自学python笔记+flask框架(阳帅网络_阳帅车队)
学习人微信:cybst88888
取模运算%-求余
地板除//-得到的结果会忽略纯小数的部分,得到整数的部分
小数点位数round(结果, 保留位数)
format 来处理字符串三种方式,输出不固定的内容。
for 变量 1,变量 2 in d.items():输出key, value.
变量.get(判断key是否存在)
update()或者.add()都是往集合添加数据
discard()集合删除某数据不会报错
isdisjoint()判断集合是否重合
isinstance(变量名,类型)判断是否是这个数据类型
函数可变参数。*args 传的是一个元组,多少位都可以
函数可变参数**kwargs默认key+value
help().主要查看类下面的方法
对象:object_实例化方法:init
类下面的变量__变量,加下划线为私有属性
类方法:classmethod(加cls)
super().方法名(继承变量1,继承变量2)__切记双下划线
加dir(类名) 查看下面所有的方法
父亲.同父亲变量(self) #对父类方法的扩展
https://www.jb51.net/article/160162.htm(类比较详细操作)
slots = (‘name’, ‘gender’, ‘score’)限定类的属性不让添加
def call():把一个类实例也变成一个可调用对象 变量()
eval(‘1+1’)函数可以把字符串转换为等值的结果(可做计算器)
with open(‘test.txt’, ‘操作方式’) as f: 对文件增删改查
content = f.readlines()
for line in content:
print(line)
函数式编程:map()
filter()这个函数的作用是对每个元素进行判断,返回 True或 False,filter()根据判断结果自动过滤掉不符合条件的元素
sorted()函数,默认是由小到大排序列表的元素。
lambda 匿名函数
flaks:----------------------基础------------组合---------
from flask import Flask,request
app=Flask(‘iii’)
@app.route(’/’)#装饰器+括号和不加的区别
def index():
print(request.path)#打印请求路径
return ‘hello world’
if name == ‘main’:
app.run()#请求来了会请求app(request)__会触发—__call__方法
render_template 引入返回 前端模板语言 渲染模板
redirect 重定向

处理字典套字典传到前端+翻页通配符

使用别名+后端使用翻页通配符

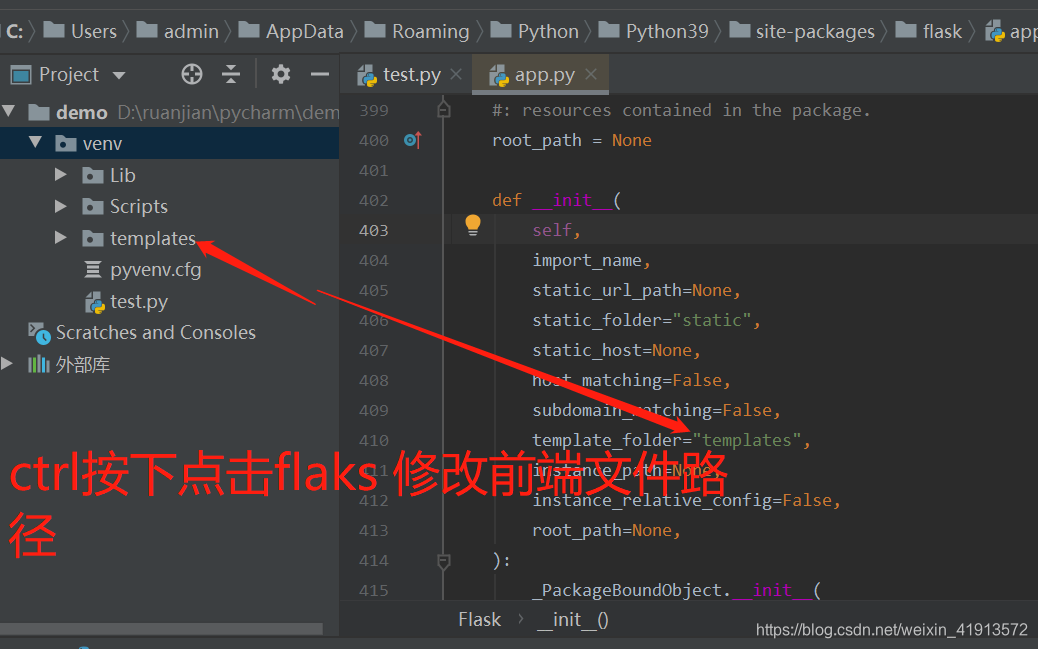
flask 调试模式的三种写法
1、app.debug=True #打开调试模式 方便快捷
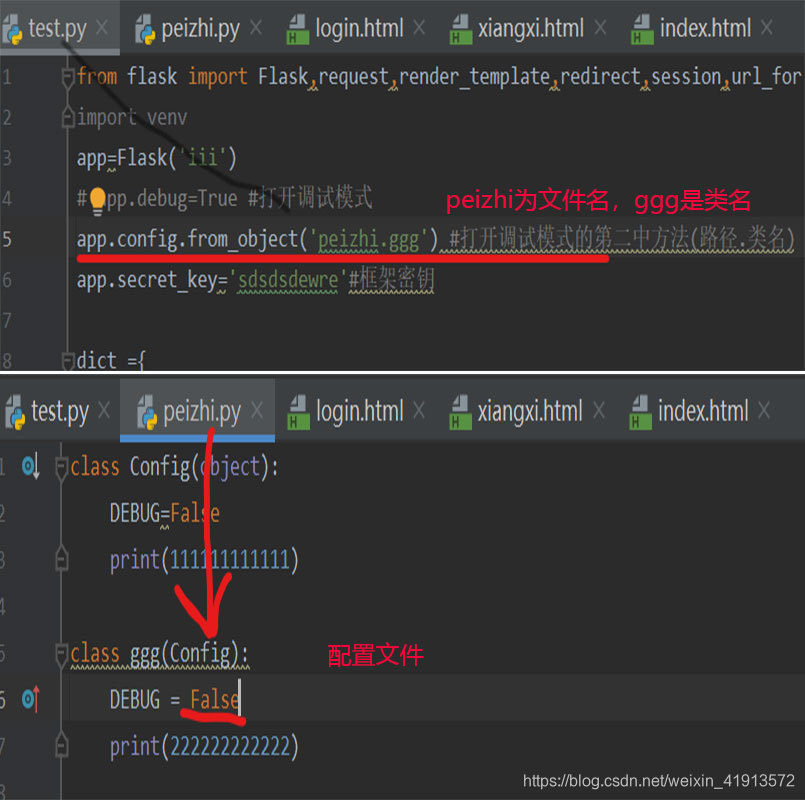
2、建议写到配置文件里 下面图片
session配置说名 和参考表

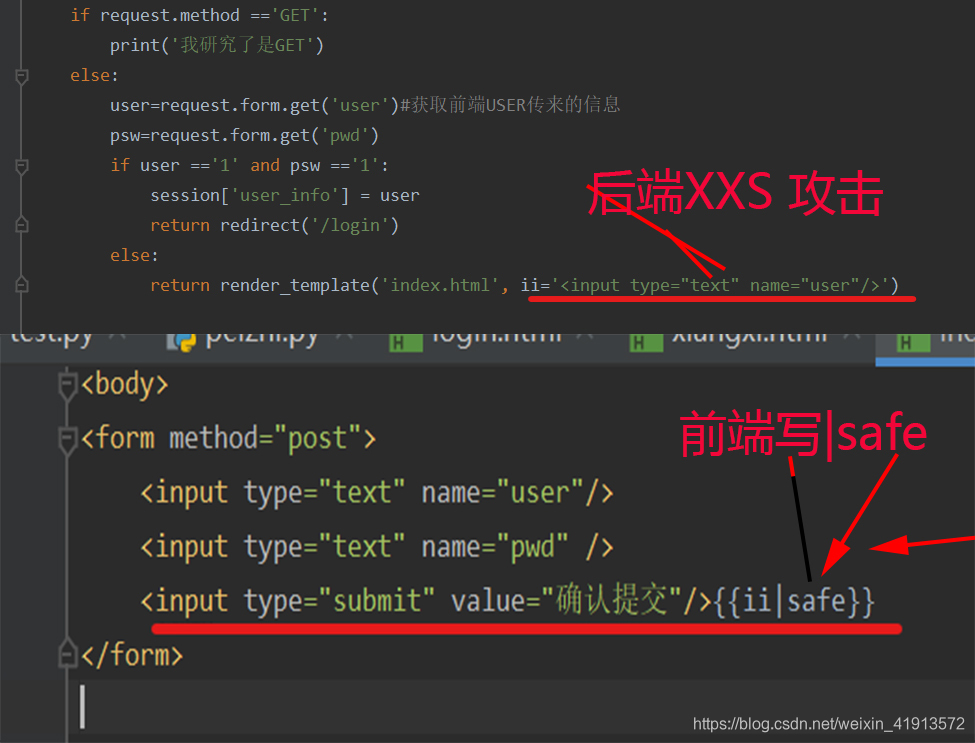
flaks框架前端防止XXS攻击
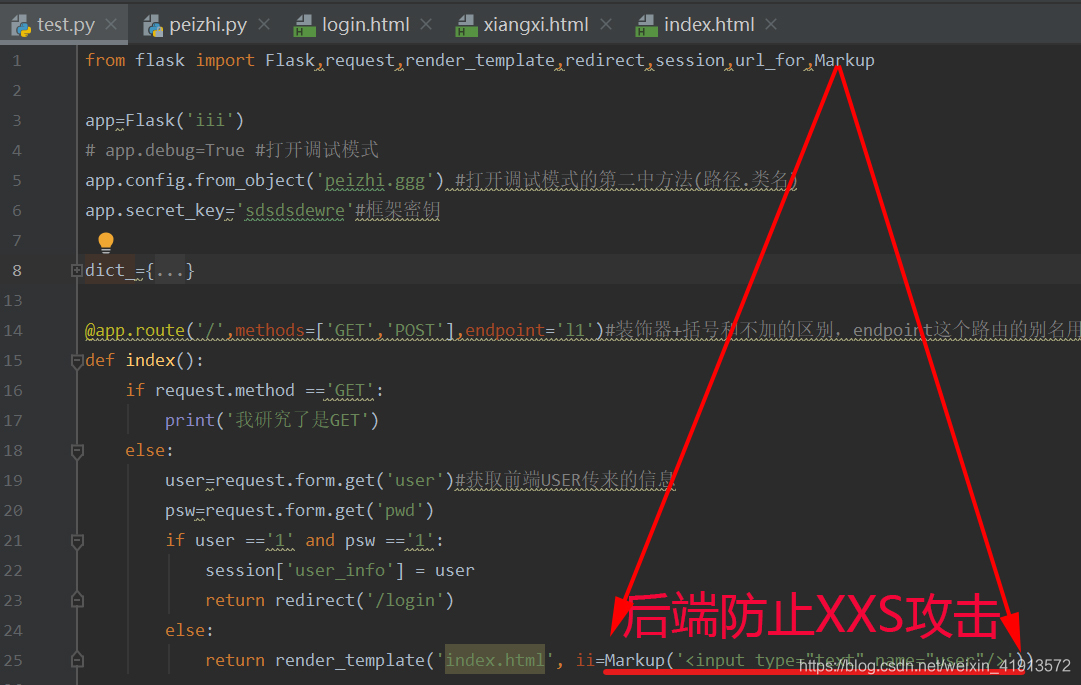
flaks框架后端防止XXS攻击
request请求对象获取数据的方法
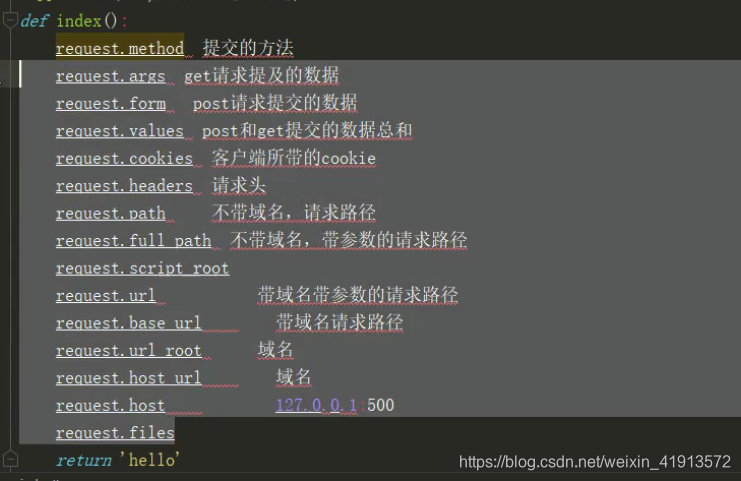
pip3 install 模块名字(python安装模块)
