java swap空间_故障重现(内存篇2),JAVA内存不足导致频繁回收和swap引起的性能问题...
背景起因:
记起以前的另一次也是关于内存的调优分享下
有个系统平时运行非常稳定运行(没经历过大并发考验),然而在一次活动后,人数并发一上来后,系统开始卡。
我按经验开始调优,在每个关键步骤的加入如下代码耗时统计进行压测:
long startTime = System.currentTimeMillis();
callRpc(); //这里比如调用RPC伪代码,当然还在插入数据库,中间件地方都加入统计
long costTime = (System.currentTimeMillis() - startTime);
//统计600毫秒以上耗时
if (costTime > 600) {
logger.warning("callRpc cost time:" + costTime);
}
然后去grep日志, 最后神奇的发现各个地方都有超过600毫秒的地方...
然后各种定位的误导...
当然最终是解决了,原因是由于程序里使用了大对象导致
细分析,即使这种情况深研究也是分很多情况的
问题重现:
原因分析:
由于系统中使用了大对象,当并发来临,内存讲被吃紧,将有可能引起如下三种情况
第一种情况, 系统内存够用(JVM内存未使用到SWAP内存),但JVM内存不够,最终导致JVM的频繁垃圾回收(FGC),严重影响性能 (stop the word)
第二种情况,系统内存不够,把JVM堆部分用到了SWAP,那么此时的垃圾回收需要把SWAP的内存换回到系统物理内存再进行JVM的垃圾回收。最大影响,导致每次GC的时间变得很久
第三种情况, 物理内存不够用, 大量JVM的堆内存被交换到SWAP后,垃圾回收时,把SWAP内存换回物理内存,但SWAP的内存又不会立即回, 此时可以观察到垃圾回收同时swap使用的内存会变大(其它部分内存要交换到SWAP里)
准备:
ubuntu 1G 4核
先关闭SWAP虚拟空间 sudo swapoff -a
java version "1.7.0_101"
apache-tomcat-8.5.9
设置好Tomcat的JVM内存:
JAVA_OPTS="-Xmx500m -Xms500m -Xmn200m -Xss228k -XX:+UseConcMarkSweepGC -XX:+UseParNewGC"
apache-jmeter-2.13 用于模拟HTTP请求压测,都是100条线程并发进行压测
模拟代码如下
/**
* 模拟当系统中使用大对象时,对JVM造成的影响
*
* @author 包子(何锦彬). 2017.01.07
* @QQ 277803242
*/
@WebServlet("/Test")
public class Test extends HttpServlet {
private static final long serialVersionUID = 1L;
private Logger logger = Logger.getLogger(Test.class.getName());
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
// use java heap 10m
byte[] bts = new byte[1024 * 1024 * 10];// 代码段1
long startTime = System.currentTimeMillis();
// deal
try {
// 模拟业务花费时间
Thread.sleep(500);
} catch (InterruptedException e) {
}
// 理论上这里输出500附近
long costTime = (System.currentTimeMillis() - startTime);
if (costTime > 600) {
logger.warning("cost time:" + costTime);
}
Writer out = response.getWriter();
out.append("ok");
}
先模拟正常的情况:
先注释掉"代码段1", 1W个请求下来,基本耗时都在500,一切正常,返回都是在500毫秒附近

垃圾回收情况,只发生了1次YGC,所以系统正常稳定...
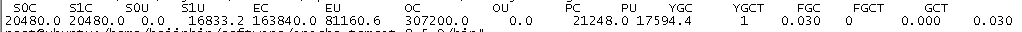
模拟第一种情况:
放开“代码段1”,让每次请求都去堆内存申请10m的堆空间,同样是1W个请求,返回的平均值已经接近了2S

垃圾回收情况来看, 已经发生了1966次的FGC了, 在上面耗时158秒
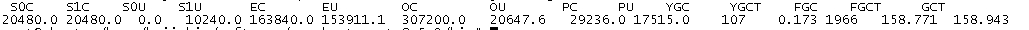
模拟第二种情况:
把系统的SWAP打开,打开2G的SWAP,swapon -a

调大JVM参数,到1G,让JVM用到部分SWAP的空间
此时再让每次请求都去堆内存申请10m的堆空间,同样是1W个请求,性能已经低于第二种情况

垃圾回收来看,回收次数是1766次,比第二种情况发生的次数还要少,但FGC耗费的时间已经是212秒,
(虽然多了200m内存也没差距这么大,更精确看年轻代一样的内存,耗时也远超过)远超过第二种情况了
此时垃圾回收详情:
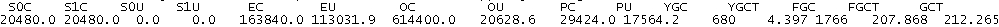
模拟第三种情况:
这种情况和我上一篇提到的类似,如果系统内存不够用时,系统将KIIL掉内存
总结:
频繁垃圾回收(FGC),会严重影响性能。如果此时用耗时统计去寻找瓶颈,会出现失误;
如JVM堆用到了SWAP分区,当发生GC:
1,会导致大量SWAP被使用,2,导致每次GC的时间变得很久;
SWAP分区开启可以有效防止进程因为内存问题而被系统杀掉;
持续更新留言问题,解答疑问
欢迎关注我的公众号,专注重现各种线上的BUG
或搜 “包子的实验室”
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!