Intel ADQ与DDP
英特尔X800系列十万兆以太网卡 支持ADQ与DDP优化
- 一、应用设备队列(ApplicationDevice Queues,ADQ)
- 简介
- ADQ性能优化措施:
- ADQ如何工作:
- 与内核旁路的区别
- 如何使用
- 性能优势
- 实验结果
- 二、动态设备个性化(Dynamic Device Personalization,DDP)
- 简介
一、应用设备队列(ApplicationDevice Queues,ADQ)
Learn more at intel.com/ADQ
简介
2019 年 4 月 2 日,英特尔发布了下一代基础网络技术英特尔® 以太网 800 系列,其速度高达 100GbE,并具有许多新的创新功能。
使新的英特尔以太网 800 系列与众不同的一项高级功能是应用程序设备队列 (ADQ)。ADQ 使管理员能够为优先网络服务指定某些应用程序,以确保特定的响应时间。
就像为应用程序预留了一条快速车道:

ADQ技术使用可扩展的设备队列和优化的设备队列数据路径的应用程序线程,实现特定于应用程序的数据控制、隔离、信令和速率限制。
ADQ的目标是通过减少响应时间抖动、降低延迟和提高使用标准Linux网络堆栈和接口的应用程序的吞吐量来提高可预测性。
ADQ性能优化措施:
1)将应用程序流量隔离到自己的专用队列。
2)将应用程序线程绑定到硬件设备队列,结合事件轮询接口(如epoll),创建单个生产者消费者数据流,避免昂贵的同步/争用。
3)速率限制每个应用程序的出口数据流量。
4)减少每秒上下文切换的次数。
ADQ如何工作:
硬件:ADQ为应用程序提供了可定制的专用硬件队列范围(可以看作队列组)。为此,扩展了TC MQPRIO接口。TC MQPRIO调度器配置流量类、队列布局和带宽速率限制,并将它们卸载给硬件。为队列组创建硬件通道(VSIs)。通过使用硬件交换机过滤器(基于tc-flower)根据应用程序标识符将流重定向到队列组来实现对RX队列的流量隔离。然后,硬件使用RSS/Flow Director在队列组中选择队列。
软件:
为了使特定于ADQ应用程序的队列模型以优化的方式工作,一个无同步的、单一生产者消费者模型是可取的。为了完成这个抽象,在应用程序线程和设备队列之间建立了一个唯一的管道,方法如下:
对齐应用程序线程到队列,在应用程序线程上下文中进行包处理,同时线程可以自由地跨内核移动(硬件队列不会改变)。
引入了套接字选项SO_INCOMING_NAPI_ID,因此应用程序还可以使用此信息在基于接收队列(aka NAPI_ID)的线程之间分割传入流。
内核中还启用了使用繁忙轮询设备队列的事件轮询(epoll)。
ADQ通过允许对每个应用程序进行带宽管理来避免资源短缺。这是使用TC MQPRIO完成的,用于配置每个流量类的带宽速率并将它们卸载到硬件。硬件调度程序保证给定队列的指定传输带宽。
与内核旁路的区别
以前,只有使用专有的TCP/IP软件堆栈绕过内核、使用用户模式网络的特定应用程序才能实现这种性能水平。使用ADQ,曾经只能在用户模式网络中实现的性能现在可以在内核模式网络中实现。内核模式网络是开放源码的,并利用了Linux内核中增强的固有优势,比如带有容器、网络过滤器和其他TCP增强的扩展Berkeley Packet Filter (eBPF)。
如何使用

