Spark Streaming 实验:广告实时统计
一、实验描述
实验数据通过scala代码生成,每当kafka要发送数据时,调用数据生成方法循环生成若干条数据存入ListBuffer,每条数据的格式如下:
时间戳 省份 城市 用户ID 广告ID
实验主要完成三个需求,即
(1) 实现实时的动态黑名单机制: 把每天对某个广告点击超过100次的用户拉黑,黑名单用户ID存入Mysql
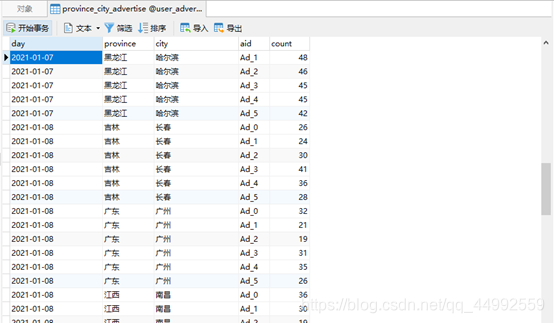
(2) 实时统计每天各省市各广告的点击总流量,并将其存入Mysql
(3) 最近1分钟广告总点击量,每10s计算一次,并通过html展示
二、实验分析
需求一:
实现实时的动态黑名单机制: 把每天对某个广告点击超过100次的用户拉黑,黑名单用户ID存入Mysql。主要流程如下:
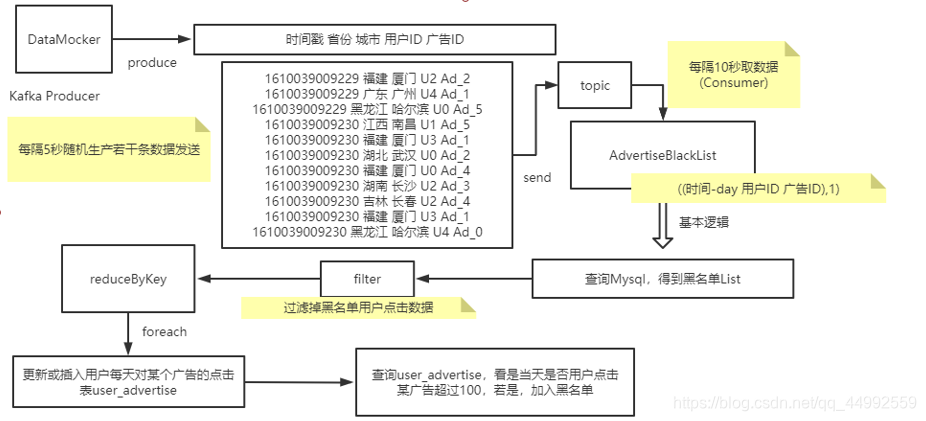
需求二:
实时统计每天各省市各广告的点击总流量,并将其存入Mysql。单个批次内对数据按照天、省份、城市、广告ID聚合统计。结合Mysql数据与当前批次数据更新原有Mysql数据表(province_city_advertise(day,province,city,aid,count),其中day、province、city、aid构成主键)的数据(insert or update)。
需求三:
最近1分钟广告总点击量,每10s计算一次。根据分析,需求实现需要有基于滑动窗口的有状态转换。大致示例如下,
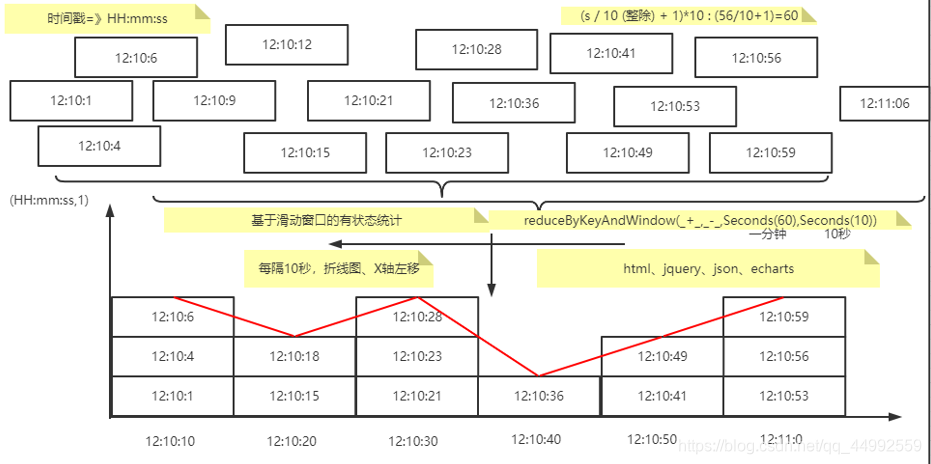
其中,Kafka生产者产生的数据包含的时间戳先format为HH:mm:ss,由于是每10s统计一次,故而还需要对HH:mm:ss转换(如12:10:45=>12:10:50),公式如下:
9s(1-10) => 10s
13s(11-20) => 20s
24s(21-30) => 30s
32s(31-40) => 40s
48s(41-50) => 50s
56s(51-60) => 60s(0)
(s / 10 (整除) + 1)*10 : (56/10+1)=60
三、实验代码
DataMocker.scala
import java.utilimport org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}import scala.collection.mutable.ListBuffer
import scala.util.Random// Kafka Producer// spark-submit --driver-class-path /usr/local/spark/jars/*:/usr/local/spark/jars/kafka/* --class DataMocker ./target/scala-2.12/sparkstreamingexperiment_2.12-0.1.jar
object DataMocker {def mockData(): ListBuffer[String] ={val list = ListBuffer[String]()val provinceList = List[String]("江西","辽宁","浙江","广东","湖南","湖北","吉林","黑龙江","福建")val cityList = List[String]("南昌","沈阳","杭州","广州","长沙","武汉","长春","哈尔滨","厦门")val length = provinceList.lengthval random = new Random()for(i <- 1 to random.nextInt(100)){val idx = random.nextInt(length)val province = provinceList(idx) // 省份val city = cityList(idx) // 城市val uid = "U"+random.nextInt(6) // 用户IDval aid = "Ad_"+random.nextInt(6) // 广告ID +new Random().nextString(3)+"_"println(s"${System.currentTimeMillis()} $province $city $uid $aid")list.append(s"${System.currentTimeMillis()} $province $city $uid $aid")}list}def main(args: Array[String]): Unit ={val props = new util.HashMap[String, Object]()props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "master:9092")props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer")props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer")val producer = new KafkaProducer[String, String](props)var ite = 1while(true){ite = ite + 1val advertiseUsers = mockData()advertiseUsers.foreach(elem => {val record = new ProducerRecord[String, String]("advertise-user", null, elem)producer.send(record)})Thread.sleep(5000)println(s"############${ite}##############")}}