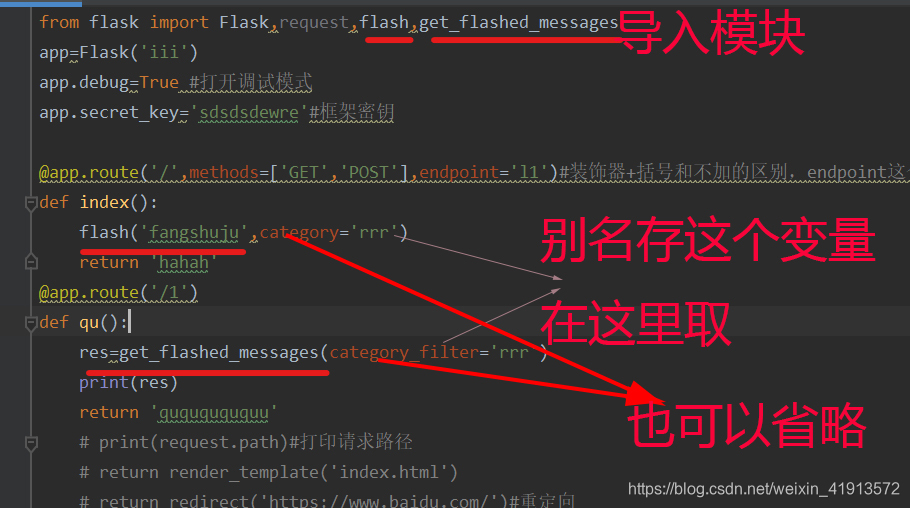
闪现函数组合:
导入flash存数据
导入get_flashed_messages取数据
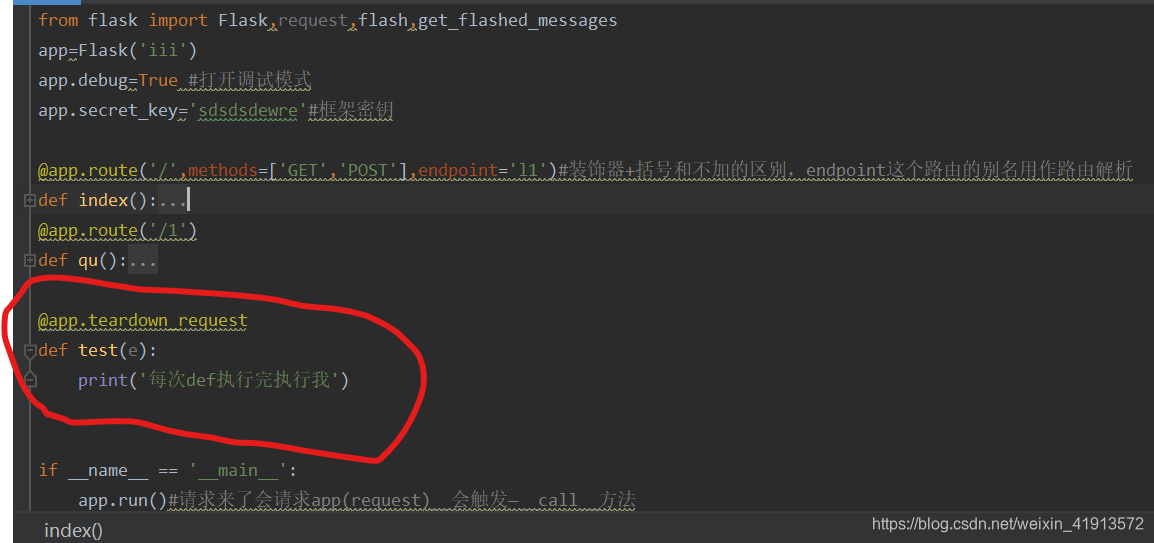
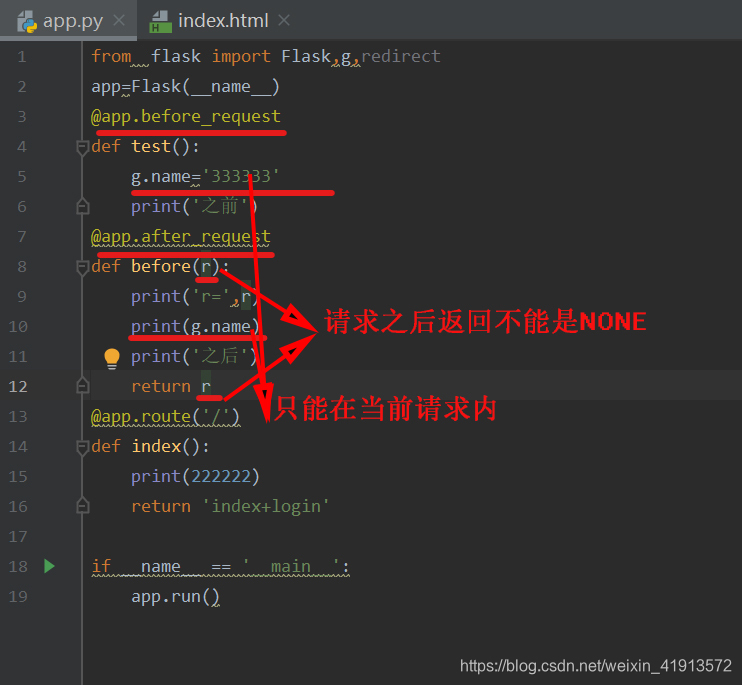
请求扩展:在request请求前,请求后+事件
from flask import Flask,request,render_template
app = Flask(__name__)@app.before_request#请求之前
def befor1():print(request)print("我是请求之前1")@app.after_request#请求之后
def befor2():print("我是请求之后1")@app.route('/index')
def index():print("我是真的视图")return render_template("index.html")if __name__ == '__main__':app.run()
每次def执行完,执行的函数
@app.teardown_request
def test(e):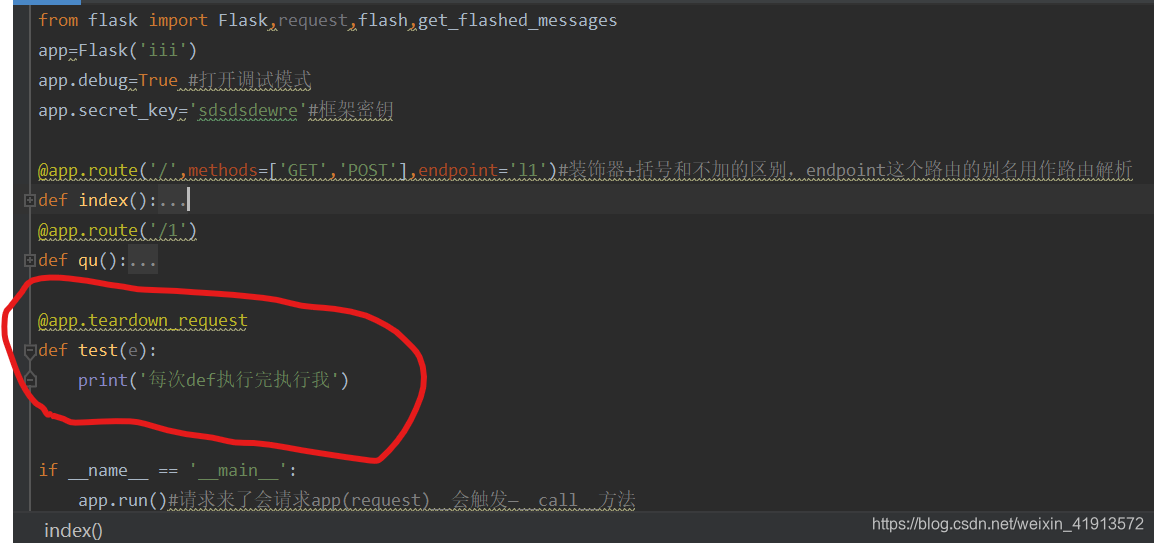print('每次def执行完执行我')
蓝图(大型项目路由分发)
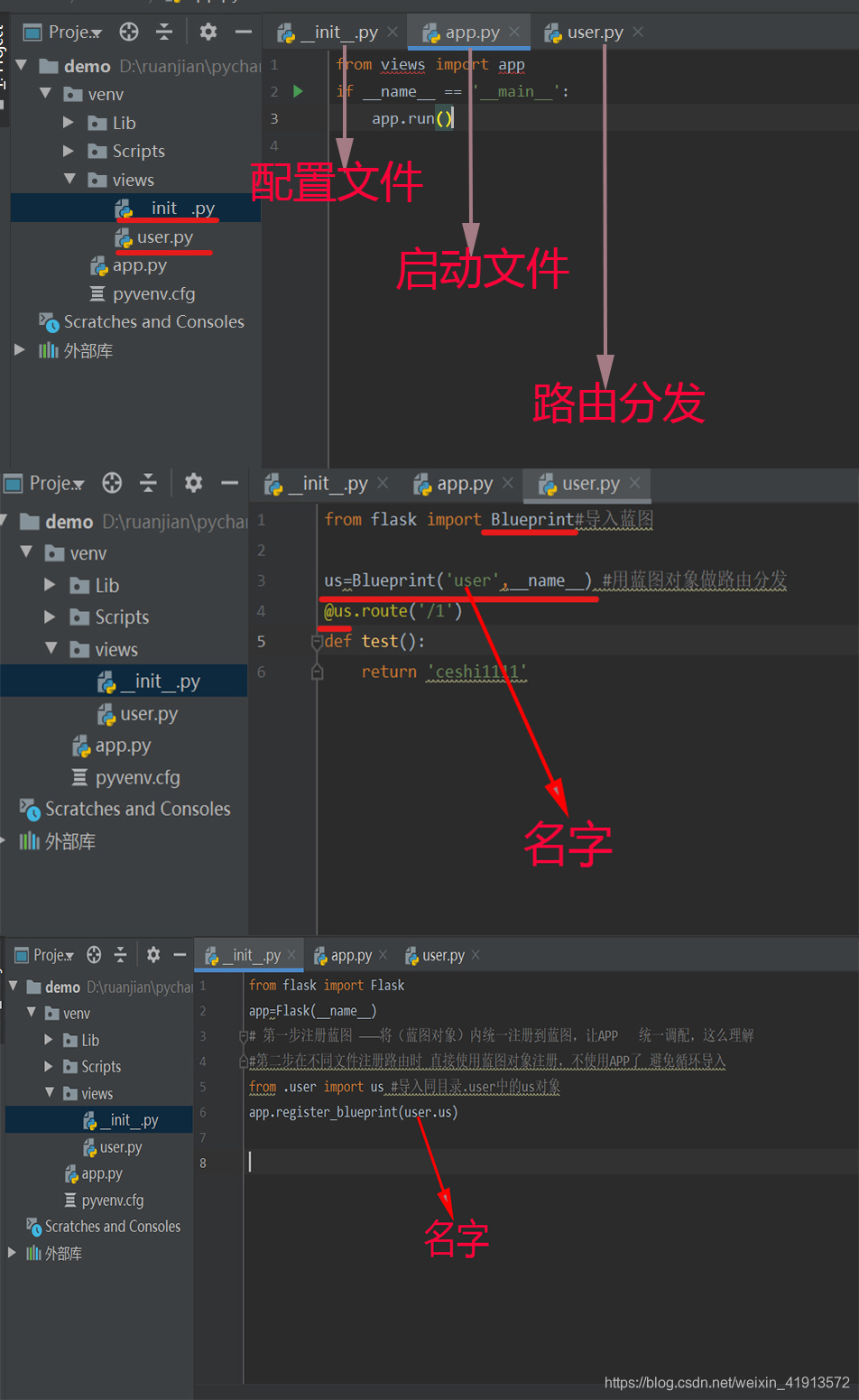
flask中实例化配置
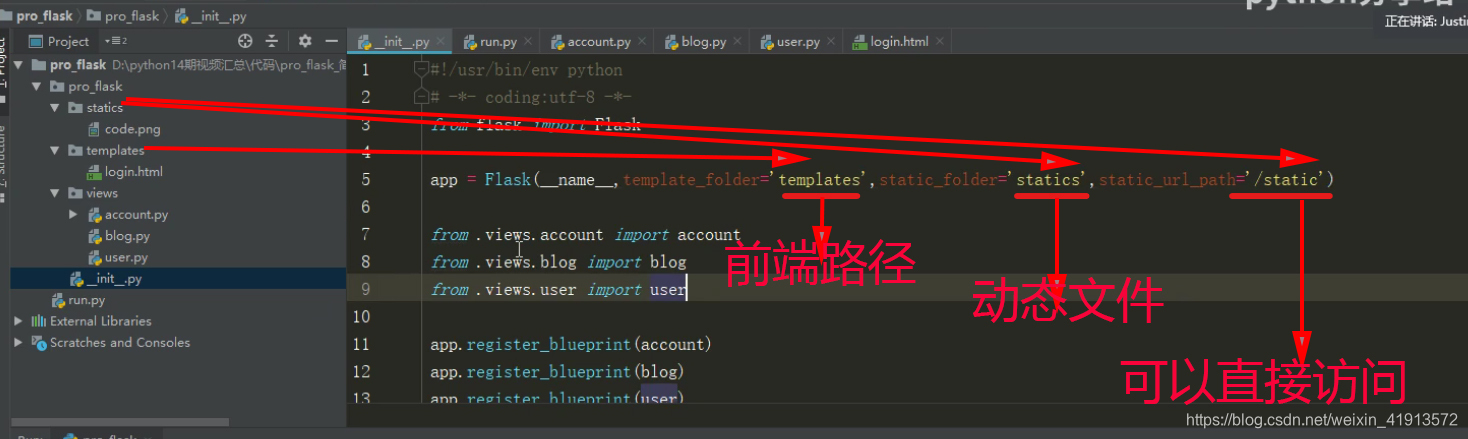
flask中小型项目划分架构图

flask大型项目架构图
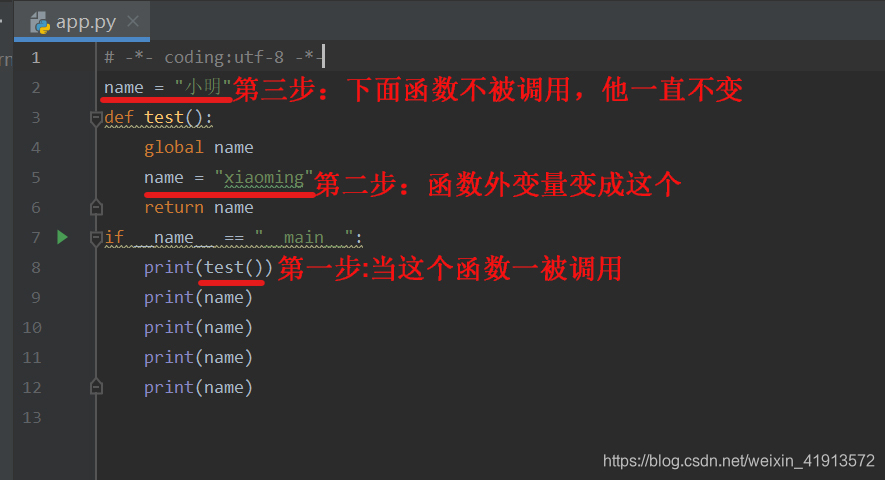
python之global用法
如果需要在函数内部改变函数外部的变量,就可以通过在函数内部声明变量为global变量。这样当程序运行至global变量便会替换外部的同名变量。
g.是一个全局变量,主要在请求中放值,取值
g.的生命周期 只有这个请求内
flask-session的两种用法
作用:将默认保存的签名cookie中的值 保存到 redis/memcached/file/Mongodb/SQLAlchemy
安装:pip3 install flask-session
使用1 (复杂的方式)无redis无法测试
from flask import Flask,session
from flask_session import RedisSessionInterface
import redis
app = Flask(__name__)
app.secret_key="ajksda"
conn=redis.Redis(host='127.0.0.1',port=6379)
#use_signer设置是否需要secret_key签名,permanent设置关闭浏览器cookie是否失效
app.session_interface=RedisSessionInterface(conn,key_prefix='jason',use_signer=True, permanent=False)
@app.route('/')
def hello_world():session['sb']='jason'return 'Hello World!'@app.route("/index")
def index():print(session['sb'])return "ok"if __name__ == '__main__':app.run()
使用2 (简单的方式)
