Collection集合总集(超详细)
Collection
目录
- Collection
- 一、集合概述
- 1.集合是什么?
- 2.集合存储什么?
- 3.集合的数据结构
- 4.集合在JDK的哪个包?
- 5.Collection集合
- 5.1集合存储方式
- 5.2集合继承图
- 5.3集合特点
- 5.4List实现类
- 5.5Set实现类
- 6.Map集合
- 6.1HashMap
- 6.2HashTable
- 6.2.1 Properties
- 6.3SortedMap
- 6.3.1 TreeMap
- 6.4Map集合继承图
- 二、Connection常用方法
- 1.add
- 2.size
- 3.contains
- 3.1源码分析
- 3.2containsJVM图
- 3.3结论
- 4.remove
- 4.1源码分析
- 5.isEmpty
- 6.toArray
- 7.iterator(重点)
- 7.1迭代器工作图
- 7.2迭代器方法
- 7.3使用方法
- 7.4重点
- 三、List特有常用方法
- 1.add
- 2.get
- 3.indexOf
- 4.remove
- 5.set
- 四、ArrayList源码分析
- 1.初始容量
- 2.自动扩容
- 3.转为线程安全
- 五、LinkedList源码分析
- 1.初始化
- 2.添加元素
- 六、Vector源码分析
- 1.底层数据结构
- 2.初始容量
- 3.自动扩容
- 4.线程同步
- 七、HashSet源码分析
- 1.HashSet特点
- 2.底层数据结构
- 八、TreeSet源码分析
- 1.TreeSet特点
- 2.底层数据结构
一、集合概述
1.集合是什么?
数组就是一个集合。集合就是一个容器,用来容纳其他数据类型的数据,集合会把new出来的对象装进去,使用时再一个个拿出来,是一个载体。
2.集合存储什么?
集合不能直接存储基本数据类型,另外集合也不能直接存储java对象,集合当中存储的是java对象的地址(或者说存储的是引用)。
集合是来存储其他对象的,集合本身就是一个对象,如下图:
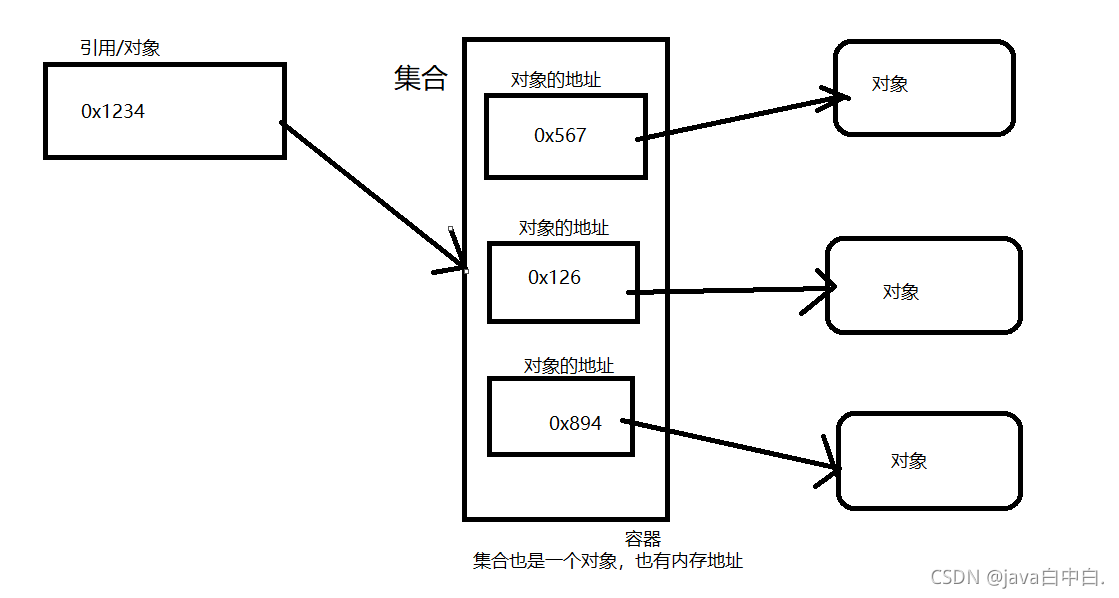
以下代码中可以直接加入基本数据类型的原因是,在将int数据类型加入集合中时会自动装箱,将int转为integer对象数据类型
public static void main(String[] args) {Collection collection= new ArrayList();collection.add(1);collection.add(2);System.out.println(collection);
}
3.集合的数据结构
在java中,每一个不同的集合底层都是不同的数据结构,往不同的集合中添加数据,相当于将数据放到了不同的数据结构中,比如往集合c1中放入数据可能就放在了数组中,往集合c2中放入数据可能就放在了二叉树中…
使用不同的集合就相当于使用不同的数据结构。
数组、二叉树、链表、哈希表…都是常见的数据结构。
4.集合在JDK的哪个包?
