经典的深度卷积网络架构(一)
文章目录
- 经典的深度卷积网络架构(一)
- LeNet
- AlexNet
- VGG系列
- VGG-16架构图
- DarkNet系列
- DarkNet Reference
- DarkNet-19
- 残差网络:ResNet
- Inception模组
- XCeption架构
- DenseNet
经典的深度卷积网络架构(一)
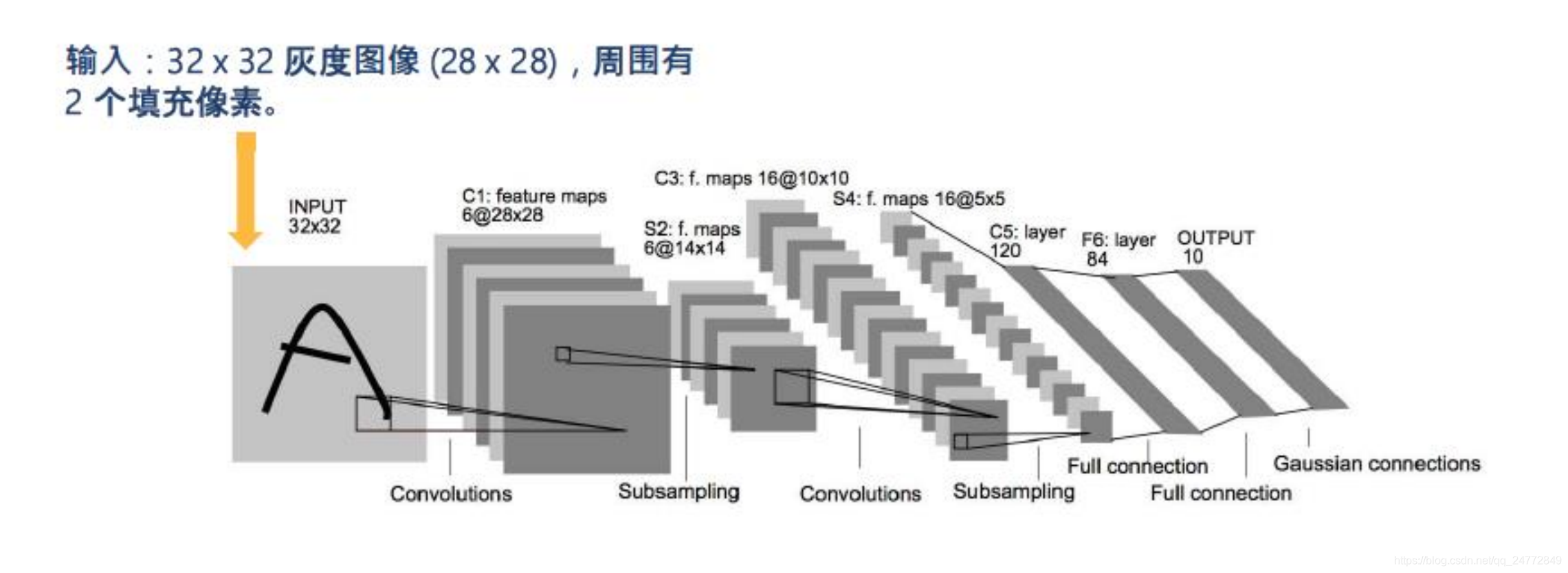
LeNet
1998年,LeCun提出LENet,并成功应用于美国手写数字识别,测试误差小于1%。卷积层、pooling层、全连接层,这些都是现代CNN网络的基本组件。
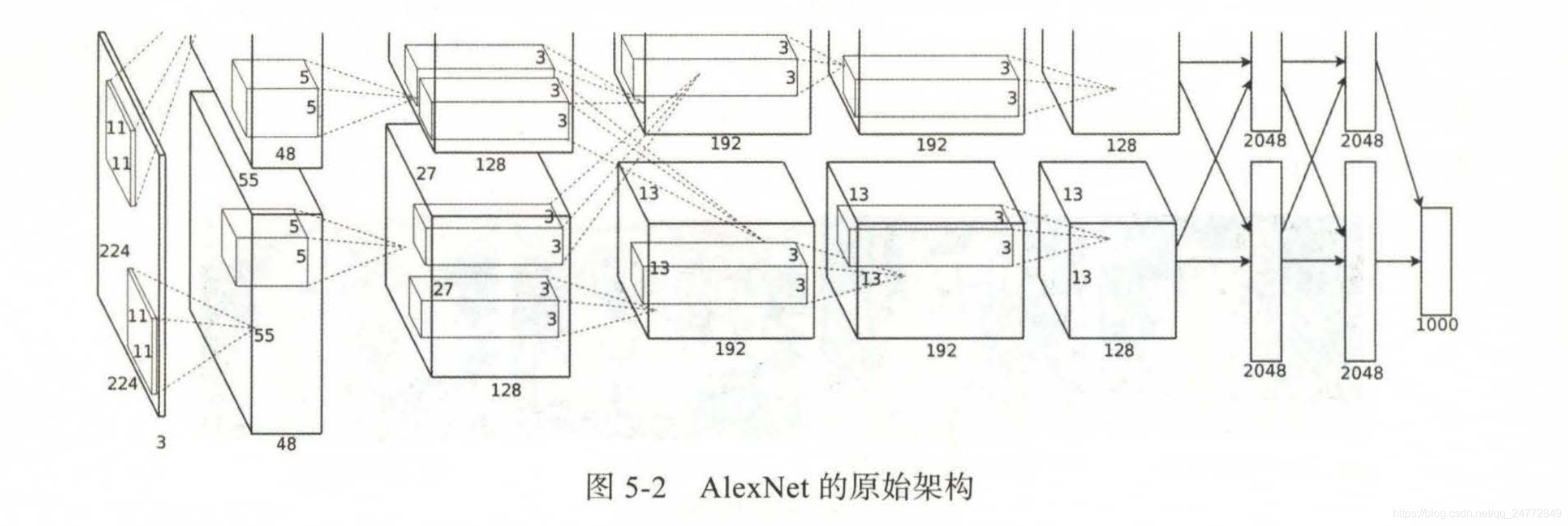
AlexNet