from flask import Flask,session
import redis
from flask_session import Session
app = Flask(__name__)
app.config['SESSION_TYPE'] = 'redis'
app.config['SESSION_REDIS'] =redis.Redis(host='127.0.0.1',port='6379')
app.config['SESSION_KEY_PREFIX']="jason"
Session(app)@app.route('/')
def hello_world():session['sb']='jason'return 'Hello World!'@app.route("/index")
def index():print(session['sb'])return "ok"if __name__ == '__main__':app.run()
MySQL数据库下载:
https://www.jb51.net/article/203259.htm
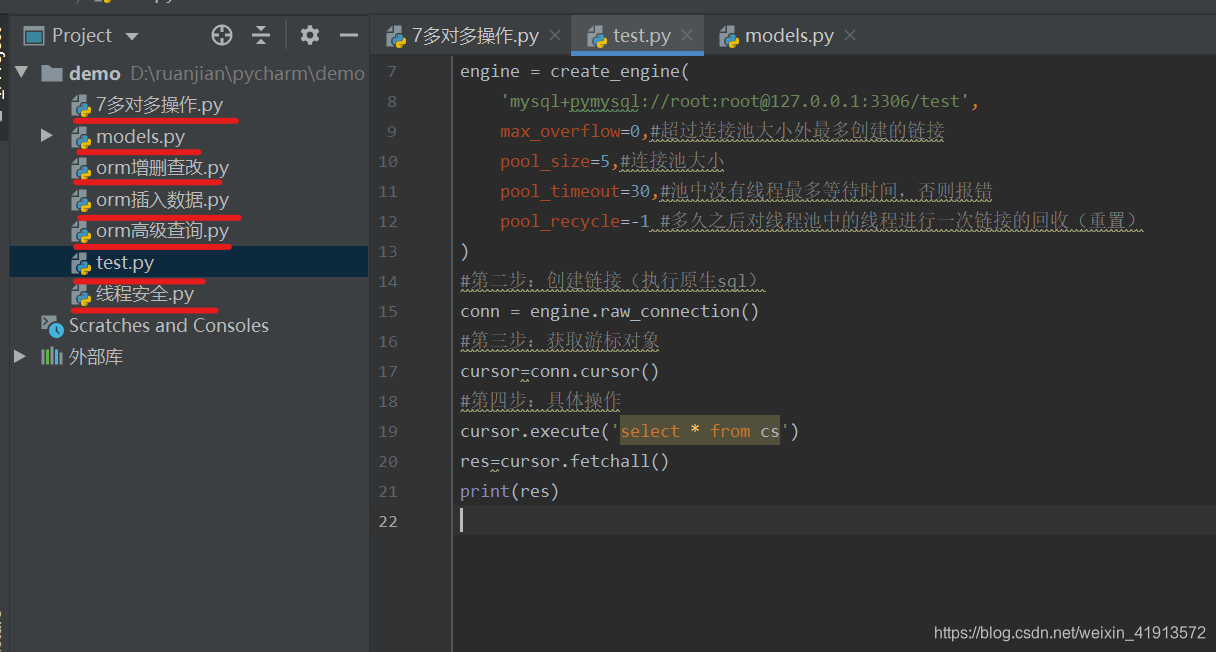
数据库连接池
import time #数据连接池demo
import threading
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.engine.base import Engine
#第一步生成一个engine对象
engine = create_engine('mysql+pymysql://root:root@127.0.0.1:3306/test',max_overflow=0,#超过连接池大小外最多创建的链接pool_size=5,#连接池大小pool_timeout=30,#池中没有线程最多等待时间,否则报错pool_recycle=-1 #多久之后对线程池中的线程进行一次链接的回收(重置)
)
#第二步:创建链接(执行原生sql)
conn = engine.raw_connection()
#第三步:获取游标对象
cursor=conn.cursor()
#第四步:具体操作
cursor.execute('select * from cs')
res=cursor.fetchall()
print(res)线程与安全
from sqlalchemy.orm import sessionmaker,scoped_session
from sqlalchemy import create_engine
from models import User
#1制作engine
engine= create_engine('mysql+pymysql://root:root@127.0.0.1:3306/aaa',max_overflow=0,pool_size=5)
#制造一个session类(会话)
Session= sessionmaker(bind=engine)
#得到session对象(线程安全的session)
#现在的session已经
session=scoped_session(Session)
#创建一个对象
obj1=User(name='22222')
#把对象通过add放入
session.add(obj1)
#提交
session.commit()#线程安全的情况下创造数据,此代码需 自己创建好表与列
models,创建表,一对多,多对多各种表
import datetime #c创建一个类(字段怎么写)
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship #这个加了以后多对多都可以把对象当作表明传过去了
