安居客[58租房]爬虫--解决ttf字体反爬
解决安居客ttf字体反爬虫
解决思路
在爬取安居客房源的过程中发现爬取下来的的数字是&#xxxxx的乱码,而不是正常的数字,因为从前没有接触过此类型的反爬,所以在这里写下我解决这个反爬的思路。

在这里可以发现所有的乱码的字体都有strongbox这个属性,于是去搜索strongbox。
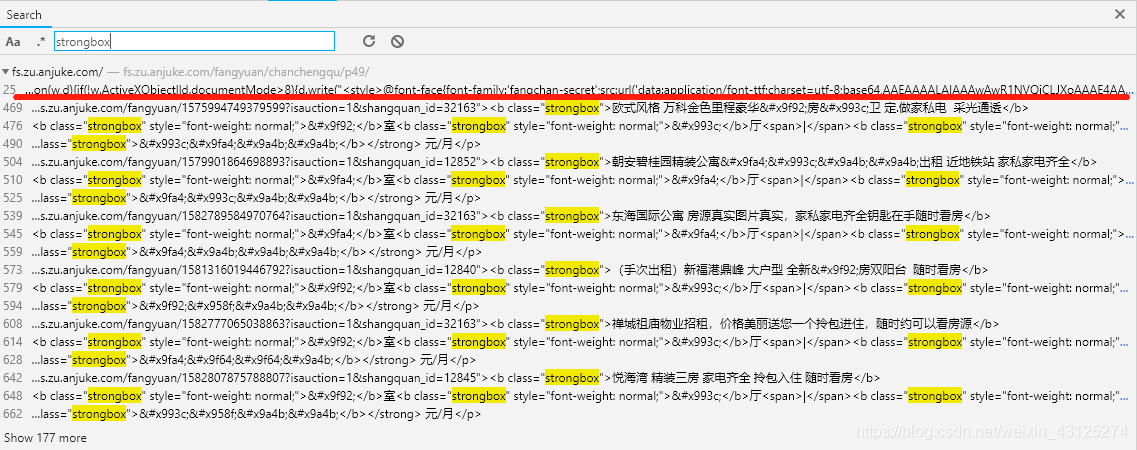
可以发现第一条非常的可疑,点开可以发现是这样的一条js代码。
<script>
!function(w, d) {
if (!w.ActiveXObject || d.documentMode > 8) {d.write("");if (navigator.userAgent.indexOf('Windows') != -1 && navigator.userAgent.indexOf('Chrome') != -1 && navigator.userAgent.indexOf('Maxthon') != -1) {d.write("")}
} else {d.write("");var i = d.createElement('img');i.onerror = function() {setTimeout(function() {var s = document.createElement('style'),n = document.getElementsByTagName('script')[0];s.type = 'text/css';s.styleSheet.cssText = '.strongbox{visibility:visible!important}';n.parentNode.insertBefore(s, n);},1300)};i.src = 'https://wos2.58cdn.com.cn/DeFazYxWvDkJ/sfont/dc8d179ef9508ab395777ce150e35aaa.eot';
}
} (window, document); </script>
可以发现代码中有提到一个base64编码的ttf字体,我们拿到python中进行base64的解码,然后转换成ttf文件,使用FontCreator查看。
from fontTools.ttLib import TTFont
import base64font_face = "AAEAAAALAIAAAwAwR1NVQiCLJXoAAAE4AAAAVE9TLzL4XQjtAAABjAAAAFZjbWFwq8N/ZAAAAhAAAAIuZ2x5ZuWIN0cAAARYAAADdGhlYWQaFby1AAAA4AAAADZoaGVhCtADIwAAALwAAAAkaG10eC7qAAAAAAHkAAAALGxvY2ED7gSyAAAEQAAAABhtYXhwARgANgAAARgAAAAgbmFtZTd6VP8AAAfMAAACanBvc3QEQwahAAAKOAAAAEUAAQAABmb+ZgAABLEAAAAABGgAAQAAAAAAAAAAAAAAAAAAAAsAAQAAAAEAAOC2HzRfDzz1AAsIAAAAAADbRzjSAAAAANtHONIAAP/mBGgGLgAAAAgAAgAAAAAAAAABAAAACwAqAAMAAAAAAAIAAAAKAAoAAAD/AAAAAAAAAAEAAAAKADAAPgACREZMVAAObGF0bgAaAAQAAAAAAAAAAQAAAAQAAAAAAAAAAQAAAAFsaWdhAAgAAAABAAAAAQAEAAQAAAABAAgAAQAGAAAAAQAAAAEERAGQAAUAAAUTBZkAAAEeBRMFmQAAA9cAZAIQAAACAAUDAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFBmRWQAQJR2n6UGZv5mALgGZgGaAAAAAQAAAAAAAAAAAAAEsQAABLEAAASxAAAEsQAABLEAAASxAAAEsQAABLEAAASxAAAEsQAAAAAABQAAAAMAAAAsAAAABAAAAaYAAQAAAAAAoAADAAEAAAAsAAMACgAAAaYABAB0AAAAFAAQAAMABJR2lY+ZPJpLnjqeo59kn5Kfpf//AACUdpWPmTyaS546nqOfZJ+Sn6T//wAAAAAAAAAAAAAAAAAAAAAAAAABABQAFAAUABQAFAAUABQAFAAUAAAABwAFAAMAAQAKAAYACQAEAAIACAAAAQYAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAADAAAAAAAiAAAAAAAAAAKAACUdgAAlHYAAAAHAACVjwAAlY8AAAAFAACZPAAAmTwAAAADAACaSwAAmksAAAABAACeOgAAnjoAAAAKAACeowAAnqMAAAAGAACfZAAAn2QAAAAJAACfkgAAn5IAAAAEAACfpAAAn6QAAAACAACfpQAAn6UAAAAIAAAAAAAAACgAPgBmAJoAvgDoASQBOAF+AboAAgAA/+YEWQYnAAoAEgAAExAAISAREAAjIgATECEgERAhIFsBEAECAez+6/rs/v3IATkBNP7S/sEC6AGaAaX85v54/mEBigGB/ZcCcwKJAAABAAAAAAQ1Bi4ACQAAKQE1IREFNSURIQQ1/IgBW/6cAicBWqkEmGe0oPp7AAEAAAAABCYGJwAXAAApATUBPgE1NCYjIgc1NjMyFhUUAgcBFSEEGPxSAcK6fpSMz7y389Hym9j+nwLGqgHButl0hI2wx43iv5D+69b+pwQAAQAA/+YEGQYnACEAABMWMzI2NRAhIzUzIBE0ISIHNTYzMhYVEAUVHgEVFAAjIiePn8igu/5bgXsBdf7jo5CYy8bw/sqow/7T+tyHAQN7nYQBJqIBFP9uuVjPpf7QVwQSyZbR/wBSAAACAAAAAARoBg0ACgASAAABIxEjESE1ATMRMyERNDcjBgcBBGjGvv0uAq3jxv58BAQOLf4zAZL+bgGSfwP8/CACiUVaJlH9TwABAAD/5gQhBg0AGAAANxYzMjYQJiMiBxEhFSERNjMyBBUUACEiJ7GcqaDEx71bmgL6/bxXLPUBEv7a/v3Zbu5mswEppA4DE63+SgX42uH+6kAAAAACAAD/5gRbBicAFgAiAAABJiMiAgMzNjMyEhUUACMiABEQACEyFwEUFjMyNjU0JiMiBgP6eYTJ9AIFbvHJ8P7r1+z+8wFhASClXv1Qo4eAoJeLhKQFRj7+ov7R1f762eP+3AFxAVMBmgHjLfwBmdq8lKCytAAAAAABAAAAAARNBg0ABgAACQEjASE1IQRN/aLLAkD8+gPvBcn6NwVgrQAAAwAA/+YESgYnABUAHwApAAABJDU0JDMyFhUQBRUEERQEIyIkNRAlATQmIyIGFRQXNgEEFRQWMzI2NTQBtv7rAQTKufD+3wFT/un6zf7+AUwBnIJvaJLz+P78/uGoh4OkAy+B9avXyqD+/osEev7aweXitAEohwF7aHh9YcJlZ/7qdNhwkI9r4QAAAAACAAD/5gRGBicAFwAjAAA3FjMyEhEGJwYjIgA1NAAzMgAREAAhIicTFBYzMjY1NCYjIga5gJTQ5QICZvHD/wABGN/nAQT+sP7Xo3FxoI16pqWHfaTSSgFIAS4CAsIBDNbkASX+lf6l/lP+MjUEHJy3p3en274AAAAAABAAxgABAAAAAAABAA8AAAABAAAAAAACAAcADwABAAAAAAADAA8AFgABAAAAAAAEAA8AJQABAAAAAAAFAAsANAABAAAAAAAGAA8APwABAAAAAAAKACsATgABAAAAAAALABMAeQADAAEECQABAB4AjAADAAEECQACAA4AqgADAAEECQADAB4AuAADAAEECQAEAB4A1gADAAEECQAFABYA9AADAAEECQAGAB4BCgADAAEECQAKAFYBKAADAAEECQALACYBfmZhbmdjaGFuLXNlY3JldFJlZ3VsYXJmYW5nY2hhbi1zZWNyZXRmYW5nY2hhbi1zZWNyZXRWZXJzaW9uIDEuMGZhbmdjaGFuLXNlY3JldEdlbmVyYXRlZCBieSBzdmcydHRmIGZyb20gRm9udGVsbG8gcHJvamVjdC5odHRwOi8vZm9udGVsbG8uY29tAGYAYQBuAGcAYwBoAGEAbgAtAHMAZQBjAHIAZQB0AFIAZQBnAHUAbABhAHIAZgBhAG4AZwBjAGgAYQBuAC0AcwBlAGMAcgBlAHQAZgBhAG4AZwBjAGgAYQBuAC0AcwBlAGMAcgBlAHQAVgBlAHIAcwBpAG8AbgAgADEALgAwAGYAYQBuAGcAYwBoAGEAbgAtAHMAZQBjAHIAZQB0AEcAZQBuAGUAcgBhAHQAZQBkACAAYgB5ACAAcwB2AGcAMgB0AHQAZgAgAGYAcgBvAG0AIABGAG8AbgB0AGUAbABsAG8AIABwAHIAbwBqAGUAYwB0AC4AaAB0AHQAcAA6AC8ALwBmAG8AbgB0AGUAbABsAG8ALgBjAG8AbQAAAAIAAAAAAAD/EwB3AAAAAAAAAAAAAAAAAAAAAAAAAAAACwECAQMBBAEFAQYBBwEIAQkBCgELAQwAAAAAAAAAAAAAAAAAAAAA"
b = base64.b64decode(font_face)
with open('anjuke.ttf','wb') as f:f.write(b)font = TTFont('./anjuke.ttf')

可以看出数字的编码与在源代码中看到的乱码有对应的关系。接下来就是如何将这个对应关系转为python中的字典,在网上找到的解决方案是将ttf文件转换为xml文件,然后解析xml文件。
# 在上面代码的最后一行加上,即可得到我们需要的xml文件
font.saveXML('./anjuke.xml')
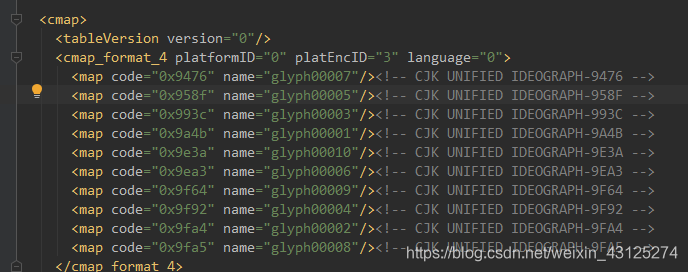
在xml这里可以得到字符的对应关系,对应的字符就是name属性去掉glyph再减1。
# 最终的ttf解析代码
def decode_base64(font_face):b = base64.b64decode(font_face)# with open('anjuke.ttf','wb') as f:# f.write(b)# font = TTFont('./anjuke.ttf')# font.saveXML('./anjuke.xml')font = TTFont(io.BytesIO(b))bestcmap = font['cmap'].getBestCmap()unicode_num_dict = {}for key in bestcmap.keys():num = int(bestcmap[key].replace("glyph", "")) - 1key = str(hex(key))key = key.replace("0x", "&#x")key += ";"unicode_num_dict[key] = str(num)return unicode_num_dict
接下来 就是将获取的html content中所有的乱码字符串进行替换,然后就可以正常的获取信息啦!!!
