电商锦囊词推荐设计
导读
锦囊词推荐是电商搜索中为了收敛用户意图,帮助用户快速找到用户真正想要搜索的东西而设计的一个词推荐功能。比如下图所示,当用户搜索iphone 13 case,看了很多商品之后还不点击,则为用户推荐一些与之相关的词。
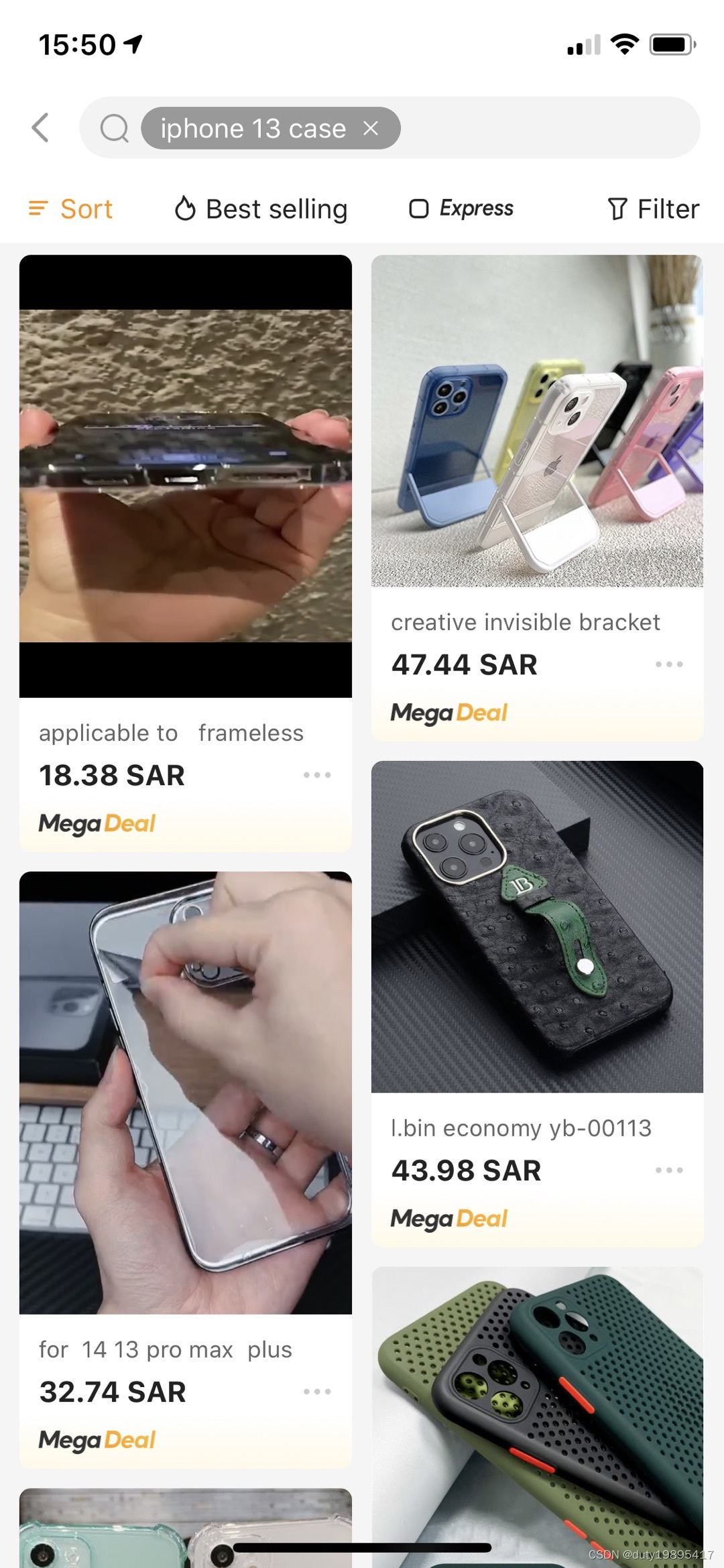
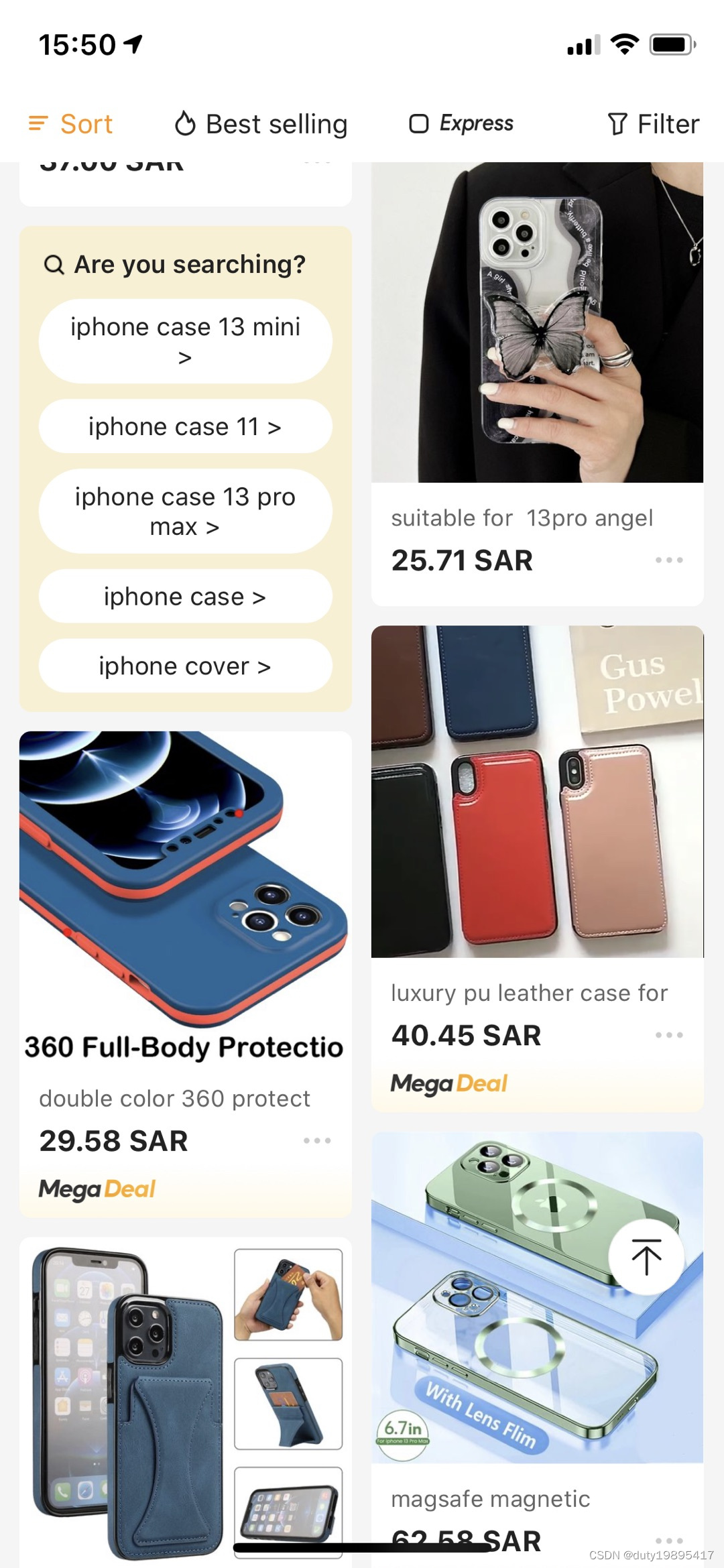
实际效果如图
假设用户在一个session内的搜索query之间是有相关性的,假设至少前后n(n可以等于3)个query之间关联更加密切,因此假如把每个query看成是一个word,目标就变成找到某个word最相似的word。
在NLP领域要计算word之间的相似性方法都是先将每个word映射为一个向量,然后通过计算向量之间的距离,常用余弦距离计算。如果把每个query当做一个item,则可以用推荐的思路通过协同过滤,swing算法等来做。
