python使用werobot进行微信公众号开发中的图片处理
python使用werobot进行微信公众号开发中的图片处理
前言
本人小白,最近有兴趣研究一下python微信公众号开发。关于服务器的配置教程有许多,这里暂时就不放出来了(我自己本打算搞内网穿透但是最后没搞定,还是租了阿里云的服务器)。并且网上也有好多实现“复读机”功能的代码,就是你发送什么文本消息或者图片消息,公众号就回复和你发的一模一样的消息,这实际上对发送的消息没有处理的。关于本文介绍的图片处理的部分,微信开放文档中介绍过于理论,没有给出具体代码,而且[werobot](https://werobot.readthedocs.io/zh_CN/latest/)文档中也只给出了函数的用法,也没有很详细,百度上也没有搜到具体的实现方式。所以我写这篇博客记录一下我自己研究的这一过程吧一、werobot实现文字复读机
werobot实现复读机这个代码在werobot文档(链接上面给出了)是给出来了的,我贴出来主要是对比后面处理的部分。
import werobotrobot = werobot.WeRoBot(token='你微信公众平台上自己设置的token')# @robot.text 修饰的 Handler 只处理文本消息
@robot.text
def echo(message):return message.content# 让服务器监听在 0.0.0.0:80
robot.config['HOST'] = '0.0.0.0'
robot.config['PORT'] = 80
robot.run()
二、图片处理
在微信开放文档中,有关于图片消息xml的说明,其中最重要的是PicUrl和MediaId。PicUrl是这个图片的地址,我们如果对这个图片进行处理就必须从这个地址来获得图片加载到内存中,而MediaId是在微信服务器中,图片消息的唯一标识,每一个图片都有一个mediaid,服务器将图片发送给用户的方式就是发送mediaid。
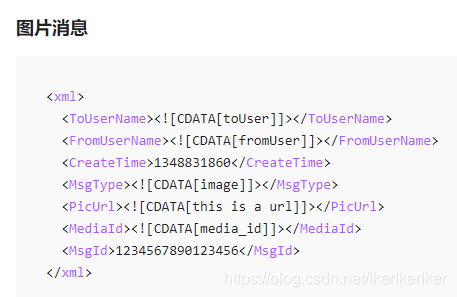
现在呢,如果你想什么都不做,把服务器接收到的图片原封不动地发回给用户,那么直接发送这个接收到的mediaid就好了。
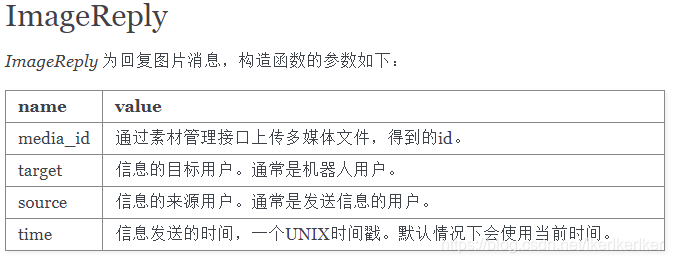
from werobot.replies import ImageReply@robot.image
def img(message):reply = ImageReply(message=message,media_id=message.MediaId)return reply
那么,现在问题出现了,如果对图片进行处理,那么mediaid就会变,处理后的图片的mediaid怎么获得?这时候要用到新增临时素材了

可以看到,函数的输入是媒体类型(图片类型)和要上传的文件(处理后的图片),返回的json包里就有mediaid。这里有个问题很重要,当初我搜了好久才解决,就是要上传的文件必须是File-object类型的!最后将获得到的mediaid发送给用户就行了。并且有关素材的操作是需要access_token的,不过在werobot模块里,配置好你的APP_ID和APP_SECRET就好了,access_token好像是会自动获取。还有,记得在公众号后台把你的服务器IP加到白名单里去,不然也会报错。
完整代码:
import werobot