集合在JDK中的java.util.*下,所有的集合类和集合接口都在java.util包下。
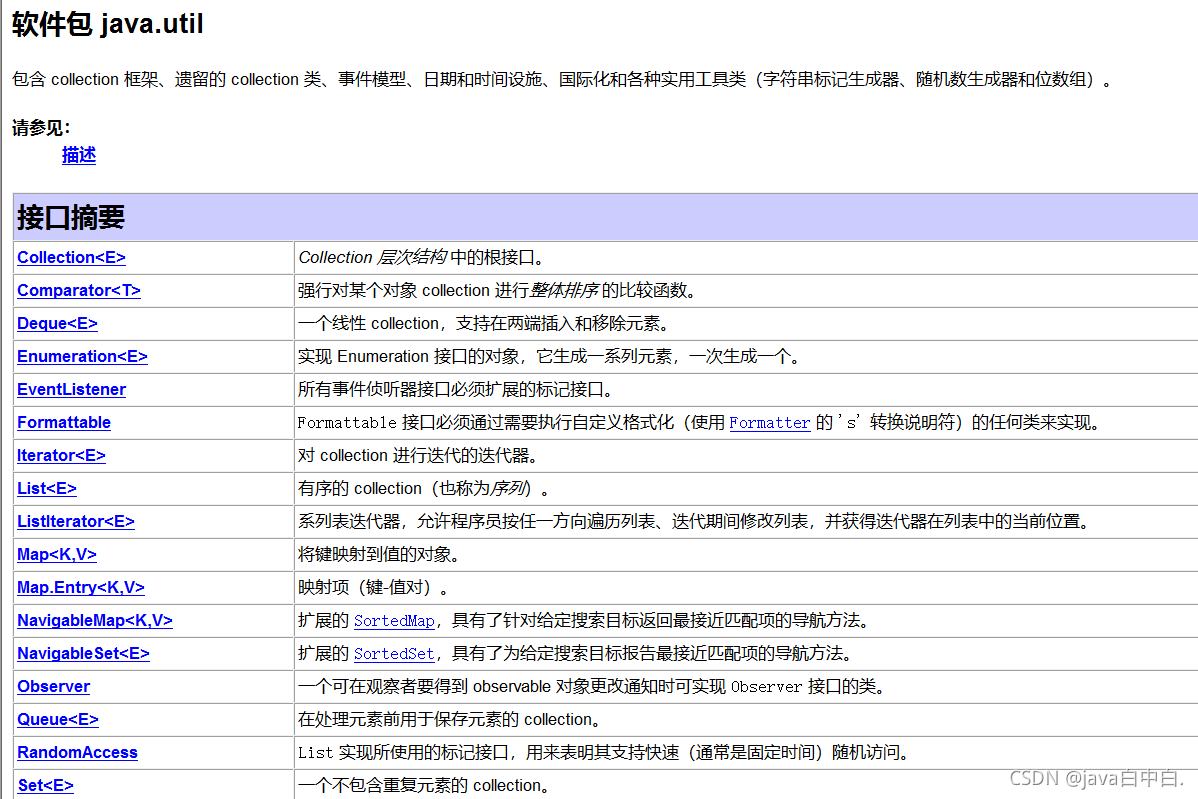
5.Collection集合
5.1集合存储方式
集合分为两大类,一类是单个方式存储对象,一类是以键值对的方式存储对象。
单个方式:单个方式存储对象直接往集合中存储就行,这一类集合中超级父类接口:java.util.Collection
键值对:以键值对的方式存储对象时,需要将对象以及其名称传入,这一类集合中超级父接口:java.util.Map
5.2集合继承图
所有的集合都是继承Iterable接口,说明所有集合都是可迭代的,可遍历的。
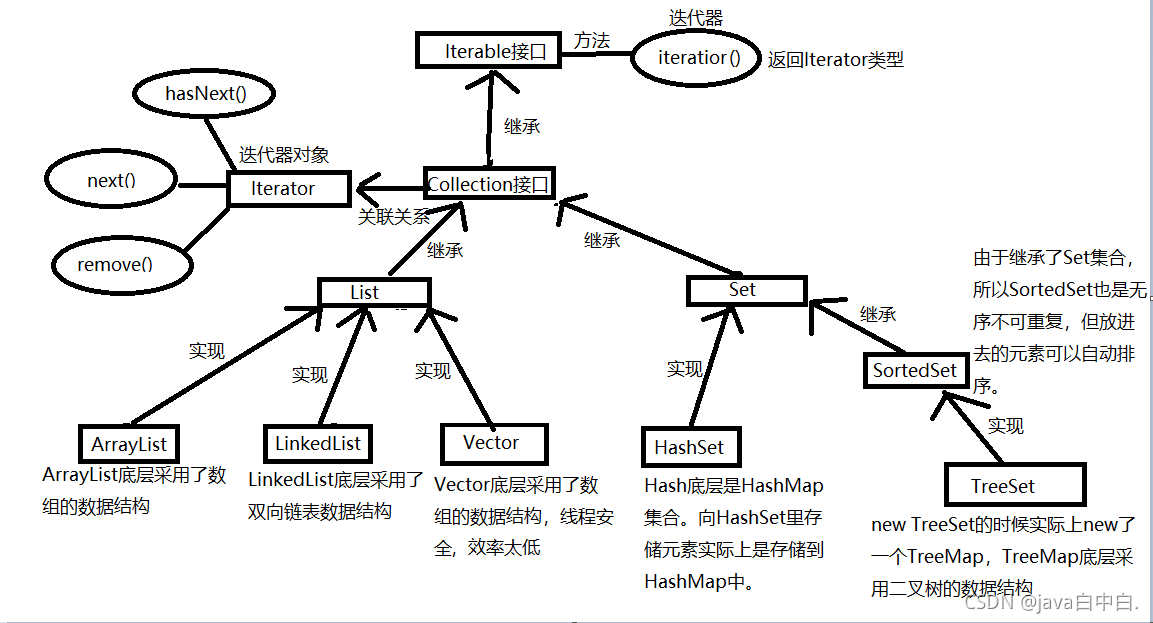
5.3集合特点
List集合存储特点:有序可重复,存储的元素有下标。有序指存进去是这个顺序,取出来依然是这个顺序,不是说按照大小排序。
有序性可由以下代码和结果体现:
public static void main(String[] args) {List list=new ArrayList();list.add(1);list.add(2);list.add(3);list.add(4);Iterator it=list.iterator();while (it.hasNext()){System.out.println(it.next());}
}

Set集合存储体点:无序不可重复,给Set集合中存储进去的顺序和取出来的顺序不一定相同,存储的元素没有下标,给Set集合中存储的元素也不能一样。
注意:Set集合不能重复,不是说加入重复的元素就会报错,而是不会将第二个重复的元素存进去,以下代码和结果可以体现:
public static void main(String[] args) {Set set=new HashSet();set.add(1);set.add(1);set.add(2);set.add(3);set.add(3);Iterator it=set.iterator();while (it.hasNext()){System.out.println(it.next());}
}

5.4List实现类
我们要学的List实现类主要为:ArrayList、LinkedList、Vector
ArrayList:底层采用数组的数据结构,ArrayList是非线程安全的。
LinkedList:底层采用双向链表的数据结构。
Vector:底层采用数组的数据结构,Vector是线程安全的,但由于效率太低,且目前有保证线程安全的其他方案,所以Vector使用较少。
5.5Set实现类
我们要学的Set实现类主要有:HashSet、TreeSet
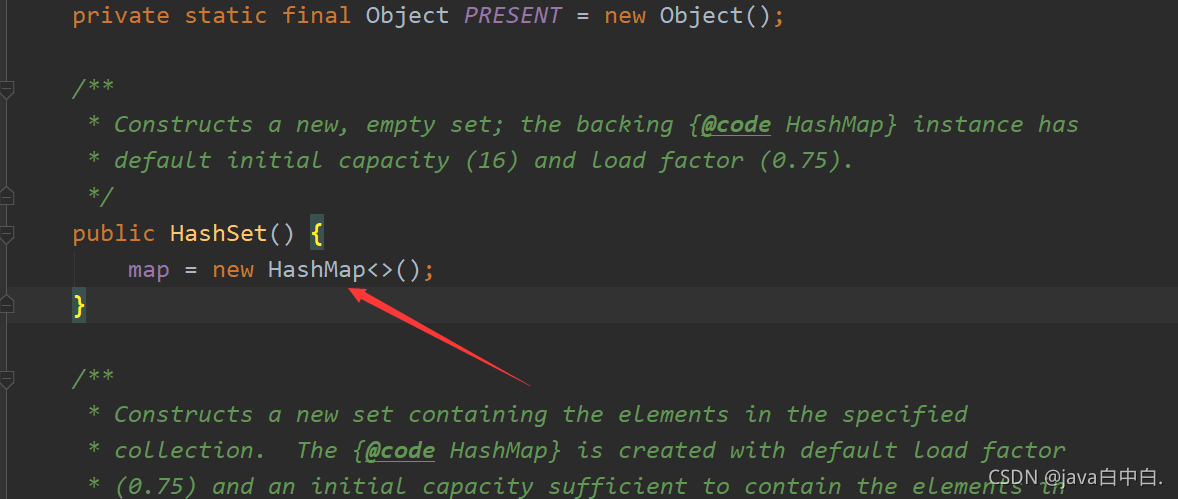
HashSet:HashSet在new的时候,底层实际上new了一个HashMap,往HashSet存储数据实际是存储在HashMap中,HashMap集合的底层采用哈希表的数据结构。
HashSet底层是一个HashMap,以下为源码:
SortedSet:由于SortedSet也是继承Set,所以也是无序不可重复的特点,但放入SortedSet的元素可以自动排序,如下代码和结果:
public static void main(String[] args) {Set set=new TreeSet();set.add(44);set.add(3);set.add(65);set.add(2);Iterator it=set.iterator();while (it.hasNext()){System.out.println(it.next());}