最终代码如下
import requests
from lxml import etree
import re
import time
import random
import csv
from fontTools.ttLib import TTFont
import base64
import io# 关闭InsecureRequestWarning提示
import urllib3
urllib3.disable_warnings()def decode_base64(font_face):b = base64.b64decode(font_face)font = TTFont(io.BytesIO(b))bestcmap = font['cmap'].getBestCmap()unicode_num_dict = {}for key in bestcmap.keys():num = int(bestcmap[key].replace("glyph", "")) - 1key = str(hex(key))key = key.replace("0x", "&#x")key += ";"unicode_num_dict[key] = str(num)return unicode_num_dictheaders = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3775.400 QQBrowser/10.6.4208.400",'Connection': 'close'}
page = 1
while page <= 50:url = "https://fs.zu.anjuke.com/fangyuan/chanchengqu/p{}/".format(page)try:res = requests.get(url, headers=headers, verify=False)content = res.content.decode("utf-8")font_face = re.findall("base64,(.*)'\) format", content)[0]except Exception as e:print("获取网页时产生错误!正在尝试重新请求... 错误信息:[{}] ".format(e))time.sleep(random.uniform(1, 3))continueunicode_num_dict = decode_base64(font_face)for key, value in unicode_num_dict.items():content = content.replace(key, value)dom_tree = etree.HTML(content)house_list = dom_tree.xpath("//div[@class='list-content']/div[@class='zu-itemmod']")house_info_list = []for house in house_list:house_info = {}house_info["house_address"] = house.xpath("./div/address/a/text()")[0]house_info["house_detail_address"] = house.xpath("./div/address/text()")[1].replace("\xa0", "").replace("\n", "").replace(" ","")house_info["house_title"] = house.xpath("./div[@class='zu-info']/h3//b/text()")[0]house_info["house_url"] = house.xpath("./a/@href")[0]house_info["house_price"] = house.xpath("./div[@class='zu-side']//b/text()")[0] + "元/月"house_info["house_style"] = house.xpath(".//p[@class='details-item tag']/b[1]/text()")[0] + "室" + house.xpath(".//p[@class='details-item tag']/b[2]/text()")[0] + "厅"house_info["house_square"] = house.xpath(".//p[@class='details-item tag']/b[3]/text()")[0] + "平米"house_info_list.append(house_info)with open('data01.csv', 'a', encoding='utf-8', newline='') as f:field_name = ['house_title', 'house_address', 'house_detail_address', 'house_url', 'house_price', 'house_style', 'house_square']writer = csv.DictWriter(f, fieldnames=field_name)writer.writeheader()for house_info in house_info_list:writer.writerow(house_info)print("已完成第{}页的房源信息获取!".format(page))page += 1# 访问过快可能会产生人机验证导致爬取失败time.sleep(random.uniform(5, 7))
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!