Lucene,ES全文检索
Lucene 全文检索核心包(适用中小型项目)
ES/Solr是对Lucene封装的检索工具(适用大型项目)
一、Lucene的核心原理
创建索引,搜索索引
步骤:(1):先从数据库或者文档中采集相关数据
(2):创建相关的索引,建立索引库
(3):用户查询的时候,就去搜索相关的索引
(4):查出来后进行数据展示
如图所示: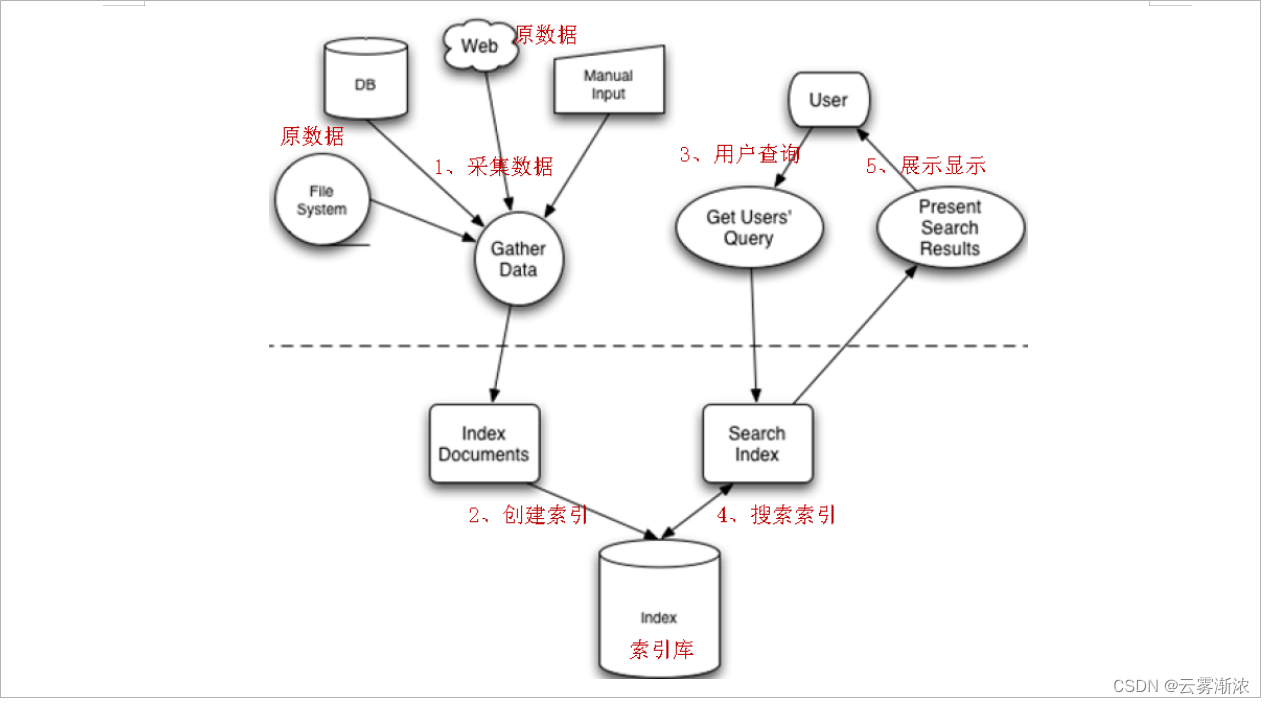
二、创建索引的步骤
如图所示:
根据相关条件,形成倒排索引文档,如图所示: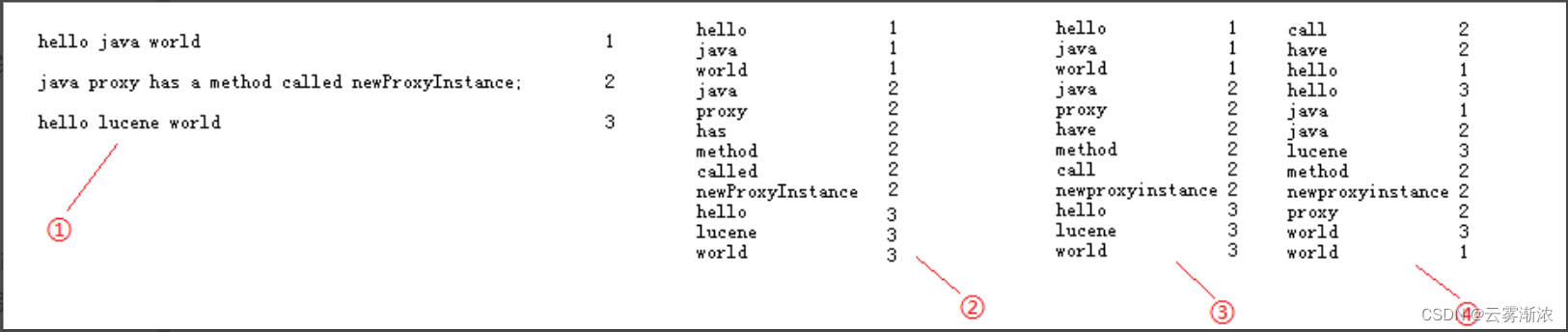
用户搜索索引的过程:
(1):用户输入关键字
(2):在倒排索引文档查询到相关词汇
(3):根据后面的索引去数据区查询到数据
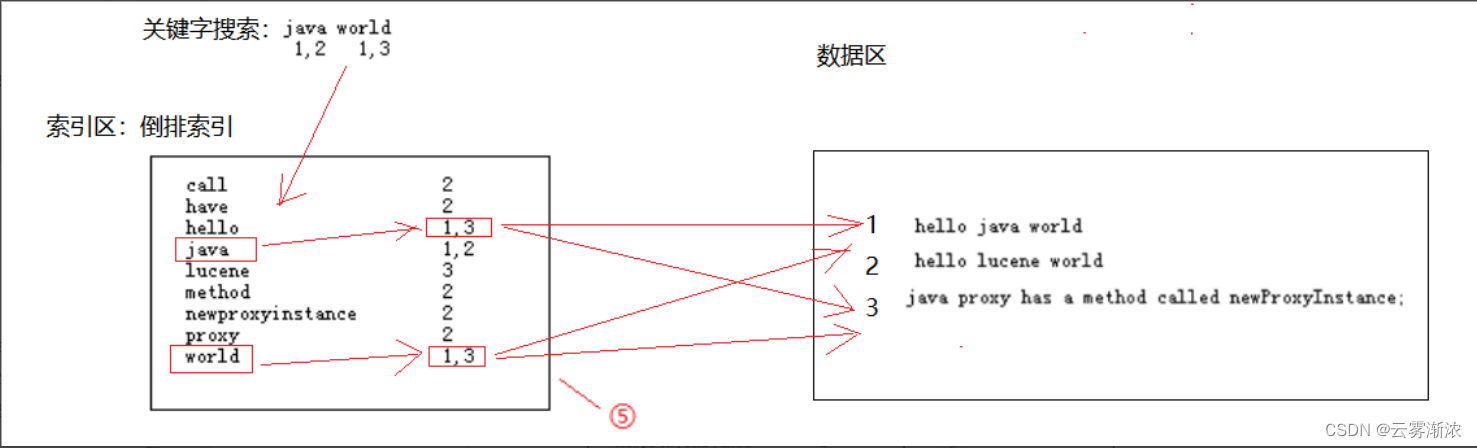
三、ES的文档CRUD操作
(1)添加文档
POST index/type/
{
JSON,文档内容
}
--解释---------------------------------------
PUT 索引库/文档类型/
{
JSON格式,文档原始数据
}
没有指定文档ID,ES会自动生成ID
举例:PUT crm/user/11
{
"id":11,
"username":"zs",
"age":18,
"name":"zs",
"sex":1,
"join_date": 1584092062348
}
(2)获取文档
GET 索引库/类型/文档ID
(3)修改文档
整体修改:会把ES中的数据全部覆盖,即age字段会消失
PUT {index}/{type}/{id}
{
"id":11,
"username":"zs"
}
局部修改:只会修改id,和username字段,age字段不会作任何改变
POST /crm/user/123/_update
{
"doc":{
"id" : 11,
"username": "xx"
}
}
(4)删除文档
DELETE {index}/{type}/{id}
四、DSL查询和过滤
什么是DSL查询?DSL查询是由ES提供丰富且灵活的查询语言叫做DSL查询(Query DSL),它允许你构建更加复杂、强大的查询
举例:
GET /crm/user/_search
{
"query" : {
"match" : {
"username" : "Hello Java"
}
}
}
match如同:where username = hello or username = java