AlexNet的原始论文来自Hinton带领的多伦多大学团队。由于当时的GPU能力有限,其中使用了双GPU训练,且将网络也相应切成两部分,两部分只在部分层之间沟通,如下图
-
采用非线性激活函数Relu,比饱和函数训练更快,而且保留非线性表达能力,可以训练更深层的网络
-
采用数据增强和Dropout防止过拟合,数据增强采用图像平移和翻转来生成更多的训练图像,Dropout降低了神经元之间互适应关系,被迫学习更为鲁棒的特征
-
采用GPU实现,采用并行化的GPU进行训练,在每个GPU中放置一半核,GPU间的通讯只在某些层进行,采用交叉验证,精确地调整通信量,直到它的计算量可接。
VGG系列
VGG是AlexNet的重要改进,VGG论文中的架构如下
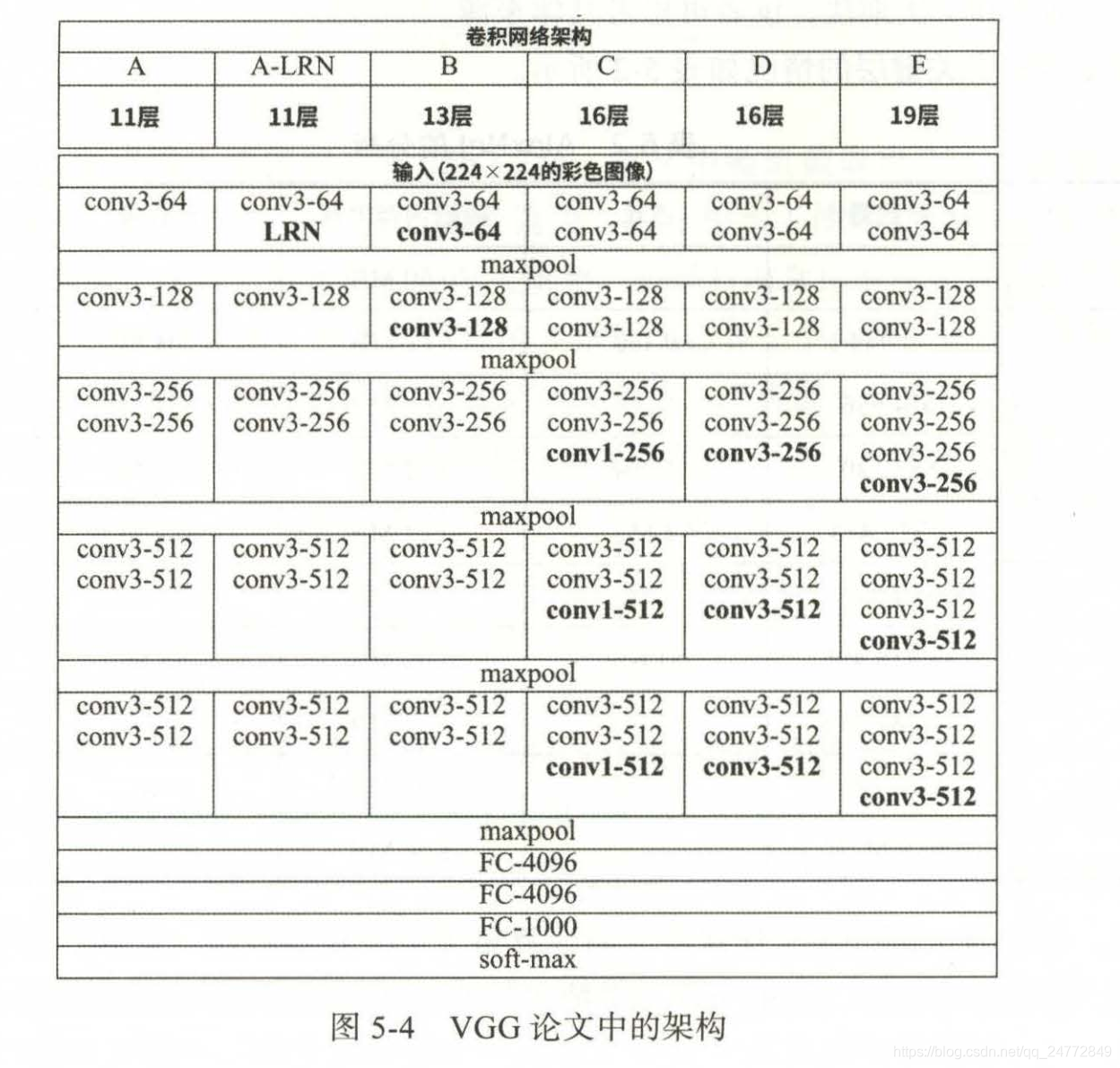
- 模型中卷积核大小均为3X3,步长为1,同时加入1个像素外衬,模型C 中还使用了1X1卷积