英特尔已经向Linux内核升级了关键补丁以支持ADQ;这些补丁已经被Linux社区在4.19及更高版本中接受。目前正在制定其他操作系统的计划。
像开源Redis或Netperf基准这样的单线程应用程序不需要修改。
在大多数情况下,需要添加一些代码(通常少于50行C代码)来支持ADQ应用程序:
对于开源的Redis和memcached应用程序,英特尔提供了配置指南,展示了系统管理员如何为不耐受延迟的应用程序分配专用的ADQs。
在通信、存储(例如,基于TCP的NVM Express [NVMe*])和容器领域将启用更多的应用程序。
性能优势
系统中原来存在的低效率因素:
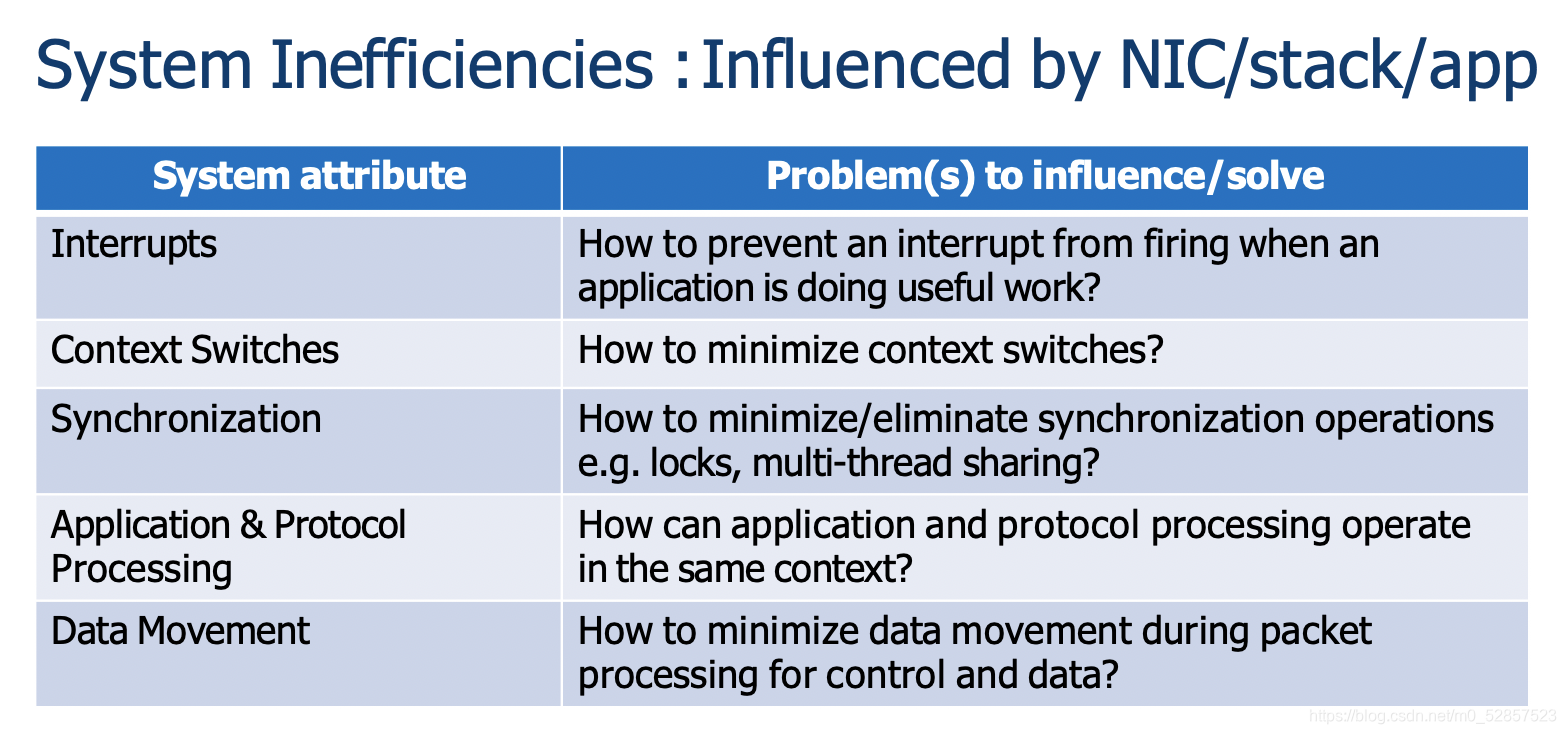
中断:当应用程序正在做有用的工作时,如何防止中断的发生?
上下文切换:如何最小化上下文切换?
同步:如何最小化/消除同步操作,例如锁,多线程共享?
应用与协议处理:应用程序和协议处理如何在同一上下文中运行?
数据移动:如何在控制和数据的包处理过程中最小化数据移动?
ADQ带来的改善:

中断:通过基于事件的轮询,显著减少应用程序活动期间的中断数量
上下文切换:繁忙轮询使应用程序上下文在应用程序相关的通信期间始终处于活动状态
同步:单一生产者消费者模型在应用程序线程和设备队列之间创建一个唯一的管道
应用与协议处理:来自应用程序的协议处理触发器。每个应用程序的传输速率限制。
数据移动:单一生产者消费者数据流和基于繁忙轮询的事件限制了数据移动边界
ADQ提供了应用程序开发人员可以依赖的快速和可预测的数据传输性能,因此他们和网络运营商可以相应地优化他们的应用程序。通过在应用程序线程和设备队列之间创建专用管道,ADQ不仅减少了资源争用,而且还减少或消除了同步操作,如锁和多线程共享。中断和上下文切换也会增加交通混乱。ADQ使用繁忙轮询来减少中断和上下文切换的数量。通过使用这些方法的组合,ADQ提高了应用程序的性能并降低了抖动。
ADQ提供了特定于应用程序的、无竞争的、流畅的流量,因为在这些队列上没有来自其他应用程序的流量共享。交通整形通过避免争用(没有交通堵塞)、限速交通(有计程器的坡道)和减少每秒中断和上下文切换的数量(没有变道)来减少抖动
实验结果
测试表明,与未启用ADQ相比,启用ADQ时应用程序性能有显著提高。
例如,使用开源Redis*数据库软件进行的测试显示,在启用ADQ后,可预测性增加了50%以上,应用程序延迟减少了45%以上,应用程序吞吐量提高了30%以上
二、动态设备个性化(Dynamic Device Personalization,DDP)
简介
英特尔®以太网700系列 与 800系列 支持 动态设备个性化
英特尔®以太网700系列的动态设备个性化https://blog.csdn.net/weixin_37097605/article/details/101514696
将部分英特尔®以太网500系列、82599、X540和X550中使用的固定管道转移到一个可编程的管道,可以进行定制以满足各种客户要求,可以满足用户自定义的新数据包分类(PCTYPE’s)。
DDP允许动态重新配置包处理管道,以满足特定用例。运行时向网络适配器添加新的包处理管道配置profile,无需重置或重启服务器。软件以一种非永久性、交互式模式应用这些自定义profile,因此在网络适配器重启或软件回退profile后,将恢复网络控制器的原始配置。
DPDK提供了处理DDP包需要的所有API,可以对新数据包类型进行分类,并将这些数据包分发到设备指定的队列,这提高了性能及CPU利用率:
· 不再要求主机CPU对指定的用例执行数据包类型的分类和负载均衡
· 增加数据包吞吐量;
· 减少数据包延迟。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!