#字段和字段属性
from sqlalchemy import Column,Integer,String,Text,ForeignKey,DateTime,UniqueConstraint,Index
#制造一个类,作为所有模型的基类
Base= declarative_base()
class User(Base):__tablename__='usere'#数据库表明固定写法————这个变量写啥表明叫啥id= Column(Integer,primary_key=True)#id 主键name=Column(String(32),index=True,nullable=True)#name列,索引,不可为空# email=Column(String(32),unique=True)#唯一# ctime=Column(DateTime,default=datetime.datetime.now())#default默认值——now()后面不能加时间,加了括号以后永远是当前时间# __table_args__=(# UniqueConstraint('id','name',name='uix_id_name'),#联合唯一# Index('ix_id_name','name','email'),#索引# )
#创建表
def create_table():# 创建engine对象engine = create_engine('mysql+pymysql://root:root@127.0.0.1:3306/aaa?charset=utf8',max_overflow=0, # 超过连接池大小外最多创建的链接pool_size=5, # 连接池大小pool_timeout=30, # 池中没有线程最多等待时间,否则报错pool_recycle=-1 # 多久之后对线程池中的线程进行一次链接的回收(重置))#通过engine对象创建表Base.metadata.create_all(engine)
#删除表
def drop_table():# 创建engine对象engine = create_engine('mysql+pymysql://root:root@127.0.0.1:3306/aaa?charset=utf8',max_overflow=0, # 超过连接池大小外最多创建的链接pool_size=5, # 连接池大小pool_timeout=30, # 池中没有线程最多等待时间,否则报错pool_recycle=-1 # 多久之后对线程池中的线程进行一次链接的回收(重置))# 通过engine对象删除表Base.metadata.drop_all(engine)
#一对多关系
class Hobby(Base):__tablename__='hobby'#表名id=Column(Integer,primary_key=True)#primary_key主键caption=Column(String(50),default='篮球')#default=如果没有默认值,则提供默认值
class Person(Base):__tablename__ = 'person' # 表名nid=Column(Integer,primary_key=True)#primary_key主键name=Column(String(32),index=True,nullable=True)#nullable=false是这个字段在保存时必需有值,index=True索引#hobby指的是tablename而不是类名,#一对多的关系,关联字段写在多的一方hobby_id=Column(Integer,ForeignKey('hobby.id'))#跟数据库无关,不会新增字段,只用于快速链表操作#类名,backref用于反向查询hobby=relationship('Hobby',backref='pers') #别人的表明 别名 以上我猜想的#多对多关系,实实在在存在表的————————————————————————————————————————————————————————————