- 有最大池化层负责缩小图像,大小和步长都为2.
- 随着图像的缩小,通道数增多,这有助于保留更多信息
- 非线性全部使用Relu
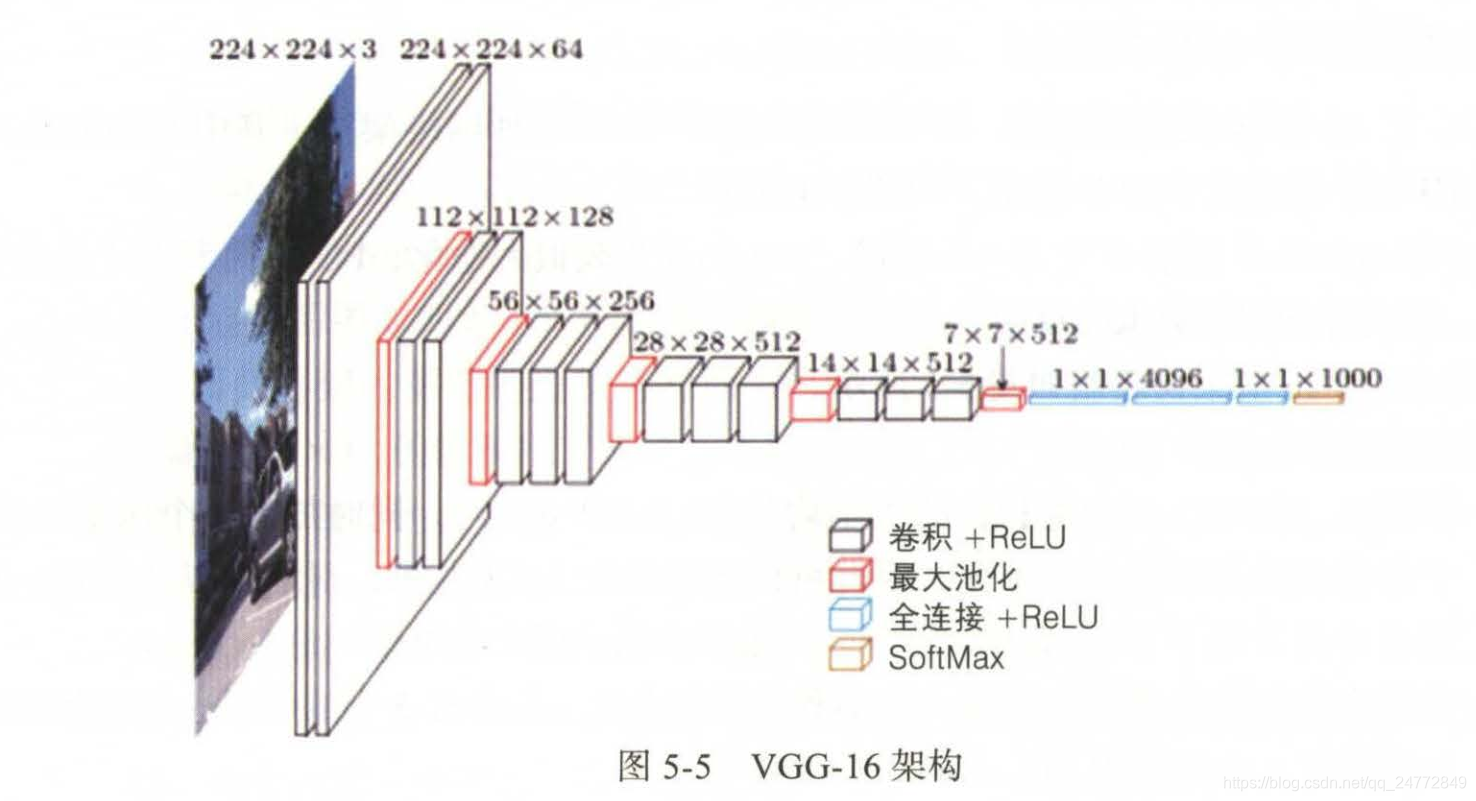
VGG-16架构图
DarkNet系列
- DarkNet Reference和DarkNet-19分别比AlexNet和VGG-16更快更准
- RESNet和DenseNet使用了残差结构,正确率更高,DarkNet系列没有使用残差结构,运行速度更快
DarkNet Reference
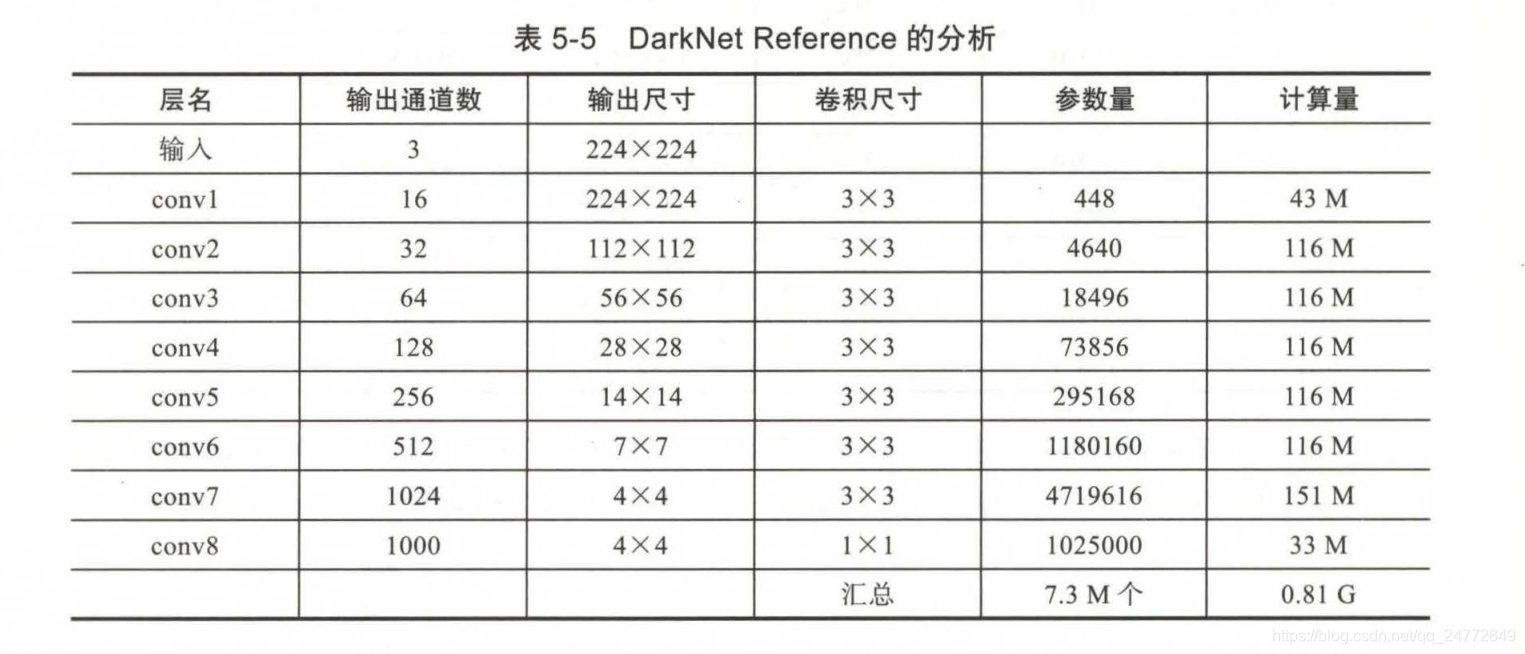
最后将conv8输出的1000个4X4的图像,经全局平均池化和SoftMax,直接变为1000个概率
其特点如下:
卷积层
