分类算法中的准确率、精确率、召回率、混淆矩阵(评估)
交叉表
pd.crosstab(index=y_test, columns=y_, rownames=['True'], colnames=['Predict'], margins=True)
混淆矩阵

from sklearn.metrics import confusion_matrixconfusion_matrix(y_test,y_)# 真实值
y_test.value_counts()# 预测
Series(y_).value_counts()精确率、召回率、f1-score调和平均值




# 精确率、召回率、f1-score调和平均值
from sklearn.metrics import classification_reportprint(classification_report(y_test,y_,target_names = ['B','M']))提升准确率、精确率、召回率的方法
# 归一化操作
X_norm1 = (X - X.min())/(X.max() - X.min())X_train,X_test,y_train,y_test = train_test_split(X_norm1,y,test_size = 0.2)knn = KNeighborsClassifier()params = {'n_neighbors':[i for i in range(1,30)],'weights':['uniform','distance'],'p':[1,2]}
gcv = GridSearchCV(knn,params,scoring='accuracy',cv = 6)
gcv.fit(X_train,y_train)y_ = gcv.predict(X_test)
accuracy_score(y_test,y_)
# 0.98245print(classification_report(y_test,y_,target_names=['B','M']))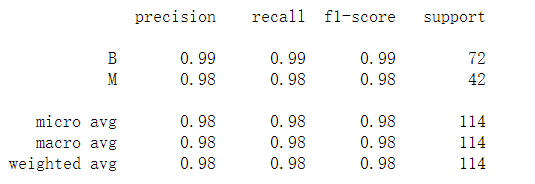
# Z-Score归一化,标准化
X_norm2 = (X - X.mean())/X.std()X_train,X_test,y_train,y_test = train_test_split(X_norm2,y,test_size = 0.2)knn = KNeighborsClassifier()params = {'n_neighbors':[i for i in range(1,30)],'weights':['uniform','distance'],'p':[1,2]}
gcv = GridSearchCV(knn,params,scoring='accuracy',cv = 6)
gcv.fit(X_train,y_train)y_ = gcv.predict(X_test)
accuracy_score(y_test,y_)
# 0.99122在sklearn中已经把归一化和标准化的过程模块化了,因此只需要调用相应的方法即可
归一化和标准化在“prepocessing”数据预处理模块中
sklearn.prepocessing.StandardScaler
sklearn.prepocessing.MinMaxScaler
from sklearn.preprocessing import MinMaxScaler,StandardScaler# MinMaxScaler 和最大值最小值归一化效果一样
mms = MinMaxScaler()mms.fit(X)
X2 = mms.transform(X)# 相当于
((X - X.min())/(X.max() - X.min())).head()ss = StandardScaler()
X3 = ss.fit_transform(X)# 相当于
nd = X.get_values()
(nd - nd.mean(axis = 0))/nd.std(axis = 0)salary练习——将字符串转换为数字
import numpy as np
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
# cv int 6 数据分分成6份
from sklearn.model_selection import cross_val_score,GridSearchCVdata = pd.read_csv('./salary.txt')
data.head()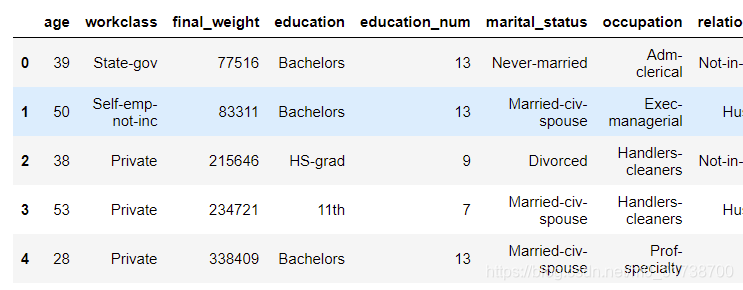
data.columns
data.drop(labels=['final_weight','education','capital_gain','capital_loss'],axis = 1,inplace=True)X = data.iloc[:,0:-1]y = data['salary']knn = KNeighborsClassifier()knn.fit(X,y)# 方法将数据中str转换int,float从而算法可以计算
# map方法,apply,transform
u = X['workclass'].unique()
np.argwhere(u == 'Local-gov')[0,0]
# 4def convert(x):return np.argwhere(u == x)[0,0]
X['workclass'] = X['workclass'].map(convert)cols = [ 'marital_status', 'occupation', 'relationship', 'race', 'sex','native_country']
for col in cols:u = X[col].unique()def convert(x):return np.argwhere(u == x)[0,0]X[col] = X[col].map(convert)knn = KNeighborsClassifier()
kFold = KFold(10)
knn = KNeighborsClassifier()
accuracy = 0
for train,test in kFold.split(X,y):knn.fit(X.loc[train],y[train])acc = knn.score(X.loc[test],y[test])accuracy += acc/10
print(accuracy)
# 0.7973345728987424本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!