}
MysqlUtil.scala
import java.sql.{Connection, DriverManager}object MysqlUtil {def getConnection: Connection ={// Class.forName("com.mysql.jdbc.Driver")val url = "jdbc:mysql://master:3306/user_advertise?useUnicode=true&characterEncoding=utf-8" // useUnicode=true&characterEncoding=utf-8val user = "root"val password = "Hive@2020"DriverManager.getConnection(url,user,password)}
}
AdvertiseBlackList.scala
import java.text.SimpleDateFormat
import java.util.Dateimport org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.{Seconds, StreamingContext}import scala.collection.mutable.ListBuffer// 实现实时的动态黑名单机制: 把每天对某个广告点击超过100次的用户拉黑,黑名单用户ID存入Mysqlcase class UserAdvertise(ts: String, user: String, advertise: String)object AdvertiseBlackList {def main(args: Array[String]): Unit ={val sc = new SparkConf().setMaster("local[*]").setAppName("AddUserToBlackList")val ssc = new StreamingContext(sc,Seconds(10))ssc.checkpoint("/user/hadoop/kafka/checkpoint")val kafkaParams = Map[String, Object]("bootstrap.servers" -> "master:9092","key.deserializer" -> classOf[StringDeserializer],"value.deserializer" -> classOf[StringDeserializer],"group.id" -> "neu","auto.offset.reset" -> "latest","enable.auto.commit" -> (true: java.lang.Boolean),"offsets"-> "")val topic = Array("advertise-user")val kafkaDataDS = KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](topic, kafkaParams),)val aus = kafkaDataDS.map(kafkaData => {val str = kafkaData.value()val strs = str.split(" ")UserAdvertise(strs(0),strs(3),strs(4))})val uAdClickDS = aus.transform(rdd => {// 1. 读取 Kafka 数据(用户对广告的点击浏览数据)后,验证用户ID是否在Mysql存储的黑名单用户表中val uidList = ListBuffer[String]()val conn = MysqlUtil.getConnectionval ps = conn.prepareStatement("select uid from black_list")val rs = ps.executeQuery()while(rs.next()){uidList.append(rs.getString("uid"))}rs.close()ps.close()conn.close()rdd.filter(data => {!uidList.contains(data.user)}).map(// 2. 若不在,则统计各用户点击各广告的次数并存入Mysqldata => {val day = new SimpleDateFormat("yyyy-MM-dd").format(new Date(data.ts.trim.toLong))val user = data.userval advertise = data.advertise((day,user,advertise),1)}).reduceByKey(_+_)})// 3. 