term如同:where username = "Hello Java
-
query : 查询,所有的查询条件在query里面
-
bool : 组合搜索bool可以组合多个查询条件为一个查询对象,这里包含了 DSL查询和DSL过滤的条件
-
must : 必须匹配 :与(must) 或(should) 非(must_not)
-
match:分词匹配查询,会对查询条件分词 , multi_match :多字段匹配
-
filter: 过滤条件
-
term:词元查询,不会对查询条件分词
-
from,size :分页
-
_source :查询结果中需要哪些列
-
sort:排序
(1) DSL过滤
需要模糊查询的使用DSL查询 ,需要精确查询的使用DSL过滤,在开发中组合使用(组合查询) ,关键字查询使用DSL查询,其他的都是用DSL过滤。
(2)查询方式
1.全匹配
GET _search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": {
"term": {
"name": "zs1"
}
}
2.标准查询
match: match一般只用于全文字段的匹配与查询,一般不用于过滤。
{
"query": {
"match": {
"fullName": "Steven King"
}
}
}
multi_match 查询允许你做 match查询的基础上同时搜索多个字段
{
"query": {
"multi_match": {
"query": "Steven King",
"fields": ["fullName", "title"]
}
}
}
term:理解为等值查询,字符串,数字等都可以使用它,把查询的内容看成一个整体去检索ES库
"filter": {
"term": {
"username": "Steven King"
}
}
range:过滤允许我们按照指定范围查找一批数据
"range": {
"age": {
"gte": 20,
"lt": 30
}
上例中查询年龄大于等于20并且小于30。
prefix:和term查询相似,前匹配搜索不是精确匹配,而是类似于SQL中的like ‘key%
"query": {
"prefix": {
"fullName": "王"
}
}
wildcard:通配符搜索
"query": {
"wildcard": {
"fullName": "倪*华"
}
}
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!