}

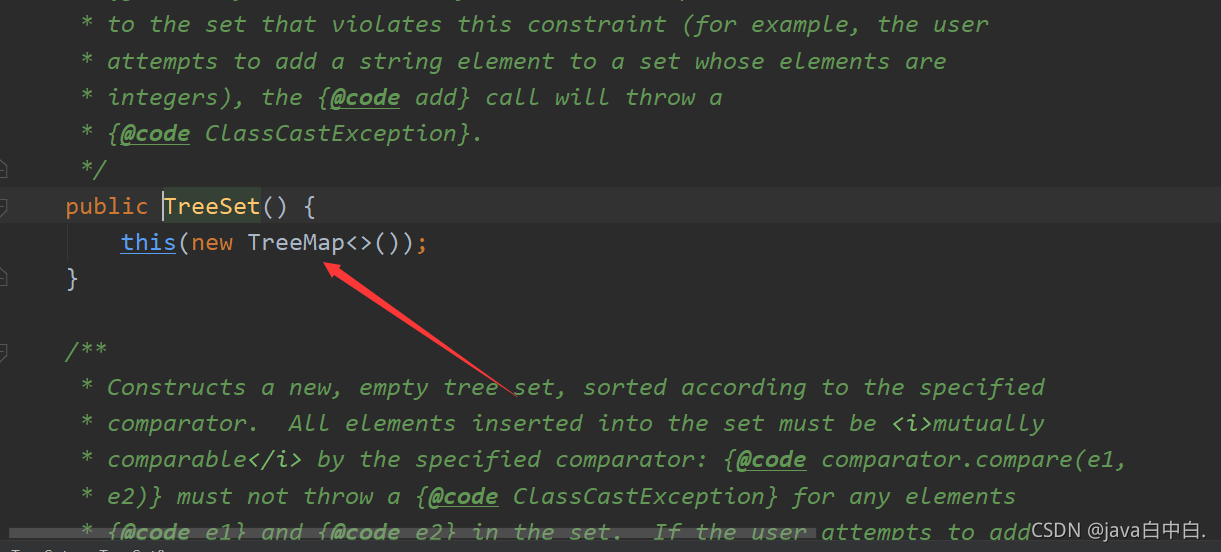
TreeSet:TreeSet继承于SortedSet,TreeSet在new的时候,底层实际上new了一个TreeMap,往TreeSet中放数据实际是给TreeMap中存放数据,TreeMap底层采用二叉树的数据结构。
TreeSet底层是一个TreeMap,以下为源码:
6.Map集合
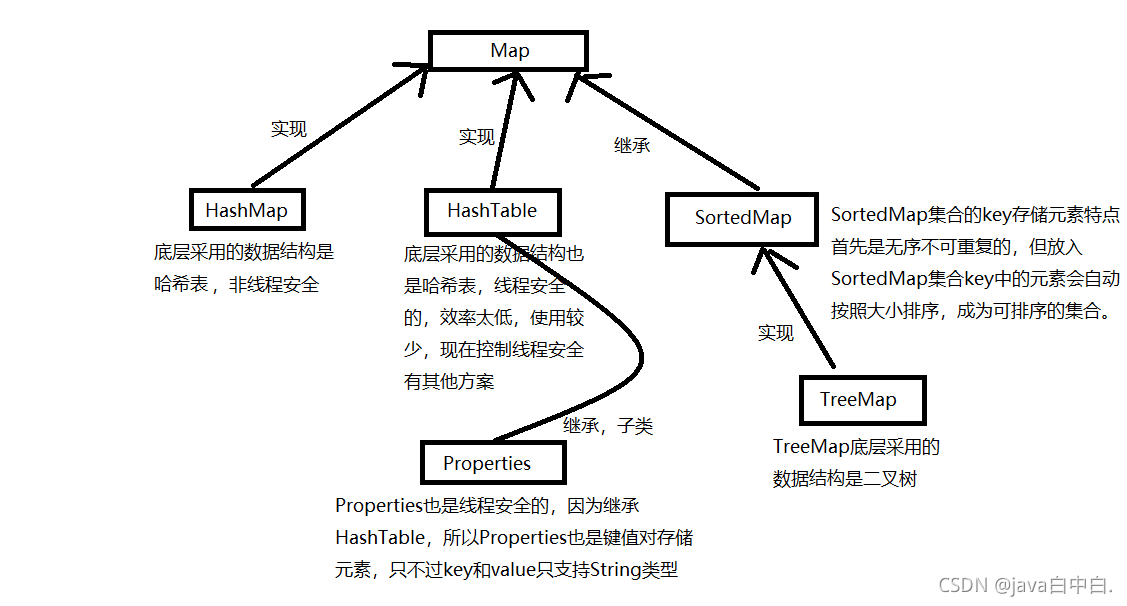
Map集合和Collection集合没有任何关系。上面的Collection集合是以单个方式存储元素的,而Map集合是以键值对的方式存储元素,所有Map集合的Key是无需不可重复的。
Map集合的实现类主要为HashMap、HashTable。子接口有一个SortedMap,SortedMap有一个TreeMap实现类。
6.1HashMap
HashMap底层采用哈希表的数据结构,非线程安全的。
6.2HashTable
HashTable底层采用哈希表的数据结构,线程安全的,效率太低,使用较少,现在控制线程安全有其他的方式。
6.2.1 Properties
Properties是HashTable下的一个实现类,由于继承了HashTable,所以Properties也是线程安全的,Properties的key和value只支持String数据类型。
6.3SortedMap
SortedMap继承Map,所以SortedMap也有无序不可重复的特点,但SortedMap集合中key的元素可以自动按照大小排列,称为可排列集合。
6.3.1 TreeMap
TreeMap是SortedMap的实现类,底层采用二叉树的数据结构,无序不可重复,但存入key的元素会按照大小排列。
6.4Map集合继承图
二、Connection常用方法
1.add
connection中有add()方法,如果不加泛型,那么集合中可以加入各种类型的数据(基本类型数据被自动装箱),如下:
public static void main(String[] args) {Collection collection=new ArrayList();collection.add(1);collection.add(new LinkedList<>());collection.add(3.14);collection.add("你好!");
}
2.size
connection中有size()方法,用来获取集合中元素的个数。
3.contains
判断集合中是否包含某个元素,使用方法如下:
public static void main(String[] args) {Collection collection=new ArrayList();collection.add(1);collection.add(new LinkedList<>());collection.add(3.14);collection.add("你好!");boolean contains = collection.contains(3.14);System.out.println(contains);
}
3.1源码分析
contains方法用来判断集合中是否有某个元素,此元素可为int、float、double等普通类型,也可为String等引用对象类型。以下为ArrayList的源码:
public boolean contains(Object o) {return indexOf(o) >= 0;}public int indexOf(Object o) {return indexOfRange(o, 0, size);
}int indexOfRange(Object o, int start, int end) {Object[] es = elementData;if (o == null) {for (int i = start; i < end; i++) {if (es[i] == null) {return i;}}} else {for (int i = start; i < end; i++) {if (o.equals(es[i])) {return i;}}}return -1;
}
在contains的源码中,调用了equals方法,而equals方法比较的是内容。
如下为String引用对象类型的测试,String类中重写了equals方法,所以结果为true:
public static void main(String[] args) {Collection collection=new ArrayList();String s1=new String("jack");String s2=new String("jack");collection.add(s1);System.out.println(collection.contains(s2));
}
Object中equals的方法对比的是对象的地址,而不是内容,源码如下:

下面是自定义引用对象类型的测试,结果为false,因为此类中没有重写equals方法,调用的是Object中的euqals方法,如下:
public class Test01 {public static void main(String[] args) {Collection collection=new ArrayList();User u1=new User("jack");User u2=new User("jack");collection.add(u1);System.out.println(collection.contains(u2));}
}class User{
private String name;
public User(){};
public User(String name){this.name=name;}
}
若重写User类中的equals方法之后,结果为true。
3.2containsJVM图
下图是程序运行时JVM内存图,可以看到,将String类型对象a和b放入集合中,实际上是把对象的内存地址放入集合中,x对象的内存地址并不在集合中。集合中的contains方法使用equals方法而不是简单的"==",否则只会比较对象地址,故所有放入集合中的java对象都要重写equals方法。
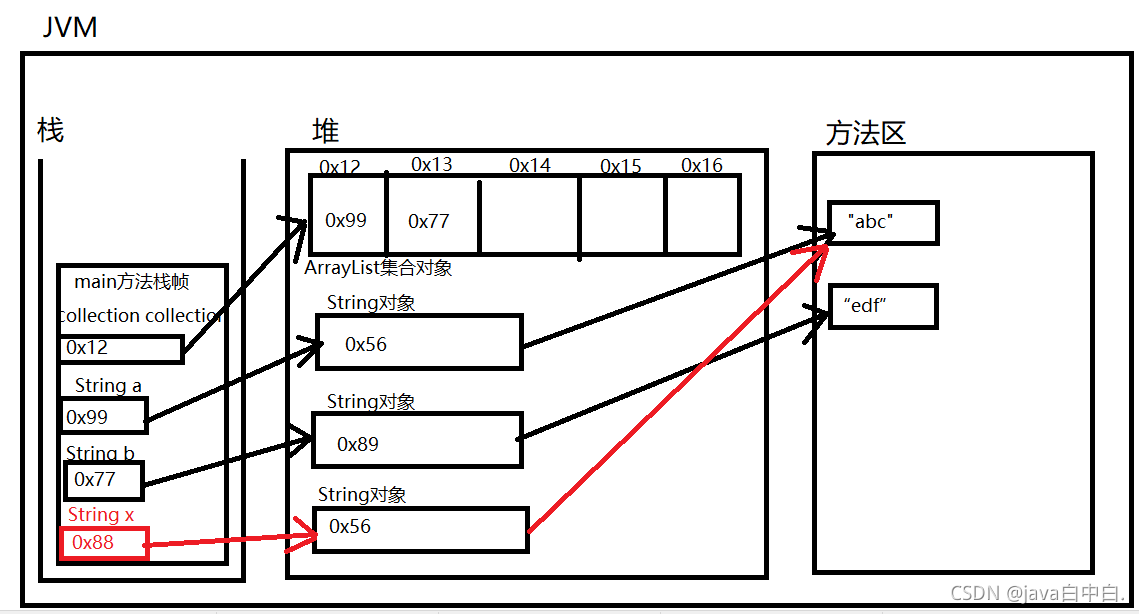
3.3结论
从3.1中分析得出,存放在集合中的java对象要重写equals方法。
4.remove
删除集合中的某个元素,使用方法如下:
public static void main(String[] args) {Collection collection=new ArrayList();collection.add(1);collection.add(new LinkedList<>());collection.add(3.14);collection.add("你好!");collection.remove(3.14);
}