存入Mysql之后对数据做校验,如果当日超过100次则将该用户加入黑名单uAdClickDS.foreachRDD(rdd => {rdd.foreachPartition(iter => {println("$$$$$$$$$$$$$$$$$$$$$$$$")val conn = MysqlUtil.getConnectioniter.foreach{case ((day, user, advertise), count) =>println(s"$day $user $advertise")var ps = conn.prepareStatement("""|select * from user_advertise|where day=? and uid=? and aid=?|""".stripMargin)ps.setString(1, day)ps.setString(2, user)ps.setString(3, advertise)var rs = ps.executeQuery()if (rs.next()) {val psA = conn.prepareStatement("""|update user_advertise|set count = count + ?|where day=? and uid=? and aid=?|""".stripMargin)psA.setInt(1, count)psA.setString(2, day)psA.setString(3, user)psA.setString(4, advertise)psA.executeUpdate()psA.close()} else {val psB = conn.prepareStatement("insert into user_advertise(day,uid,aid,count) values (?,?,?,?)")psB.setString(1, day)psB.setString(2, user)psB.setString(3, advertise)psB.setInt(4, count)psB.executeUpdate()psB.close()}ps = conn.prepareStatement("""|select * from user_advertise|where day=? and uid=? and aid=? and count>100|""".stripMargin)ps.setString(1,day)ps.setString(2,user)ps.setString(3,advertise)rs = ps.executeQuery()if (rs.next()) {val psC = conn.prepareStatement("insert into black_list(uid) value(?)") // on duplicate key update uid=?psC.setString(1, user)// psC.setString(2, user)psC.executeUpdate()psC.close()}ps.close()}conn.close()})})ssc.start()ssc.awaitTermination()}
}
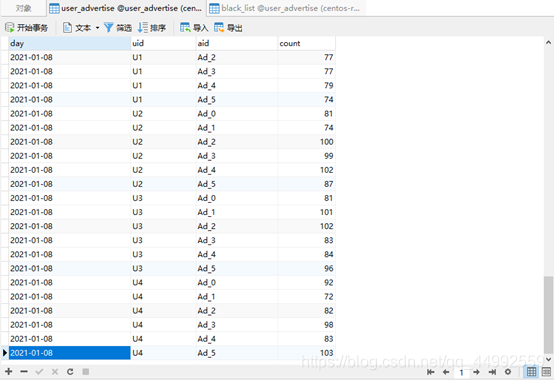
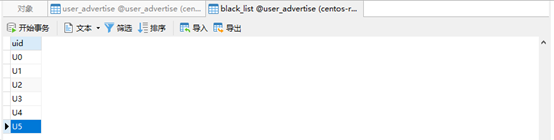
AdvertiseClickCount.scala
import java.text.SimpleDateFormat
import java.util.Dateimport org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies, Subscribe}
import org.apache.spark.streaming.{Seconds, StreamingContext}// 实时统计每天各省市各广告的点击总流量,并将其存入Mysqlcase class ProvinceCityAdvertise(ts: String, province: String, city: String, advertise: String)object AdvertiseClickCount {def main(args: Array[String]): Unit ={val sc = new SparkConf().setMaster("local[*]").setAppName("AddUserToBlackList")val ssc = new StreamingContext(sc,Seconds(10))ssc.checkpoint("/user/hadoop/kafka/checkpoint")val kafkaParams = Map[String, Object]("bootstrap.servers" -> "master:9092","key.deserializer" -> classOf[StringDeserializer],"value.deserializer" -> classOf[StringDeserializer],"group.id" -> "neu","auto.offset.reset" -> "latest","enable.auto.commit" -> (true: java.lang.Boolean),"offsets"-> "")val topic = Array("advertise-user")val kafkaDataDS = KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](topic, kafkaParams),)val adClickDS = kafkaDataDS.map(kafkaData => {val str = kafkaData.value()val strs = str.split(" ")ProvinceCityAdvertise(strs(0),strs(1),strs(2),strs(4))})// 单个批次内数据按照天聚合统计val reducedAdClickDS = adClickDS.map(data => {val day = new SimpleDateFormat("yyyy-MM-dd").format(new Date(data.ts.trim.toLong))val province = data.provinceval city = data.cityval advertise = data.advertise((day,province,city,advertise),1)}).reduceByKey(_+_)// 结合Mysql数据与当前批次数据更新原有Mysql数据(insert or update)reducedAdClickDS.foreachRDD(rdd => {rdd.foreachPartition(iter => {val conn = MysqlUtil.getConnectioniter.foreach{case((day,province,city,advertise),sum) =>val ps = conn.prepareStatement("""|insert into province_city_advertise(day,province,city,aid,count)|values (?,?,?,?,?) on duplicate key update count=count+?|""".stripMargin)ps.setString(1,day)ps.setString(2,province)ps.setString(3,city)ps.setString(4,advertise)ps.setInt(5,sum)ps.setInt(6,sum)ps.executeUpdate()ps.close()}conn.close()})})ssc.start()ssc.awaitTermination()}
}
AdvertiseClickNearlyMinute.scala
import java.io.{File, FileWriter, PrintWriter}
import java.text.SimpleDateFormat
import java.util.Dateimport org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies, Subscribe}import scala.collection.mutable.ListBuffercase class TimeAdvertise(ts: String, advertise: String)// 最近1分钟广告总点击量,每10s计算一次object AdvertiseClickNearlyMinute {def main(args: Array[String]): Unit ={val projectRoot: String = System.getProperty("user.dir")val file: String = projectRoot + "/src/main/display/advertise_click_nearly_minute_example.json"val sc = new SparkConf().setMaster("local[*]").setAppName("AddUserToBlackList")val ssc = new StreamingContext(sc,Seconds(10))ssc.checkpoint("/user/hadoop/kafka/checkpoint")val kafkaParams = Map[String, Object]("bootstrap.servers" -> "master:9092","key.deserializer" -> classOf[StringDeserializer],"value.deserializer" -> classOf[StringDeserializer],"group.id" -> "neu","auto.offset.reset" -> "latest","enable.auto.commit" -> (true: java.lang.Boolean),"offsets"-> "")val topic = Array("advertise-user")val kafkaDataDS = KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](topic, kafkaParams),)val