-
所有的3X3卷积都带1个像素外衬,因此不改变图像尺寸
-
所有非线性都使用Leaky Relu
-
除去最后的conv8外,在卷积后都有BN层
-
在conv1到conv6卷积后用最大池化缩小图像,大小和步长都为2,在conv6后的最大池化加1个像素外衬,使结果是4X4
DarkNet-19
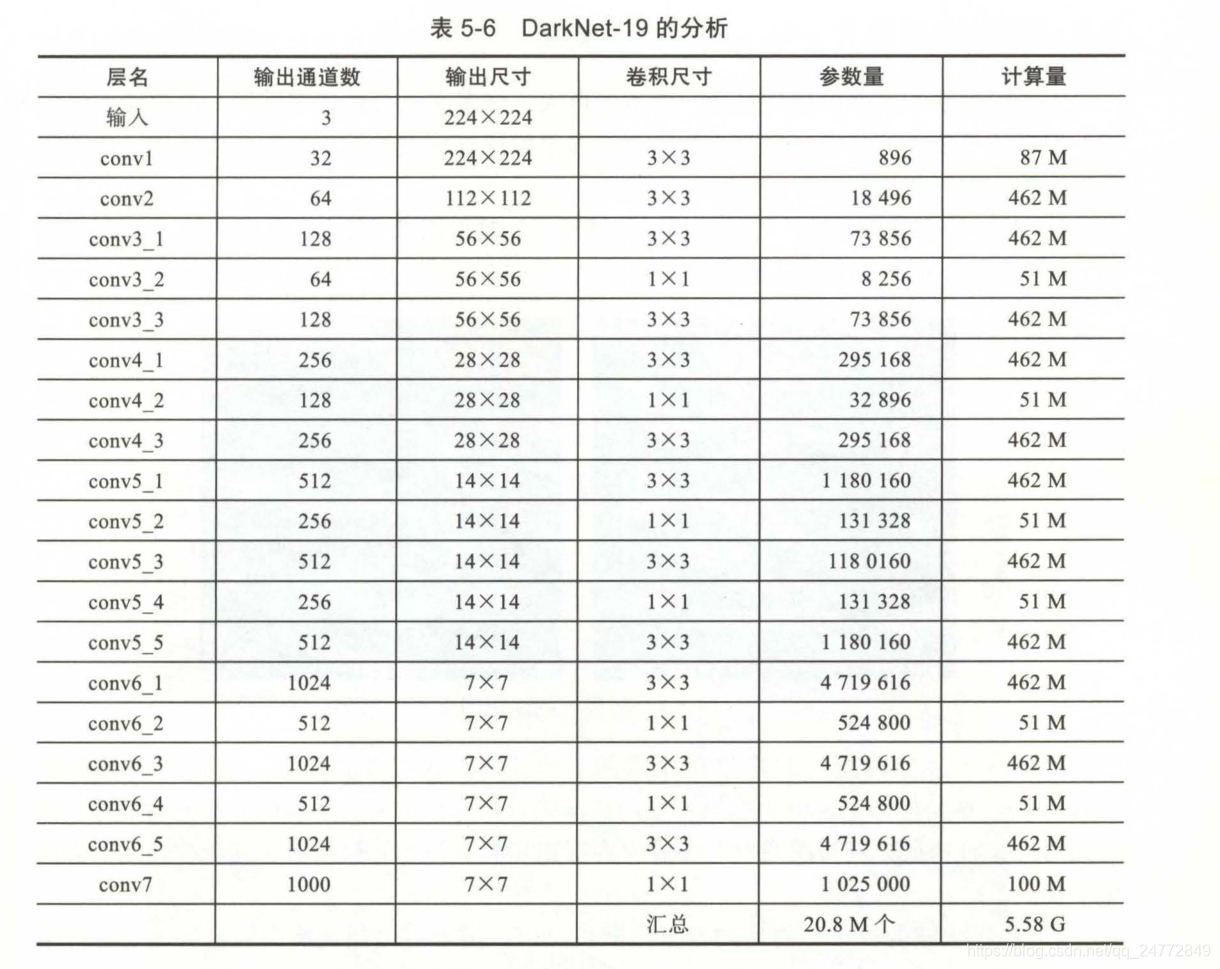
最后将conv7输出的1000个7X7图像,经全局平均池化和SoftMax,直接变为1000个概率
残差网络:ResNet
残差连接思想:
-
假设有一个网络M,它的输出是X。
-
给M加上一层变为M`,令新的输出是H(X)。
-
令H(X)=X,于是M`和M的输出就一模一样,性能相同。
-
更好的办法是令H(X)=X+F(X),只要求新的一层去学习F(X),这里的F(X)就称为残差。