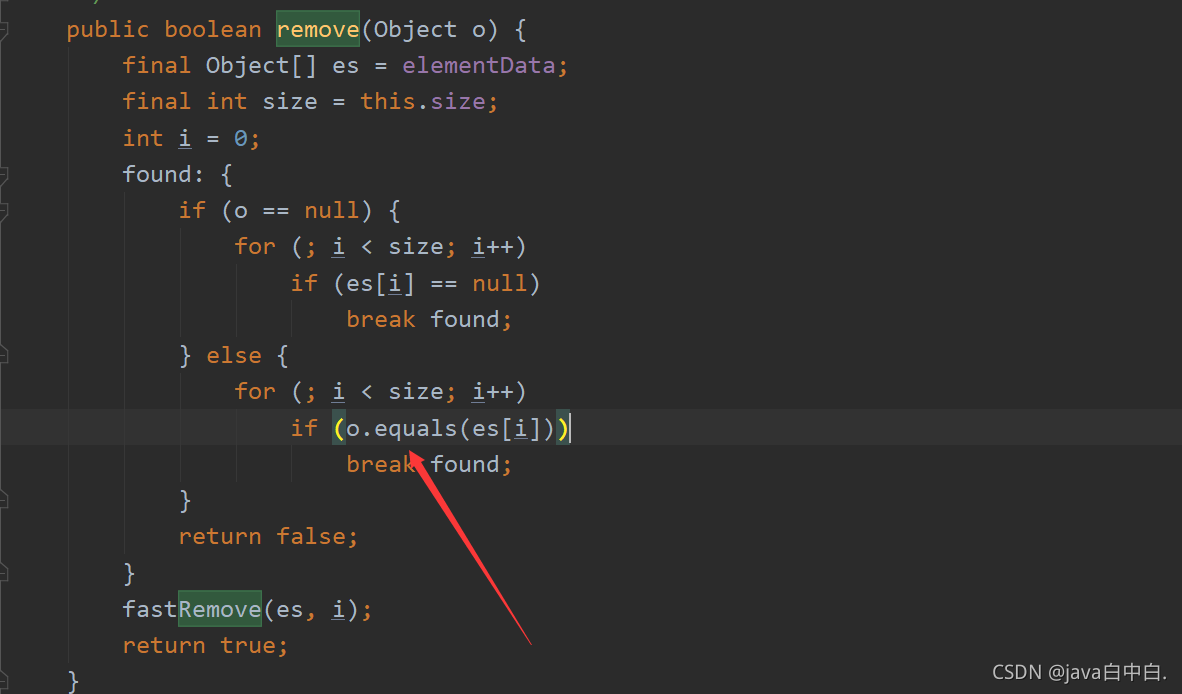
4.1源码分析
remove源码和contains源码一样,都调用了equals方法,以下是ArryList集合中remove方法的源码,由于contains写了相关介绍,这块只介绍remove的源码:
5.isEmpty
判断集合中是否存在元素,若空返回true,使用方法如下:
public static void main(String[] args) {Collection collection=new ArrayList();collection.add(1);collection.add(new LinkedList<>());collection.add(3.14);collection.add("你好!");boolean flag = collection.isEmpty();System.out.println(flag);
}
6.toArray
把集合转换成数组,使用方法如下:
public static void main(String[] args) {Collection collection=new ArrayList();collection.add(1);collection.add(new LinkedList<>());collection.add(3.14);collection.add("你好!");Object[] objects = collection.toArray();for (Object object : objects) {System.out.println(object);}
}
7.iterator(重点)
集合的一种遍历/迭代方式,只能在Collection中使用,不能在Map中使用。
iterator是Collection继承Iterable的一个方法,此方法返回Iterator类型,称为迭代器。
7.1迭代器工作图
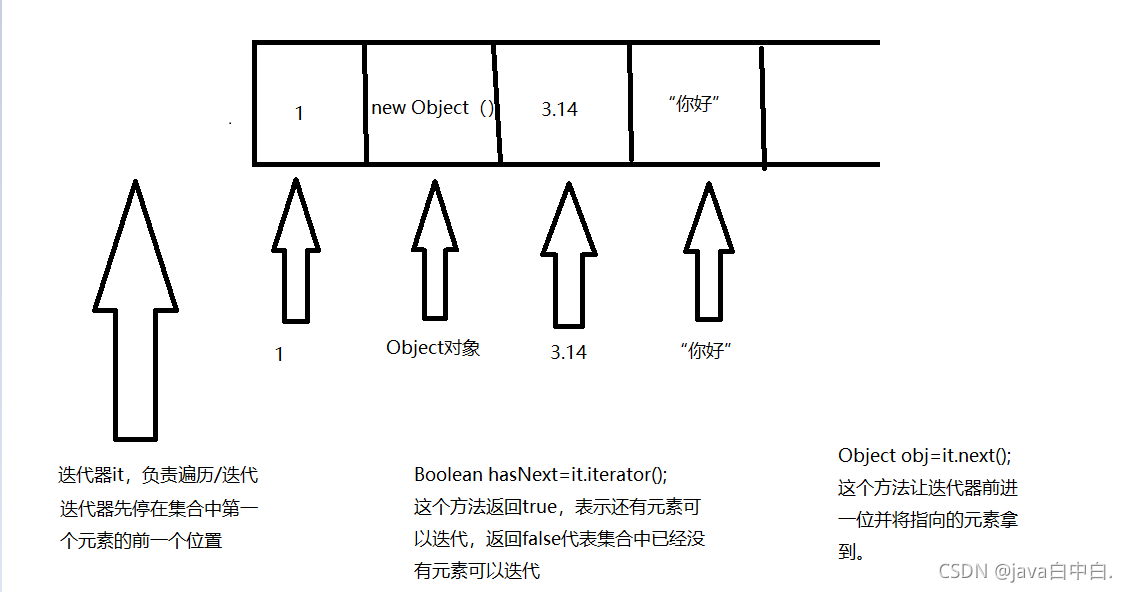
7.2迭代器方法
迭代器中常用的方法有两种:hasNext()、next()
hasNext:判断迭代器所指向的下一个位置是否有元素,若有元素则返回true。
next:使迭代器前进一位并将指向的元素取出。
7.3使用方法
public static void main(String[] args) {Collection collection=new ArrayList();collection.add(1);collection.add(new Object());collection.add(3.14);collection.add("你好!");//获取迭代器Iterator it=collection.iterator();//遍历迭代器while (it.hasNext()){System.out.println(it.next());}
}
7.4重点
当集合中元素结构改变时,迭代器需要重新获取。
如下代码,迭代器在添加元素之前获取,之后添加的元素不能被迭代器获取到,代码和结果如下:
public static void main(String[] args) {Collection c=new ArrayList();Iterator it=c.iterator();c.add(1);c.add(2);c.add(3);while (it.hasNext()){System.out.println(it.next());}
}

集合只要在获取迭代器之后进行增加、删除等其他方法时,都会报上图的异常。
为什么集合结构改变之后要重新获取迭代器?