adClickDS = kafkaDataDS.map(kafkaData => {val str = kafkaData.value()val strs = str.split(" ")TimeAdvertise(strs(0),strs(4))})// 9s(1-10) => 10s// 13s(11-20) => 20s// 24s(21-30) => 30s// 32s(31-40) => 40s// 48s(41-50) => 50s// 56s(51-60) => 60s(0)// (t / 10 (整除) + 1)*10 : (56/10+1)=60val reducedDS = adClickDS.map(data => {val timestamp = data.ts.toLongval time = new SimpleDateFormat("HH:mm:ss").format(new Date(timestamp)) // yyyy-MM-ddval hms = time.split(":")var s = (hms(2).toInt/10+1)*10var m = hms(1).toIntvar h = hms(0).toIntif(s==60){m = m + 1s = 0if(m==60){h = h + 1}}(h+":"+m+":"+s, 1)}).reduceByKeyAndWindow(_+_,_-_,Seconds(60),Seconds(10)) // 基于滑动窗口的有状态转换reducedDS.foreachRDD(rdd => {val list = ListBuffer[String]()val datas = rdd.sortByKey(ascending = true).collect()if(datas.length > 6){val last = datas.length-1println("--------------------------------")for (i <- (last-5) to last) {val xtime = datas(i)._1val yclick = datas(i)._2println("{\"xtime\":\""+xtime+"\",\"yclick\":\""+yclick+"\"}")list.append("{\"xtime\":\""+xtime+"\",\"yclick\":\""+yclick+"\"}")}}else{println("--------------------------------")datas.foreach{case (xtime,yclick)=>list.append("{\"xtime\":\""+xtime+"\",\"yclick\":\""+yclick+"\"}")}}val out = new PrintWriter(new FileWriter(new File(file), false))out.println("["+list.mkString(",")+"]")out.flush()out.close()})ssc.start()ssc.awaitTermination()}
}
advertise_click_nearly_minute.html
<html lang="en">
<head><meta charset="UTF-8"><title>最近1分钟广告总点击量,每10s计算一次title>
<script src="https://cdn.staticfile.org/echarts/4.3.0/echarts.min.js">script><script type="text/javascript" src="https://cdn.staticfile.org/jquery/1.10.2/jquery.min.js">script>
head>
<body><div id="display" style="height: 450px; width:800px">div>
<script>var myChart = echarts.init(document.getElementById("display"));setInterval(function () {$.getJSON("advertise_click_nearly_minute_example.json",function(data){var x = [];var y = []$.each(data,function (i,obj) {x.push(obj.xtime)y.push(obj.yclick)});var option = {xAxis:{type:"category",data:x},yAxis:{type:"value",},series:[{data:y,type:"line"}]};myChart.setOption(option)})},5000)
script>body>
html>
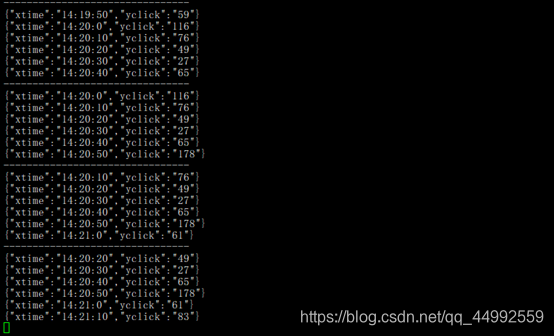
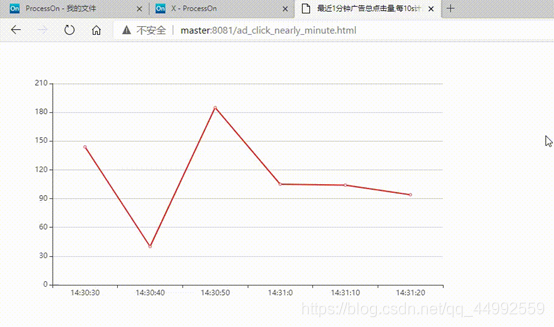
最近一分钟广告总点击量(每10秒统计一次)视频
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!