残差连接已成为深度神经网络架构中的重要组成部分。
2015年的ResNet原始论文中,残差网络做法如下:
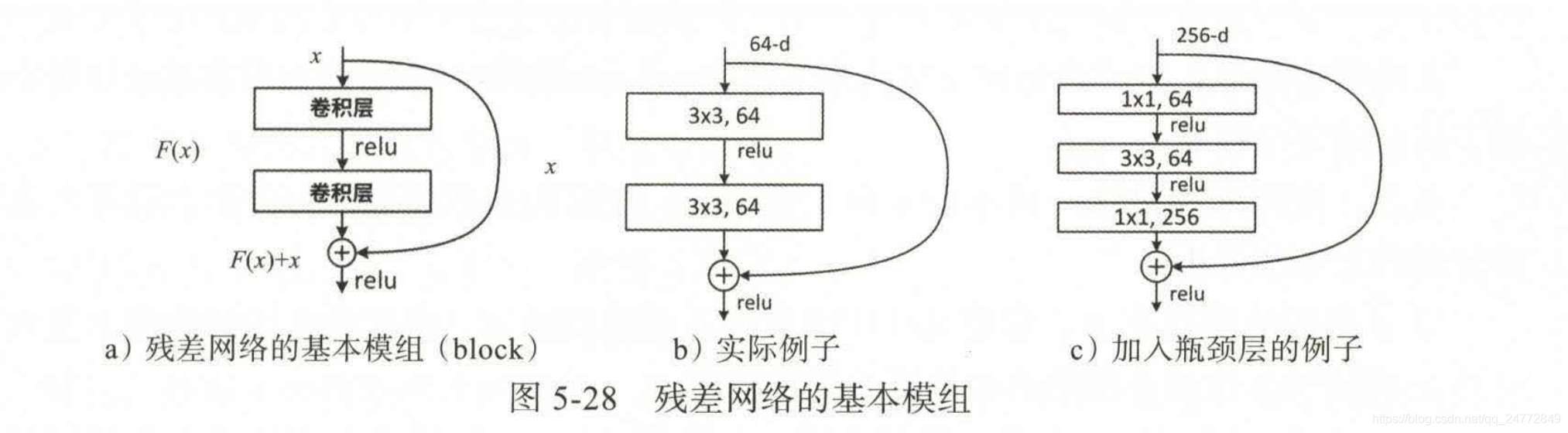
注意,在ResNet的原始论文中,将Relu非线性激活放置在X+F(X)之后,那么,即使F(X)=0,X仍然会经过一次Relu。
2016年后续论文中《Identity Mappings in Deep Residual Networks》,提出了多种网络组合方式如下
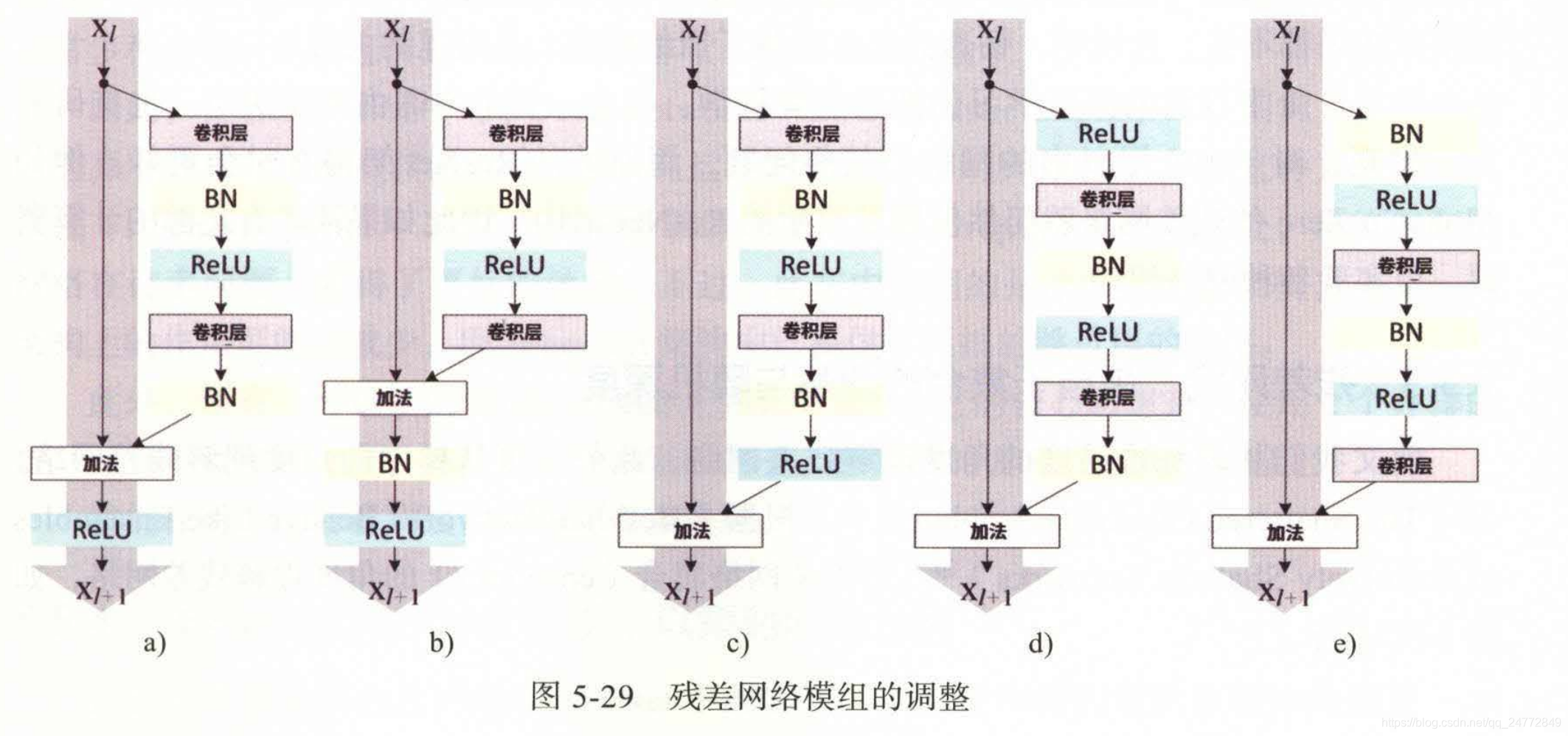
上述几种架构,运用在110层和164层网络后,在CIFAR-10的错误率如下
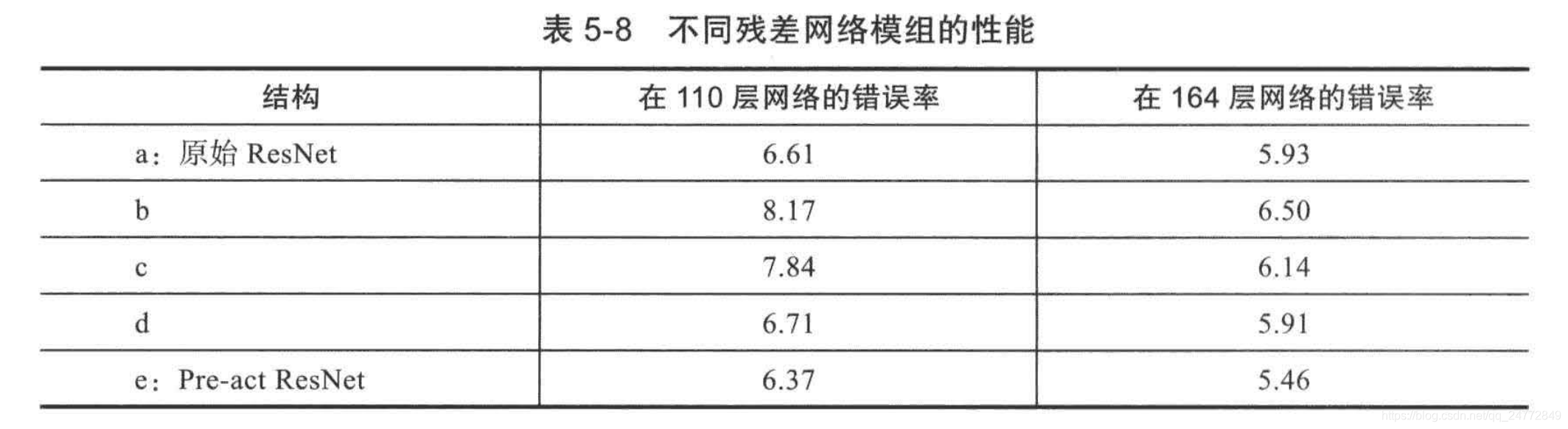
e架构错误率最低,左通路上没有Relu层,实现了信息的完全畅通。