获取集合迭代器对象,相当于获取到此时集合状态的一个快照,迭代器迭代的时候会参照快照迭代,而集合结构改变之后,之前的快照和改变之后的集合结构不一样。
底层会有一个检查机制,随时检查快照和当前集合的结构状态是否一样,不一样则会报异常。
三、List特有常用方法
1.add
方法全称为:add(inde index,Object element),Collection集合中也有add()方法,但List集合中增加了一个可以根据下标增加元素的方法,使用方法如下:
public static void main(String[] args) {List list=new ArrayList();list.add(1);list.add(2);list.add(3);list.add(2,"nihao");Iterator it = list.iterator();while (it.hasNext()){System.out.println(it.next());}
}
注意
1.由于ArrayList集合底层是数组,所以下标是从0.1.2.3…开始的,故插入时也是根据这个插入元素的
2.ArrayList集合底层是数组,其插入元素效率太低,而查询元素效率高,所以此方法使用不是很多。
2.get
方法全称为:get(int index),可以根据下标获取元素,ArrayList底层是数组,查询效率高,使用方法如下:
public static void main(String[] args) {List list=new ArrayList();list.add(1);list.add(2);list.add(3);list.add(2,"nihao");Object o = list.get(3);System.out.println(o);
}
3.indexOf
方法全称:indexOf(Object o),可以根据元素获取元素第一次出现的下标,使用方法如下:
public static void main(String[] args) {List list=new ArrayList();list.add(1);list.add(2);list.add(3);list.add(2,"nihao");int i = list.indexOf("nihao");System.out.println(i);
}
4.remove
方法全称:remove(int index),可以根据下标进行删除集合中的元素,使用方法如下:
public static void main(String[] args) {List list=new ArrayList();list.add(1);list.add(2);list.add(3);list.add(2,"nihao");list.remove(1);
}
5.set
方法全称:set(int index,Object element),可以根据下标更改集合中的元素,使用方法如下:
public static void main(String[] args) {List list=new ArrayList();list.add(1);list.add(2);list.add(3);list.add(2,"nihao");list.set(2,"你好");
}
四、ArrayList源码分析
ArrayList集合是非线程安全的。
ArrayList集合底层是Object类型的数组,源码如下:
// non-private to simplify nested class access
transient Object[] elementData;
创建ArrayList集合时有两种创建方式,一种是无参,另一种是有参,可以传入int类型数据,创建初始容量为此数据大小的数组,源码如下:
//无参构造
public ArrayList() {this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
//有参构造
public ArrayList(int initialCapacity) {if (initialCapacity > 0) {this.elementData = new Object[initialCapacity];} else if (initialCapacity == 0) {this.elementData = EMPTY_ELEMENTDATA;} else {throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);}
}
有参和无参创建ArrayList集合测试,代码如下:
List list1=new ArrayList();
List list2=new ArrayList(20);
1.初始容量
在早版本的JDK中直接会创建一个初始容量为10的数组。
在JDK8以后,会先创建一个长度为0的数组,当添加第一个元素时数组长度为10,源码如下:
/*** Constructs an empty list with an initial capacity of ten.*/
public ArrayList() {this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}/*** Shared empty array instance used for default sized empty instances. We* distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when first element is added.*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
2.自动扩容
由于ArrayList底层是数组,当数组容量不够的时候需要自动扩容。
在源代码中,扩容增长量是旧容量向右移一位(位运算),相当于扩容增长量为旧容量的1/2,比如旧容量为4,扩容增长量为4/2=2,那么增长倍数为6/4=1.5倍,所以旧容量是新容量的1.5倍,源码如下:
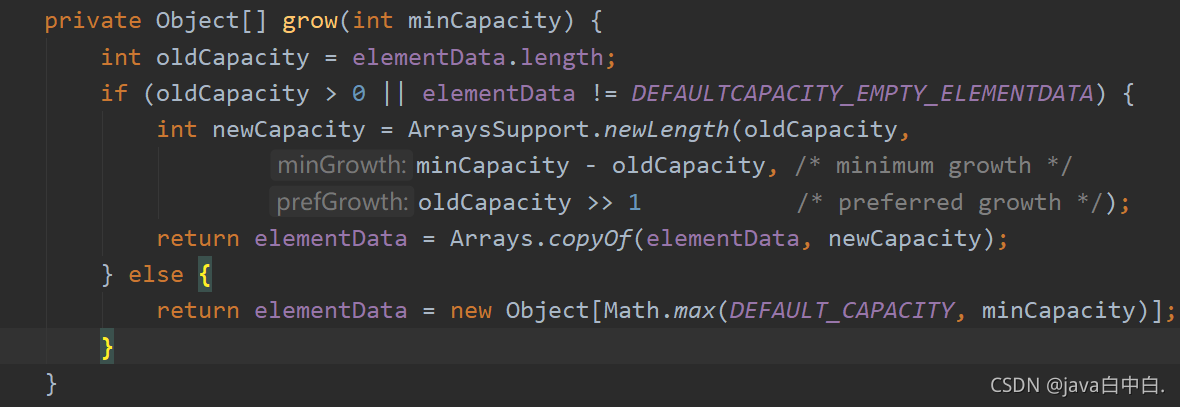
【小知识点】位运算:10>>1
计算10向右移一位的值,10的二进制为1010,左边第一个为0,将整体向右移,结果为0101,结果为5。
3.转为线程安全
ArrayList集合是非线程安全的,如何把ArrayList集合转换成线程安全的?