class Boy2Girl(Base):__tablename__='boy2girl'id=Column(Integer,primary_key=True,autoincrement=True)#autoincrement=True自增,默认Truegirl_id=Column(Integer,ForeignKey('girl.id'))#链接girl表的idboy_id=Column(Integer,ForeignKey('boy.id'))#链接boy表的id
class Girl(Base):__tablename__='girl'id=Column(Integer,primary_key=True)#设置主键name=Column(String(64),unique=True,nullable=False)#nullable=false是这个字段在保存时必需有值 unique=唯一的
class Boy(Base):__tablename__='boy'id=Column(Integer,primary_key=True,autoincrement=True)#主键,自增hostname=Column(String(64),unique=True,nullable=False)#nullable=false是这个字段在保存时必需有值 unique=唯一的girls=relationship('Girl',secondary='boy2girl',backref='boys') #(别人的表明,通过哪个表关联,用于反向查询)if __name__ == '__main__':create_table() #调用开启函数#drop_table()#调用关闭函数#学到这里sqlalchemy 不支持创建库 不支持修改表orm高级查询
from sqlalchemy.orm import sessionmaker,scoped_session
from sqlalchemy import create_engine,between
from models import User
#1制作engine
engine= create_engine('mysql+pymysql://root:root@127.0.0.1:3306/aaa',max_overflow=0,pool_size=5)
#制造一个session类(会话)
Session= sessionmaker(bind=engine)
#得到session对象(线程安全的session)
#现在的session已经
# session=scoped_session(Session)
session=Session()#仅写代码用,因为他有智能提示
#1、查询名字######################################查询查询查询查询查询###################
#ret=session.query(User).filter_by(id=1).all()
#2、表达式,and条件链接
# ret=session.query(User).filter(User.id>1,User.name=='2443').all()
#3、查找id在1和10之间,并且name=***的对象