后续的研究《Deep Networks with Stochastic Depth》,研究人员在训练时选择有随机的几率直接跳过部分层(在运行时仍然会使用所有层),并称这种方法为随机深度。
此外,还有一种最新的Shake-Shake正则化方法,它的核心思想是,使用2个并排的层,并且不直接跳过层,而是随机加入衰减因子。
Inception模组
基于一个想法:不同大小的特征,可能需要不同大小的滤波器。
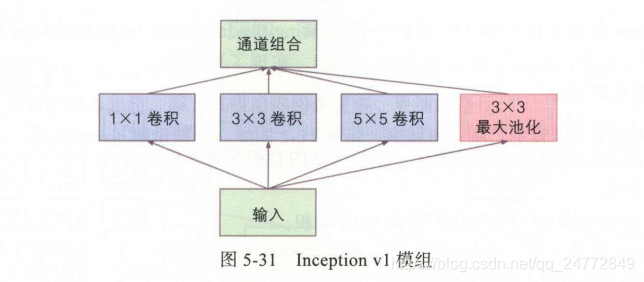
举例说明这里的通道如何组合,假设本层的输入是X,将X通过 1X1卷积生成了A张图像,再将X通过3X3卷积生成了B张图像,再将X通过5X5卷积生成了C张图像,再将X通过3X3最大池化生成D张图像,如果这些图像的尺寸一致,就可以将它们组合在一起,成为 A+B+C+D 张图像。