使用集合工具类:java.util.Collections
以下为将ArrayList集合转换为线程安全的代码:
public static void main(String[] args) {//ArrayList集合是非线程安全的List list=new ArrayList();//变成线程安全的Collections.synchronizedList(list);list.add(1);list.add(2);list.add(3);
}
五、LinkedList源码分析
LinkedList集合底层是双向链表,在添加元素时添加结点的构造方法中可以看到:
private static class Node<E> {E item;Node<E> next;Node<E> prev;Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;this.prev = prev;}
}
1.初始化
使用无参构造new LinkedList集合时,首先会构造一个空的集合,以下为构造LinkedList集合的源码:
/*** Pointer to first node.*/
//一直指向首节点的引用
transient Node<E> first;/*** Pointer to last node.*/
//一直指向尾节点的引用
transient Node<E> last;
/*** Constructs an empty list.*/
//无参构造
public LinkedList() {
}
2.添加元素
在集合添加元素时会创建新的节点,first引用始终指向收首节点,last引用始终指向尾结点。
以下为添加元素的源码,后面会根据源码来讲解如何添加元素。
/*** Pointer to first node.*/
transient Node<E> first;//指向首节点的引用/*** Pointer to last node.*/
transient Node<E> last;//指向尾节点的引用
//添加元素的方法
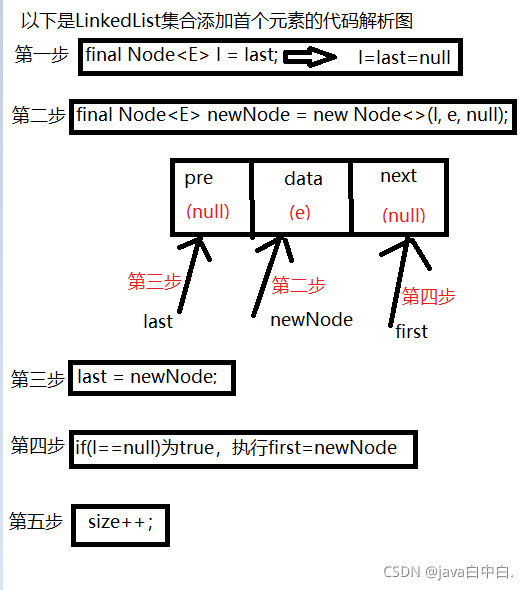
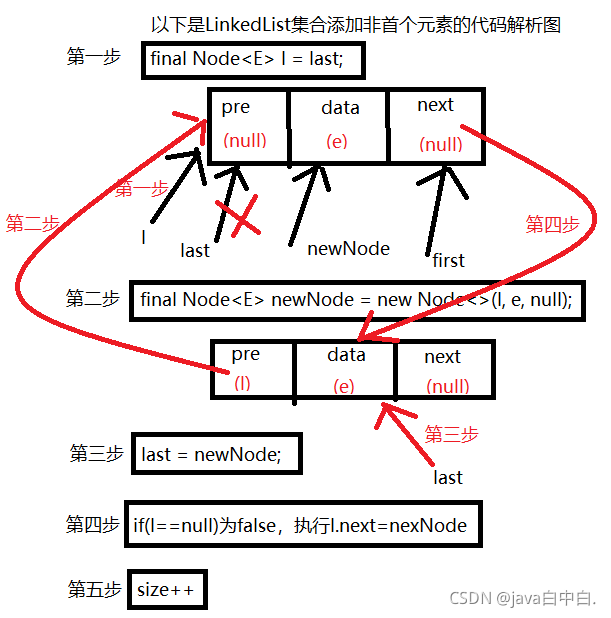
public boolean add(E e) {linkLast(e);return true;
}void linkLast(E e) {final Node<E> l = last;final Node<E> newNode = new Node<>(l, e, null);last = newNode;if (l == null)first = newNode;elsel.next = newNode;size++;modCount++;
}
当集合刚创建为空,last和first为null,添加第一个元素时代码解析图如下:
当集合添加非首元素时,代码解析图如下:
以下为以上两者结合图,如下:
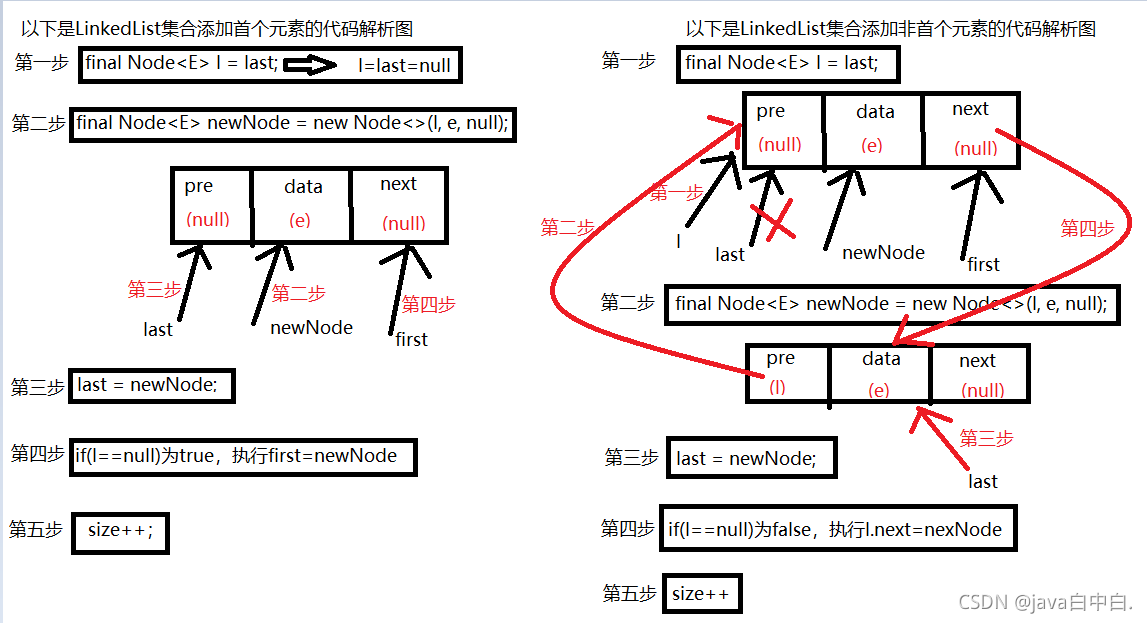
六、Vector源码分析
1.底层数据结构
Vector集合和ArryList集合底层数据结构一样,都是数组,以下为源码
@SuppressWarnings("serial") // Conditionally serializable
protected Object[] elementData;
2.初始容量
Vector集合使用无参构造new对象之后,会生成一个容量(initialCapacity)为10,容量增加量(capacityIncrement)为0的数组,此时元素数量(elementCount)为0,当使用add方法时,元素数量会自增。可以根据源码的注释读,以下为源码:
/*** Constructs an empty vector so that its internal data array* has size {@code 10} and its standard capacity increment is* zero.*/
public Vector() {this(10);
}/**
* Constructs an empty vector with the specified initial capacity and
* with its capacity increment equal to zero.
*
* @param initialCapacity the initial capacity of the vector
* @throws IllegalArgumentException if the specified initial capacity is negative
*/
public Vector(int initialCapacity) {this(initialCapacity, 0);