import requests
import cv2
import numpy as np
from io import BytesIO,BufferedReader
from PIL import Image
from werobot.replies import ImageReplyrobot = werobot.WeRoBot(token='你的token')
robot.config["APP_ID"]="你的APP_ID"
robot.config["APP_SECRET"]="你的APP_SECRET"
client=robot.clientdef ps(message):#part1req = requests.get(message.img)bytes_stream = BytesIO(req.content)img = Image.open(bytes_stream) #PIL图片#part2img = cv2.cvtColor(np.asarray(img),cv2.COLOR_RGB2BGR)gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) #转灰度图inv = 255 - gray #取反ksize = 15sigma = 50blur = cv2.GaussianBlur(inv,ksize =(ksize,ksize),sigmaX = sigma,sigmaY = sigma) #高斯滤波res = cv2.divide(gray,255-blur,scale = 255)#part3ret, img_encode = cv2.imencode('.jpg', res)str_encode = img_encode.tobytes() # 将array转化为二进制类型f4 = BytesIO(str_encode) # 转化为_io.BytesIO类型f4.name = 'asdasdasd.jpg' #给他命个名,不命名会报错f5 = BufferedReader(f4) # 转化为_io.BufferedReader类#part4return_json = client.upload_media("image",f5)mediaid = return_json["media_id"]return mediaid@robot.image
def img(message):mediaid = ps(message)reply = ImageReply(message=message,media_id=mediaid)return reply# 让服务器监听在 0.0.0.0:80
robot.config['HOST'] = '0.0.0.0'
robot.config['PORT'] = 80
robot.run()
中间ps函数包含四个部分。
part1是将url下载下来并用pillow打开加载到内存中
part2是我参考的一个彩色图像转素描的简单处理,因为是用opencv实现的,所以转cv图片处理了
part3是将cv图像转成File-object类型用于素材上传
part4进行素材上传并获取新素材的mediaid
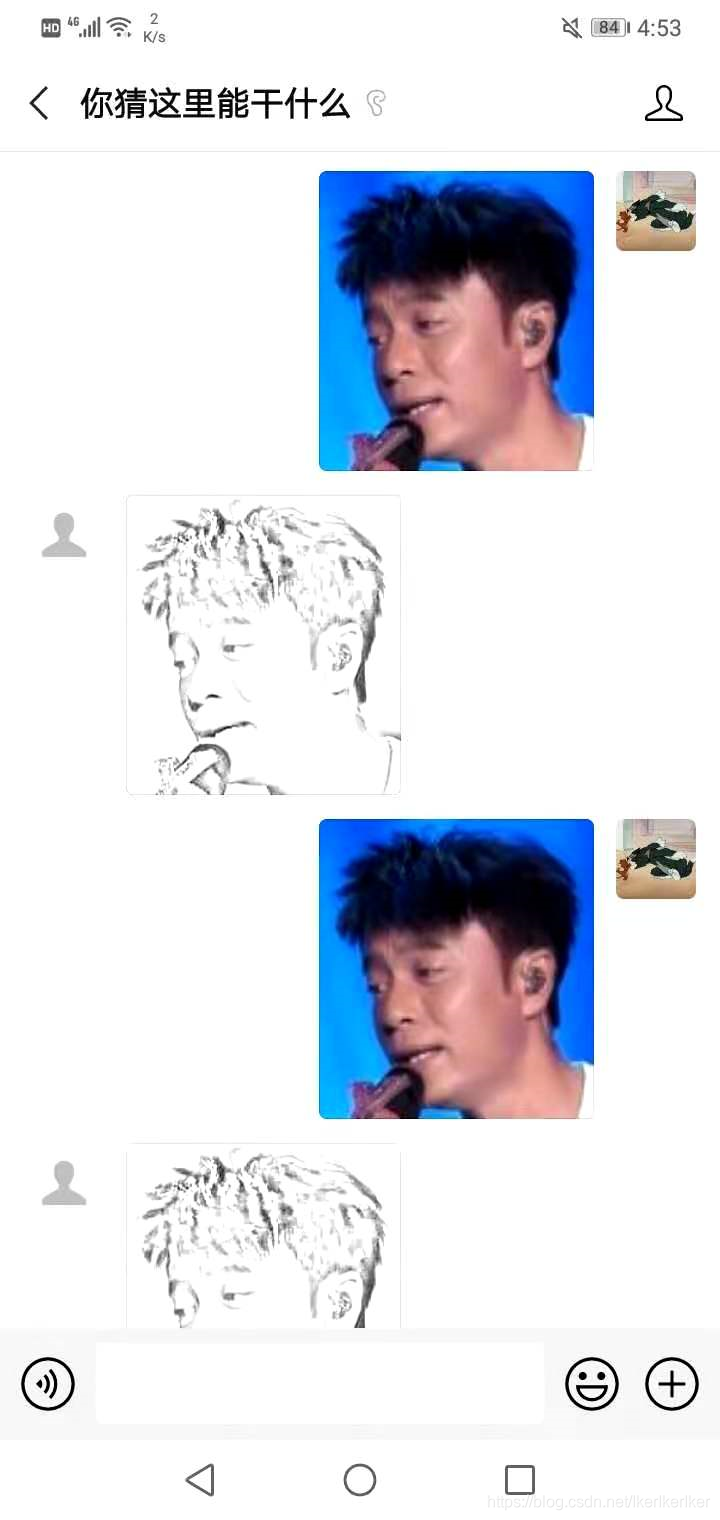
测试效果如图
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!