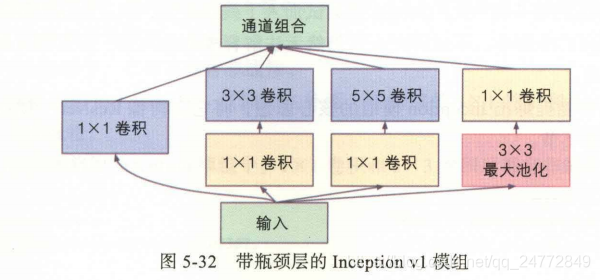
上述架构的通道数会快速增长,可以加入1X1卷积作为瓶颈层,如下图所示
XCeption架构
借鉴了Inception模组的核心思想,在模组内构建更多、更细的路径。
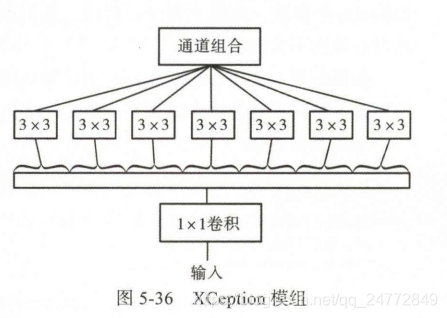
- 每个3X3卷积核都独立运作在各自的通道中,通道混合就完全由1X1卷积核负责,节省大量参数,提高运算速度。
- 如果要加入非线性,只能加在外面,在内部的1X1卷积核3X3卷积之间没有非线性,过多的非线性会阻碍信息的流动。
XCeption利用了可分卷积的操作,减少了参数量
如果输入通道为64,输出通道为128,忽略偏置
那么采用普通的3X3卷积层,参数量是64X128X3X3=73728
