchSize, batchSize):batch = X[i:i + batchSize, :] # (30, 101)y_ = np.squeeze(Y[i: i + batchSize]) # 这个函数是针对 np.dot的。hypo = np.dot(batch, w) # 按公式获取了预测值, 结果是(30, )hypo = np.around(hypo) # 上行算出来的是小数,我们要二分类loss = hypo - y_ # (30, )cost = np.sum(loss**2) / (2.0 * batchSize)list_cost.append(cost)grad = np.sum(np.dot(loss.T, batch)) / batchSizelambdaL2 = np.sum(loss) / batchSizew = w - eta * gradb = b - eta * lambdaL2# print (list_cost) # 并没有逐渐变小的结果return w, bdef sgd_predict(X, Y, w, b):y = np.dot(X, w) + b# y = sigmoid(y)y = np.around(y)cnt1 = 0cnt2 = 0for i in range(Y.shape[0]):if y[i] == Y[i]:cnt1 += 1else:cnt2 += 1print ('[mini-batch-SGD]预测数据共', Y.shape[0], '个,判断正确', cnt1, '个,判断错误', cnt2, '个')print ('准确率:', float(cnt1) / Y.shape[0] * 100, '%')def lr_train(X, Y, batchSize=300, eta=0.001, lambdaL2=0.0):# 使用最大似然函数求解w = np.zeros(X.shape[1])b = 0.0list_cost = []for i in range(0, X.shape[0] // batchSize * batchSize, batchSize):batch = X[i:i + batchSize, :] # (30, 101)y_ = np.squeeze(Y[i: i + batchSize])z = np.dot(batch, w) + by = sigmoid(z)loss = y - y_# 计算交叉熵, 由于是矩阵(,101)*(101,)=标量,所以巧妙求和了cross_entropy = (-1) * (np.dot(y_.T, np.log(y)) + np.dot((1 - y_.T), np.log(1 - y))) # 存在log(0)的情况list_cost.append(cross_entropy)w = w - eta * np.dot(batch.T, loss)b = b - eta * (np.sum(loss) / batchSize)return w, bdef lr_pridect(X, Y, w, b):z = np.dot(X, w) + by = sigmoid(z)y = np.around(y)cnt1 = 0cnt2 = 0for i in range(Y.shape[0]):if y[i] == Y[i]:cnt1 += 1else :cnt2 += 1print ('[Logistic Regression]预测数据共', Y.shape[0], '个,判断正确', cnt1, '个,判断错误', cnt2, '个')print ('准确率:', float(cnt1) / Y.shape[0] * 100, '%')trainX, trainY = washData(dir+'/train.csv') # trainX是DataFrame(30162, 101) (30162,)
testX, testY = washData(dir+'/test.csv', dir+'/correct_answer.csv') # (15060, 101) (15060,)# Generative 公式的方法
u1, u2, E, N1, N2 = g_train(trainX, trainY)
my_ans = g_pridict(testX, testY, u1, u2, E, N1, N2)
np.savetxt(dir+'/my_ans_1.csv', my_ans)# mini_batch SGD 这个方向是低正确率的
w, b = sgd_train(trainX, trainY)
sgd_predict(testX, testY, w, b)#
w, b = lr_train(trainX, trainY)
lr_pridect(testX, testY, w, b)总结
此次学习,重点在数据分析,这方面学到了很多,能一个函数处理原始训练数据、原始测试数据与其答案。现在自己在提升准确率方面还很单纯,不了解该怎么做,每次只有跟着公式敲敲打打;对于矩阵相乘方面,还没有掌握于心,容易犯迷糊。在写博客时,自己虽想讲得清楚明白,但心中没有讲解需要的诚恳,这是自己博客的很大缺失,希望改进。
下面是我对助教的代码的注释,大家可以参考一下:
#coding=utf-8
import numpy as np
from random import shuffle
from numpy.linalg import inv
from math import floor, log
import os
import argparse