# ret=session.query(User).filter(User.id.between(1,10),User.name=='2443').all()
#4、in条件(class_,因为是关键字,不能直接用 直接取数组里面的)
# ret=session.query(User).filter(User.id.in_([1,11,12])).all()
# ~符号是取反,取反方向的数组
# ret=session.query(User).filter(~User.id.in_([1,2,12])).all()
#二次删选
# ret=session.query(User.id,User.name).filter(User.id.in_(session.query(User.id).filter_by(name='2443'))).all()
from sqlalchemy import and_,or_
# or_包裹的都是(or=或)条件,and_ 包裹的都是(and=且) 条件
# ret=session.query(User).filter(and_(User.id>1,User.name=='2443')).all()
# ret=session.query(User).filter(or_(User.id>1,User.name=='2443')).all()
#通配符查询 以*开头 不以*开头 ~可以取反
# ret=session.query(User.name).filter(User.name.like("2%")).all()
# ret=session.query(User.name).filter(User.name.like("2%")).all()
#限制、主要用于分页, 前能取到-后取不到,前闭后开
# ret=session.query(User.name)[1:3]
#排序。根据name 降序排列(从大到小)(desc从大到小、asc从小到大)
# ret=session.query(User.name).order_by(User.name.desc()).all()
# ret=session.query(User.name).order_by(User.name.asc()).all()
#、分组
#分组之后取最大id id之和 最小id, sql分组之后 要查询的字段 只能有分组字段 和聚合函数
from sqlalchemy.sql import func
# ret=session.query(
# func.max(User.id),#max=最大值
# func.sum(User.id),#sum=总和-
# func.min(User.id),#min=最小
# User.name
# ).group_by(User.name).all()#这句话是核心把(User.name)里面相同的分组 计算的是(User.id)的值,如果不用循环,就是过滤器
#
# for obj in ret:#别迷糊obj只是变量
# print(obj[0],"-----",obj[1],"-----",obj[2],"-----",obj[3])
######################################haviing筛选#################################
ret=session.query(func.max(User.id),#max=最大值func.sum(User.id),#sum=总和-func.min(User.id),#min=最小User.name).group_by(User.name).having(func.min(User.id>2)).all()#这句话是核心把重复值过滤了,在过滤id>2的
