文本半监督学习基础模型理解及UDA模型代码目录
2021SC@SDUSC
半监督学习有两个样本集,一个有标记,一个没有标记.分别记作
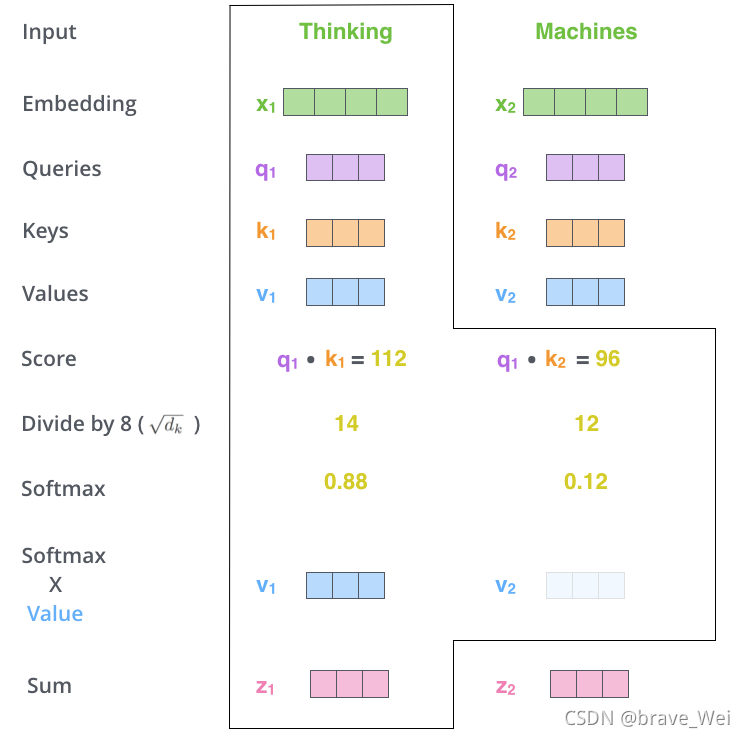
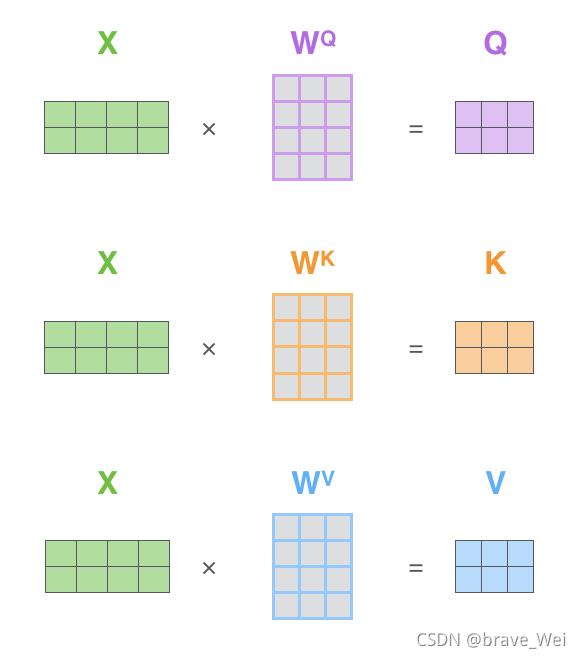
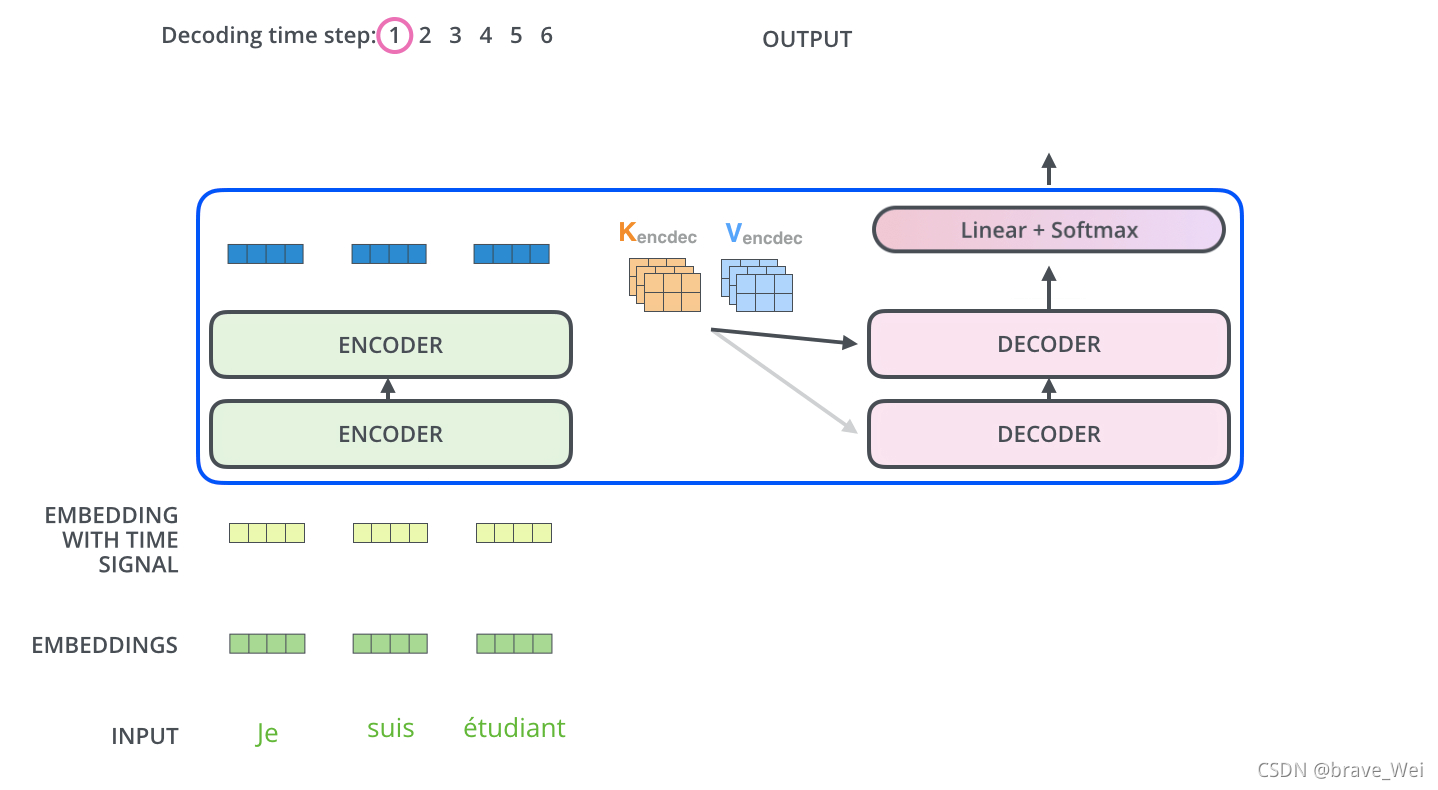
Lable={(xi,yi)},Unlabled={(xi)}.并且数量上,L< 单独使用有标记样本,我们能够生成有监督分类算法 单独使用无标记样本,我们能够生成无监督聚类算法 两者都使用,我们希望在1中加入无标记样本,增强有监督分类的效果;同样的,我们希望在2中加入有标记样本,增强无监督聚类的效果. 一般而言,半监督学习侧重于在有监督的分类算法中加入无标记样本来实现半监督分类.也就是在1中加入无标记样本,增强分类效果. SOTA State of The Art 在该领域最先进的模型 SOTA model:State-Of-The-Art model,是指在该项研究任务中,对比该领域的其他模型,这个是目前最好/最先进的模型。 SOTA result:State-Of-The-Art result,一般是说在该领域的研究任务中,此paper的结果对比已经存在的模型及实现结果,此Paper的模型具有最好的性能/结果。 BERT模型:BidirectionalEncoder Representations from Transformer 字向量+文本向量+位置向量(字词在不同位置的语义有差别,加上一个向量便于区分) fine-tunning范式 数据增强 EDA 同义词替换和回译 Self-attention Transformer模型 相当于一个黑匣子,将input的一种语言经过黑匣子转换output另一种语言 