import pandas as pdoutput_dir = "output/"def dataProcess_X(rawData):# sex 只有两个属性 先drop之后处理if "income" in rawData.columns: # if in 是训练集Data = rawData.drop(["sex", 'income'], axis=1)else: # 是测试集Data = rawData.drop(["sex"], axis=1)listObjectColumn = [col for col in Data.columns if Data[col].dtypes == "object"] #读取非数字的columnlistNonObjedtColumn = [x for x in list(Data) if x not in listObjectColumn] #数字的columnObjectData = Data[listObjectColumn]NonObjectData = Data[listNonObjedtColumn]#insert set into nonobject data with male = 0 and female = 1NonObjectData.insert(0 ,"sex", (rawData["sex"] == " Female").astype(np.int))#set every element in object rows as an attribute# print('编码前:', ObjectData) -------------------ObjectData = pd.get_dummies(ObjectData)# print('编码后:', ObjectData) -------------------Data = pd.concat([NonObjectData, ObjectData], axis=1) # 列相连接、并列# print('列名:', Data.columns) # 原本数字的在前,字符的在后,sex是第一个Data_x = Data.astype("int64")# Data_y = (rawData["income"] == " <=50K").astype(np.int)#normalize# pandas.std() 计算的是样本标准偏差,默认ddof = 1。如果我们知道所有的分数,那么我们就有了总体# ——因此,要使用 pandas 进行归一化处理,我们需要将“ddof”设置为 0。Data_x = (Data_x - Data_x.mean()) / Data_x.std() # pandas.mean()求每一列自己的平均值## 保存数字型数据,通过分析此文件,发现它将原来列属性中不同的值分成了新的列。所以文件的列数激增。# if "income" in rawData.columns:# Data_x.to_csv('F:/machine/HW2/dta/train_num_data.csv')# 疑惑,目前没有进行数据清洗,即数据不全处。return Data_xdef dataProcess_Y(rawData):df_y = rawData['income'] # 太帅了这个用法, 并且使用的时候我们可以不转换为数组Data_y = pd.DataFrame((df_y==' >50K').astype("int64"), columns=["income"])return Data_ydef sigmoid(z):res = 1 / (1.0 + np.exp(-z)) # 整体的函数return np.clip(res, 1e-8, (1-(1e-8))) # (输入的数组,限定的最小值,限定的最大值)def _shuffle(X, Y): #X and Y are np.arrayrandomize = np.arange(X.shape[0]) # [0-32561)np.random.shuffle(randomize) # 洗牌,打乱顺序return (X[randomize], Y[randomize])def split_valid_set(X, Y, percentage):all_size = X.shape[0] # 32561valid_size = int(floor(all_size * percentage)) # 3256X, Y = _shuffle(X, Y) # 将数据打乱# 将数据分成 percentage: 1-percentage两部分X_valid, Y_valid = X[ : valid_size], Y[ : valid_size]X_train, Y_train = X[valid_size:], Y[valid_size:]return X_train, Y_train, X_valid, Y_validdef valid(X, Y, mu1, mu2, shared_sigma, N1, N2):sigma_inv = inv(shared_sigma) # 矩阵求逆w = np.dot((mu1-mu2), sigma_inv)X_t = X.Tb = (-0.5) * np.dot(np.dot(mu1.T, sigma_inv), mu1) + (0.5) * np.dot(np.dot(mu2.T, sigma_inv), mu2) + np.log(float(N1)/N2)a = np.dot(w,X_t) + b # 唉,弄了半天,代码没有问题,只不过w在PPT上用的是wT这个名字,但是意义是一样的。y = sigmoid(a) # a就是线性里面的y了,在逻辑回归里面只不过套了哥函数,将其分布改成0-1之间y_ = np.around(y) # 四舍五入的值,即二分类# squeeze()将维度里面为1的值维度去掉。