print(ret)#提交
session.commit()
#关闭链接,放回池中`
session.close()
orm插入数据
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from models import User
engine= create_engine('mysql+pymysql://root:root@127.0.0.1:3306/aaa',max_overflow=0,pool_size=5)
session=sessionmaker(bind=engine)
#每次执行数据库操作时,都需要创建一个connection
session=session()
#执行orm操作
obj1=User(name='lqz')
session.add(obj1)
#提交事物
session.commit()
#关闭session,其实是将链接放回连接池
session.close()
orm增删改查
from sqlalchemy.orm import sessionmaker,scoped_session
from sqlalchemy import create_engine
from models import User,Person,Hobby
#1制作engine
engine= create_engine('mysql+pymysql://root:root@127.0.0.1:3306/aaa',max_overflow=0,pool_size=5)
#制造一个session类(会话)
Session= sessionmaker(bind=engine)
#得到session对象(线程安全的session)
#现在的session已经
# session=scoped_session(Session)
session=Session()#仅写代码用,因为他有智能提示
#创建一个对象#############################增增增增增增增增增增增增增增##################################
# obj1=User(name='21111') #第一种放入方式
# obj2=User(name='test') #第一种放入方式
# session.add_all([obj1,obj2])#第一种放入方式
session.add_all([Person(name='测试'),Hobby()])#第二种放入方式
#######################################删除###########################################################
# session.query(User).filter_by(name='22222').delete()
# session.query(User).filter(User.id>=2).delete()
###############################改改改改改改改改改改改改改改改改########################################