}/*** Constructs an empty vector with the specified initial capacity and* capacity increment.** @param initialCapacity the initial capacity of the vector* @param capacityIncrement the amount by which the capacity is* increased when the vector overflows* @throws IllegalArgumentException if the specified initial capacity is negative*/
public Vector(int initialCapacity, int capacityIncrement) {super();if (initialCapacity < 0)throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);this.elementData = new Object[initialCapacity];this.capacityIncrement = capacityIncrement;
}
3.自动扩容
对自动扩容进行测试,加11个元素,在加第11个元素那块加断点,在grow()方法加断点,可以得出**新容量(newCapacity)是旧容量的2倍。**以下为debug截图:
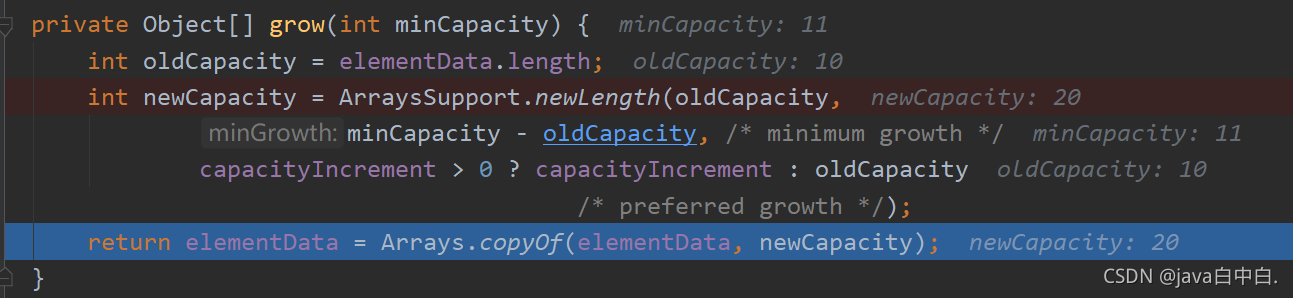
以下是添加元素到自动扩容的源码:
//调用add方法
public synchronized boolean add(E e) {modCount++;add(e, elementData, elementCount);return true;
}
//上面所调用的add私有方法
private void add(E e, Object[] elementData, int s) {if (s == elementData.length)elementData = grow();//增长方法,扩容方法elementData[s] = e;elementCount = s + 1;
}
//扩容方法
private Object[] grow() {return grow(elementCount + 1);//参数为目前元素总数+1
}
//参数为目前元素总数+1
private Object[] grow(int minCapacity) {int oldCapacity = elementData.length;int newCapacity = ArraysSupport.newLength(oldCapacity,minCapacity - oldCapacity, /* minimum growth */capacityIncrement > 0 ? capacityIncrement : oldCapacity/* preferred growth */);return elementData = Arrays.copyOf(elementData, newCapacity);
}
4.线程同步
Vector中所有方法都带有synchronized,都是线程同步的,线程安全的,效率比较低,使用较少。
七、HashSet源码分析
1.HashSet特点
HashSet集合无序不可重复,无序指存进去的顺序和取出来的顺序可能不一样,不可重复指同一个元素只能存一次,但重复存并不会报错。
2.底层数据结构
创建HashSet时在底层实际new了一个HashMap,源码如下:
/*** Constructs a new, empty set; the backing {@code HashMap} instance has* default initial capacity (16) and load factor (0.75).*/
public HashSet() {map = new HashMap<>();
}
HashSet集合添加元素实际上是给HashMap的key上添加元素,源码如下:
public boolean add(E e) {return map.put(e, PRESENT)==null;
}
八、TreeSet源码分析
1.TreeSet特点
TreeSet集合也是无序不可重复的,但存进去的元素可以按照大小进行排序。
2.底层数据结构
创建TreeSet时底层new了一个TreeMap,源码如下:
public TreeSet() {this(new TreeMap<>());
}
给TreeSet中添加元素时其实是给TreeMap的key部分添加元素,并且TreeMap的key部分是可以按照大小顺序进行排序的,源码如下:
public boolean add(E e) {return m.put(e, PRESENT)==null;
}
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!