Y(3256,1) y_(3256,)result = (np.squeeze(Y) == y_) # result(3256,) [true or false]# 我训练集的前半部分得出的函数,对后半部分的测试成功率print('Valid acc = %f' % (float(result.sum()) / result.shape[0]))returndef train(X_train, Y_train):# vaild_set_percetange = 0.1# X_train, Y_train, X_valid, Y_valid = split_valid_set(X, Y, vaild_set_percetange)#Gussian distribution parameterstrain_data_size = X_train.shape[0]cnt1 = 0cnt2 = 0mu1 = np.zeros((X_train.shape[1],))mu2 = np.zeros((X_train.shape[1],))for i in range(train_data_size):if Y_train[i] == 1: # >50kmu1 += X_train[i]cnt1 += 1else:mu2 += X_train[i]cnt2 += 1mu1 /= cnt1 # 均值Umu2 /= cnt2sigma1 = np.zeros((X_train.shape[1], X_train.shape[1])) # (106,106)sigma2 = np.zeros((X_train.shape[1], X_train.shape[1]))for i in range(train_data_size):if Y_train[i] == 1:# sigma1 += np.dot(np.transpose([X_train[i] - mu1]), [X_train[i] - mu1]) # 分布∑1 # 公式有误??sigma1 += np.dot(np.transpose([X_train[i] - mu1]), [X_train[i] - mu1]) # 分布∑1 # 公式有误??else:sigma2 += np.dot(np.transpose([X_train[i] - mu2]), [X_train[i] - mu2]) # 分布∑2sigma1 /= cnt1sigma2 /= cnt2shared_sigma = (float(cnt1) / train_data_size) * sigma1 + (float(cnt2) / train_data_size) * sigma2 # 分布∑N1 = cnt1N2 = cnt2return mu1, mu2, shared_sigma, N1, N2 # 现在将公式的参数全部求出了if __name__ == "__main__":trainData = pd.read_csv("F:/machine/HW2/data/train.csv") # 第一行会作为列名 (32561,15)testData = pd.read_csv("F:/machine/HW2/data/test.csv") # (16281,14)没有数据ans = pd.read_csv("F:/machine/HW2/data/correct_answer.csv") # (16281, 2) 2 = id + label#here is one more attribute in trainData# 删除训练集中 有['native_country_ Holand-Netherlands']的那一列, 因为测试集里面无此国家项,即无此列x_train = dataProcess_X(trainData).drop(['native_country_ Holand-Netherlands'], axis=1).values # (32561,107-1)x_test = dataProcess_X(testData).values # (16281,106)y_train = dataProcess_Y(trainData).values # (32561,1)y_ans = ans['label'].values # (16281,)if 达到50K then 1 else 0 answer for testvaild_set_percetage = 0.1X_train, Y_train, X_valid, Y_valid = split_valid_set(x_train, y_train, vaild_set_percetage) # 返回的是打乱了、分割了的数据mu1, mu2, shared_sigma, N1, N2 = train(X_train, Y_train)valid(X_valid, Y_valid, mu1, mu2, shared_sigma, N1, N2)mu1, mu2, shared_sigma, N1, N2 = train(x_train, y_train) # 开始对整个训练集训练sigma_inv = inv(shared_sigma)w = np.dot((mu1 - mu2), sigma_inv)X_t = x_test.Tb = (-0.5) * np.dot(np.dot(mu1.T, sigma_inv), mu1) + (0.5) * np.dot(np.dot(mu2.T, sigma_inv), mu2) + np.log(float(N1) / N2)a = np.dot(w, X_t) + by = sigmoid(a)y_ = np.around(y).astype(np.int)df = pd.DataFrame({"id" : np.arange(1,16282), "label": y_})result = (np.squeeze(y_ans) == y_)print('Test acc = %f' % (float(result.sum()) / result.shape[0]))df = pd.DataFrame({"id": np.arange(1, 16282), "label": y_})if not os.path.exists(output_dir):os.mkdir(output_dir)df.to_csv(os.path.join(output_dir+'gd_output.csv'), sep='\t', index=False)
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!