基于Tensorflow的Faster R-CNN深度学习算法在CPU下实现目标检测
2014年是目标检测算法的里程碑,因为那一年R-CNN横空出世,将深度学习-卷积神经网络用在了目标检测领域,标志着目标检测进入了一个新的高度。目前tensorflow深度学习框架比较火且容易上手,所以想基于tensorflow来看看RCNN到底是怎么实现图片目标检测的。本人洒哥比较穷,电脑还是2013年买的,所以GPU很菜,在深度学习领域没法用GPU来train和Inference,github上的RCNN代码很多都默认是GPU运行,我这里记录一下如何在CPU下运行RCNN代码的demo。
因为RCNN出来之后,Fast RCNN,Faster RCNN相继问世,肯定是越来越牛皮,老的方法将会被摒弃,所以我就直接拿Faster R-CNN来做演示了,但是想提醒一下:R-CNN是核心,后面的都是基于此思想来改进的。
------本文章只是实现了基于深度学习的图片检测的Inference过程,实现了图片中20类目标检测功能,并没有Train过程,只需要下载源码和已经训练好的模型即可,不需要数据集。后续洒哥会写如何基于Faster R-CNN训练自己的数据集。
1.本机环境
ubuntu16.04,CPU,tensorflow==1.15.0(不是GPU版本的TF,如下),python3,opencv-python3,cython==0.25.2,easydict
如果后面编译出现了找不到相应模块,大家pip安装一下就可以了,如:
sudo pip3 install cython==0.25.2
sudo pip3 install easydict
2.下载Faster R-CNN代码
git clone https://github.com/endernewton/tf-faster-rcnn.git
3.修改CPU运行配置
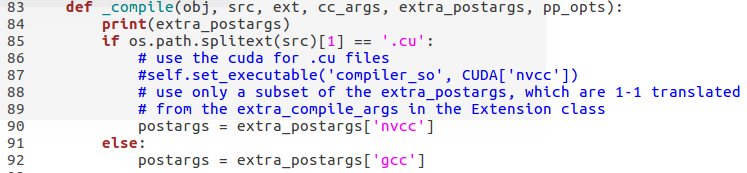
lib/setup.py文件中设置CPU和GPU的参数,如图所示:

因为代码默认是在GPU下运行,如果不设置成CPU模式,后面编译和运行代码时会报错。(要在GPU下运行就很简单了,只需要根据自己GPU的型号来设置-arch一个参数就可了)
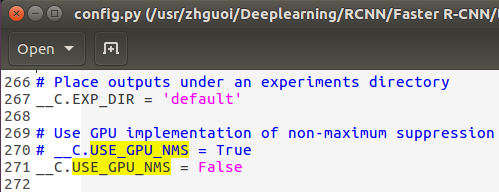
1. 修改config.py代码:将USE_GPU_NMS 由原来的True改为False就可以:
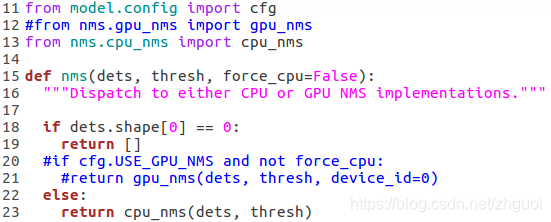
2. 修改 lib/model/nms_wrapper.py文件
按照图中所示,将代码注释,直接禁用掉GPU模式
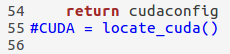
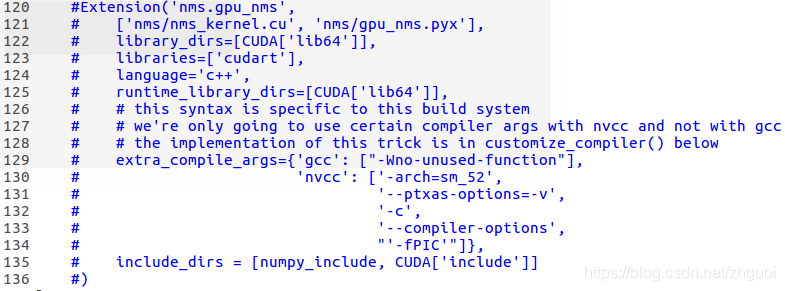
2. 修改 lib/setup.py文件
一种需要修改三处地方:
4. 安装和链接cython 模块
首先安装cython模块:sudo pip3 install cython==0.25.2
然后在lib目录下打开终端,输入
make clean
make
至此,代码要在CPU下运行的设置已完成。
5.安装 Python COCO API
代码中要用到COCO数据库,也可以手动下载,然后放在/data下即可:
cd data
git clone https://github.com/pdollar/coco.git
cd coco/PythonAPI
make
6.下载预训练好的Model
1. 下载已经训练好的模型
要用到的模型 voc_0712_80k-110k.tgz ,该模型可实现20类目标检测,如dog,car,person等。下载见百度网盘: https://pan.baidu.com/share/init?surl=ClcNOWiqOm6nyAdfD3RSsQ ,提取码: 6dz8。下载之后放到 data文件夹中,使用以下命令解压:
tar xvf voc_0712_80k-110k.tgz
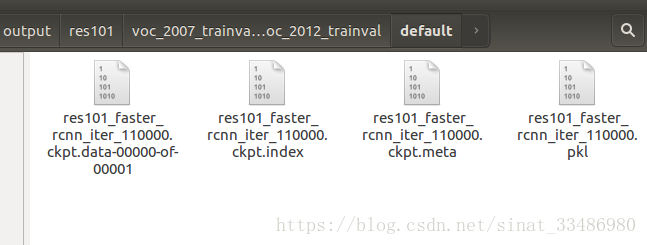
解压得到voc_2007_trainval+voc_2012_trainval文件夹,其中包含四个模型文件:
res101_faster_rcnn_iter_110000.ckpt.data-00000-of-00001
res101_faster_rcnn_iter_110000.ckpt.index
res101_faster_rcnn_iter_110000.ckpt.meta
res101_faster_rcnn_iter_110000.pkl
2. 建立预训练模型的软连接
在tf-faster-rcnn主目录下:NET=res101
TRAIN_IMDB=voc_2007_trainval+voc_2012_trainval
mkdir -p output/${NET}/${TRAIN_IMDB}
cd output/${NET}/${TRAIN_IMDB}
ln -s ../../../data/voc_2007_trainval+voc_2012_trainval ./default
建立了模型软链接之后,双击default之后,会出现以下四个文件,说明就成功哦,后面运行demo.py时就会找到model来做推理,不然会提示你找不到:xx.cpkt的
7. CPU下运行demo
python3 ../tools/demo.py
运行结果为:
这个demo里面自带5张照片:

运行后的预测结果为12张图像:

其实想运行demo还是很简单的:大家先去尝试运行下代码,先比较直观的看到图片检测结果,当十几张图片突然跳出来的时候,心里还是慢开心的,后面再怀着好奇心看看代码是如何实现把图片中的目标给框出来的~,这才是关键
疑问
- 为啥一张图片中有多个目标时,一张图片只检测出来一种,然后同样的图片再检测出来另外一种目标?
- 检测出来的结果在哪,如何取出来?最终还是要把(x,y,w,h)发送给下面的决策算法的。
- 5张图片检测出来需要30多s,看来一张image的inference大概6s,还是很慢的,如何提高预测速度?
后续计划:
- 下一步加入公开的20类目标训练集(如PASCAL VOC2007),训练模型,然后用简单训练出的模型进行检测;
- 制作自己的数据集,如panda,格式为VOC2007,修改源码,执行Train,Inference,Test等过程,实现自定义目标检测;
- 实现视频流目标检测。
最后:问题懊恼时常六问,之一乃问博客,当问题迎刃而解之时,一念头萦绕脑海,何不记录以助后来的人呢,故写下了洒哥的第一篇CSDN技术博客,特此纪念。有一些内容也是参考和借鉴一些前人的相关技术博客,在此表示感谢。君不见黄河之水天上来,奔流到海不复回,同时也加了一丢丢自己的理解和思考,前见古人后见来者,未来还需加油!
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!