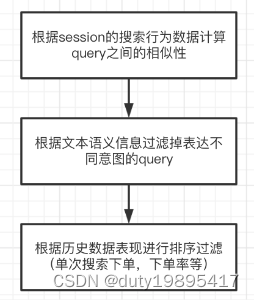
算法流程图
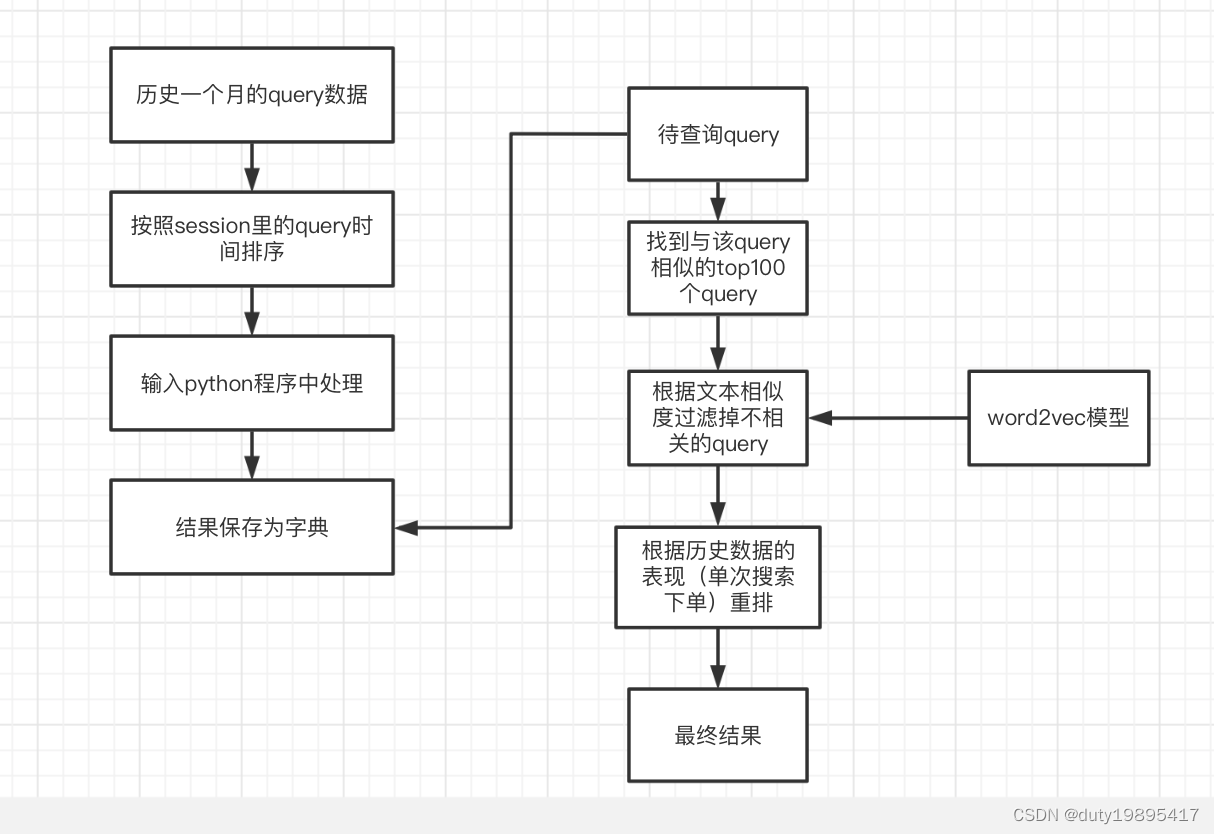
工程流程图
模型
word2vec
将每个query看成一个word,一个session按照时间排序成一个sentence,通过word2vec训练query的向量,然后计算query之间的距离
glove
与word2vec类似,只是算法原理不同,在当前场景下,效果比word2vec要好
序列预测
把一个session内的query当做一个序列,根据历史数据训练一个序列预测模型,如seq2seq。
滑窗统计共现性
通过一个大小为N的滑动窗口,统计窗口内query之间的共现性,最终的query之间的距离即为共现次数
目前看,第四种方法效果最好,比较符合预期
当然也可以尝试协同过滤的方法,跟第四种方法其实本质差不多。
query结果剪枝
因为通过模型学习或者通过统计难免会有出现一些两个query从语义去看没有任何关系,但是相似度却很高的情况,如iphone 13和ps5;这是由数据本身决定的,确实有很多用户搜索了iphone 13的同时也会搜索ps5。这个时候为了达到业务想要的效果,比如业务要求搜索手机,出现的都是跟手机相关的词,因此需要对这种case进行剔除。当然如果你的业务对这个没有要求,那其实也可以不用剔除,因为搜索手机,推荐ps5其实可以达到一种多样性的效果。
剔除方法
根据query1和query2之间本身的语义相似度去度量。方法也很多,可以根据tfidf计算相似度;你可以把每个query当成一个序列,训练出一个词向量模型,然后通过词向量平均计算query相似度,过滤掉相似度很低的query。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!