如果采用深度可分卷积,参数量是64X3X3+64X128X1X1=8768
DenseNet
在传统的ResNet中,将不同的路径相加;而在DenseNet中,将不同的路径组合
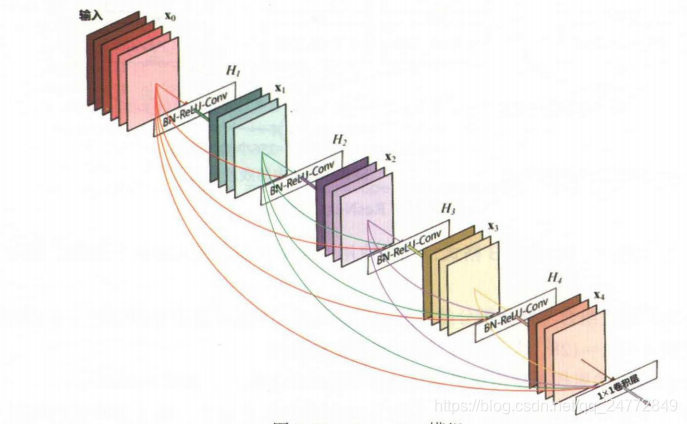
- 输入x0是5个通道,经过H1层的BN-ReLu-Conv操作,输出是具有4个通道的x1
- 将x0和x1组合为9个通道,经过H2层的BN-Relu-Conv操作,输出是具有4个通道的x2
- 将x0、x1和x2组合为13个通道,经过H3层的BN-ReLu-Conv操作,输出是具有4个通道的x3
- 以此类推,最终输出21个通道,在经1X1卷积将通道缩小。
最终的网络架构十多个单元模块的串联

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!