Transformer里面每个Encoders(input)分别有6个encoder,每个Decoders里面有6个Decoder、 encoder-decoder模型(编码-解码模型)按照我自己的理解encoder会把输入的信息编码成固定大小的向量,这个过程可能会对信息有一定的压缩损失。 每个encoder的结构一样,里面有两个子层Feed Forward Neural Network和Self-Attention,encoder的input首先通过self-attention层然后该层输出到Feed Forward Neural Network(前馈神经网络) 关于Transformer模型这篇文章写得非常详细非常好,我的整个理解也基于此,大家可以进去看看英文原版,细节满满:The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time. Self-attention是Transformer模型中一非常重要的部分。 self-attention layer: a layer that helps the encoder look at other words in the input sentence as it encodes a specific word.用来帮助encoder找到输入语句中的其他单词。 Decoder也有那两层,不过还有一个encoder-decoder attention,不像那两层是基于multi-head attention layer的,它是用来帮助输出句子相关的部分(类似于seq2seq模型),这层的重点是masking,masking的作用是防止在训练的时候使用未来输出的单词。第一个单词是不能参考第二个单词的生成结果的。 Masking就会把这个信息变成0, 用来保证预测位置 i 的信息只能参考比 i 小的输出。 ransformer中的每个Encoder接收一个512维度的向量的列表作为输入,然后将这些向量传递到‘self-attention’层,self-attention层产生一个等量512维向量列表,然后进入前馈神经网络,前馈神经网络的输出也为一个512维度的列表,然后将输出向上传递到下一个encoder。 每个位置的单词首先会经过一个self attention层,然后每个单词都通过一个独立的前馈神经网络(这些神经网络结构完全相同)。 Self-attention 从每个Encoder的输入向量(每个单词)上创建三个向量:Query、Key、Value 1.Score计算 2.Divide by 8( 3.SOFTMAX 4.Softmax X Value 5.Sum 经过以上计算得到Self-attention层的输出,具体计算原理在此不深究。 上图是self-attention的矩阵计算原理 接下来看看解码器端Decoder 关于Self-attention中的encoder还有很多优化在此不赘述,论文里很详细。 Decoder主要是对输入向量的k和v进行操作解码 ,里面的层次和encoder差不多,不过里面有一个attention层帮助Decoder专注于输入句子中对应的词,类似于seq2seq model。 UDA大致分为两部分 fine-tuning和Evaluatio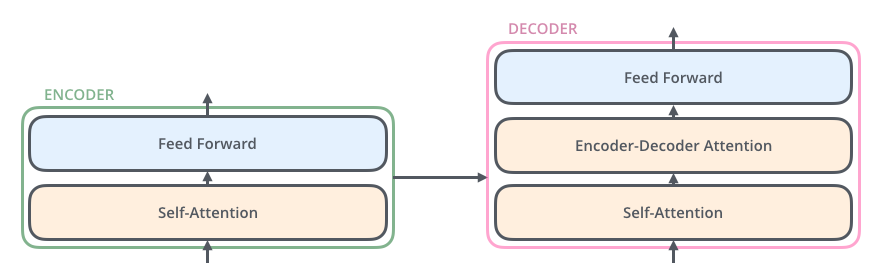
)
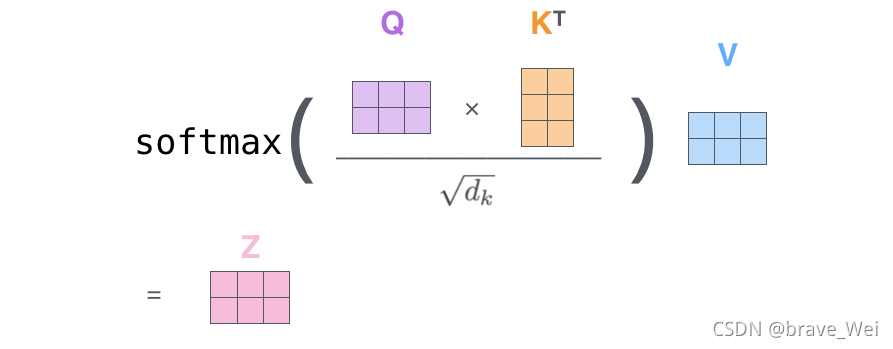
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!