分类指标解释
最基本的四个概念
- 真正例(True Positive,TP):真实类别为正例,预测类别为正例。
- 假正例(False Positive,FP):真实类别为负例,预测类别为正例。
- 假负例(False Negative,FN):真实类别为正例,预测类别为负例。
- 真负例(True Negative,TN):真实类别为负例,预测类别为负例。
延申的一些概念:

比较重要的是Accuracy,F1score, Recall, Precision。

F1分数(F1-Score),又称为平衡F分数(BalancedScore),它被定义为精确率和召回率的调和平均数。除了F1分数之外,F0.5分数和F2分数,在统计学中也得到了大量应用,其中,F2分数中,召回率的权重高于精确率,而F0.5分数中,精确率的权重高于召回率。
multi-class classification的情况
如果是multi-class classification,我有两个选项:
- 各个类别分别统计TP/FP/FN/TN,分别计算出每个类别的Accuracy,F1score, Recall, Precision,然后对各个类被进行算术平均,最终得到一组 Accuracy,F1score, Recall, Precision,这就叫做宏平均 (Macro-averaging)。
- 统计TP/FP/FN/TN的时候不区分类别,最终也就只有一组TP/FP/FN/TN,也就只有一组Accuracy,F1score, Recall, Precision,这就叫做微平均 (Micro-averaging)
Note that if all labels are included, “micro”-averaging in a multiclass setting will produce precision, recall and that are all identical to accuracy.


这里考虑的三个类别(1,2,3)只有一个(1)是存在的,那自然微平均的结果就是跟类别1的结果的一样的。

定义是这样的:

Binary-class classification的情况
TP/FP/FN/TN,Accuracy,F1score, Recall, Precision指标如果说应用在二分类问题的话,都是很清晰的。
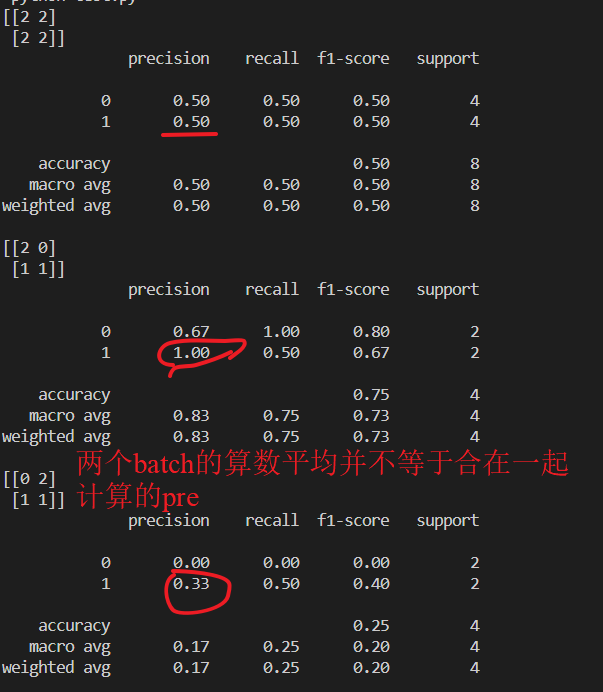
但是,如果大批量的样本,batch wise计算的时候?这个时候,严格的正确的做法是一起统计所有batch的样本,也即是所有的样本的TP/FP/FN/TN,最后再去计算Accuracy,F1score, Recall, Precision。
如果你是批处理的话,对每个批次分别进行计算Accuracy,F1score, Recall, Precision的话,就要对各个批次的结果进行平均,这会导致:
from sklearn import metricsy_pred = [0, 1, 0, 0]
y_true = [0, 1, 0, 1]print(metrics.confusion_matrix(y_true, y_pred))
print(metrics.classification_report(y_true, y_pred))y_pred = [0, 1]
y_true = [0, 1]
print(metrics.confusion_matrix(y_true, y_pred))
print(metrics.classification_report(y_true, y_pred))y_pred = [0, 0]#这种情况对于类别1没法计算precision
y_true = [0, 1]print(metrics.confusion_matrix(y_true, y_pred))
print(metrics.classification_report(y_true, y_pred))#同样的数据拆分成两份,分别计算 precision recall f1-score,
#然后算术平均是有问题的,尤其是数据不平衡的时候,如果某个batch里面
#不存在某个类的话,就会出现除零的情况,也是会影响结果的
#所以保险起见,还是全部统计完成TP/FP/FN/TN,最后再计算precision recall f1-score
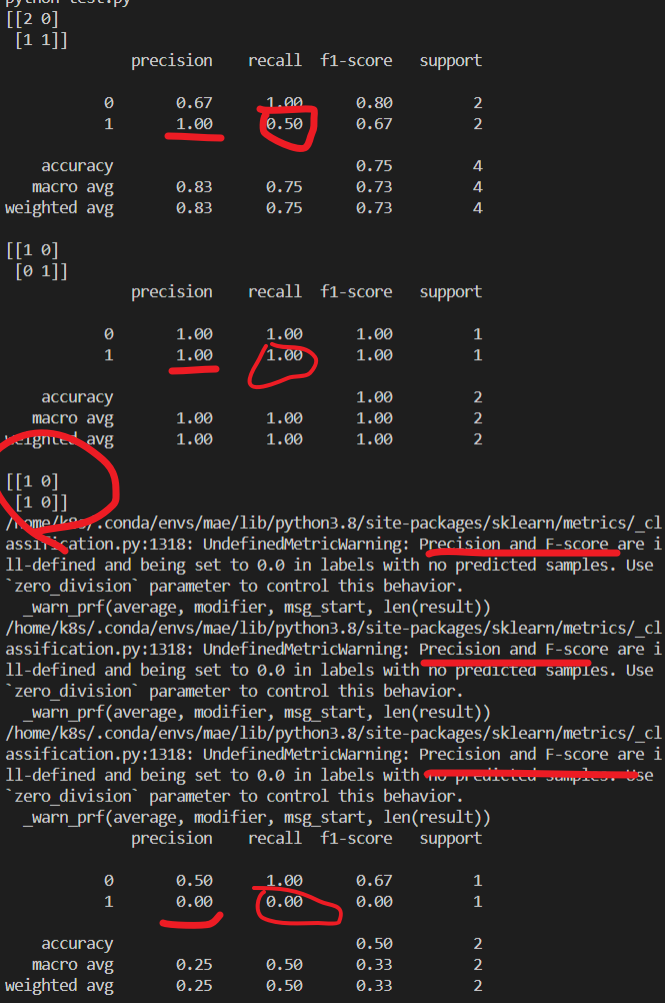
即便不是“除零”的情况,分批次计算+算术平均的结果跟合并计算的结果也不一致!
Multi-label (multi-class) classification
MLMC就是说单个图片有多个标签,如果一般的multi-class classification是独热编码的话,MLMC就是多热编码。如果多热编码必须跟GT一模一样才算是正确的话,这样就太严格了。这样就演变出来了很多的评价指标。
第一,可以把每一个类别都当成一个二分类的问题进行评价,很自然地就可以得到每个类别的Accuracy,F1score, Recall, Precision,然后求算术平均自然就得到了宏平均。
参考这里的英文:
Label based measures evaluate each label separately and then averages over all labels. Therefore,any known measure, used for evaluation of a binary classifier (e.g. accuracy, precision, recall, F 1 , ROC etc.), can be used here. Any of these scores can be computed on individual class labels first and then averaged over all classes.

那微平均是什么呢?,一样的,微平均就是不区分类别:


注意,这里没有”除以总个数“这样的操作,我的理解就是,把n*k个零和一摊开了一起统计出一个TP/FP/FN/TN,只一次计算Accuracy,F1score, Recall, Precision
It is important to note here that by definition, macro averaged F 1 would be more affected by the performance of the classes which has fewer examples and in contrast, micro averaged F 1 would be more affected by the performance of the classes which has more examples。
上述方法也叫做基于label,label based的评价指标;还有一种基于样本,Example-based的评价指标。 我理解的就是,对每一个Example,把1*k这个向量当成是一个二分类问题,得到TP/FP/FN/TN,先计算Accuracy,F1score, Recall, Precision,然后再对所有的样本平均,得到最后的Accuracy,F1score, Recall, Precision。


本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!