# session.query(User).filter_by(id=1).update({'name':'测试是否可以写入'}) #修改方法1
# session.query(User).filter(User.id>0).update({User.name:User.name+'444'},synchronize_session=False) #文本相加写False
# session.query(User).filter(User.id>0).update({User.age:User.age+444},synchronize_session='evaluate')#数字相加,要'evaluate'
##################################查查查查查查查查查查查查查###########################################
# res=session.query(User).all() #查所有
# # print(type(res))
# res=session.query(User).filter() #查到以后用在filter()中添加过滤条件
# print(res)
#filter传的是表达式 filter_by传的是参数
# res=session.query(User).filter(User.id>1).all()
# res=session.query(User).filter_by(id=1).all()
# print(res)#提交
session.commit()
#关闭链接,放回池中
session.close()
一对多,多对多操作(增删改查)
from sqlalchemy.orm import sessionmaker,scoped_session
from sqlalchemy import create_engine,between
from models import User,Hobby,Person,Boy,Girl,Boy2Girl
#1制作engine
engine= create_engine('mysql+pymysql://root:root@127.0.0.1:3306/aaa',max_overflow=0,pool_size=5)
#制造一个session类(会话)
Session= sessionmaker(bind=engine)
#得到session对象(线程安全的session)
#现在的session已经
# session=scoped_session(Session)
session=Session()#仅写代码用,因为他有智能提示
######################################一对多插入数据##############################################
# obj=Hobby(caption='叼毛球')
# session.add(obj) #这是第一种方法
# p=Person(name='叼毛求',hobby_id=1)
# session.add(p)
#-----------------第二种方法----------默认情况下传对象有问题------------------
#Person 表中要加honny=relationship('Hobby',backref='pers')
# P=Person(name='李四',hobby=Hobby(caption='美女' ))
# Person一对多中的多表 hobby多表的变量 Hobby一对多中的一表 Hobby( 一对多中的一表行列内容可添加多个)
#-----------------第三种方法----------通过反向操作------------------
# hb=Hobby(caption='美女1') #第一个表添加数据,并实例化
# hb.pers=[Person(name='阳帅3'),Person(name='阳帅4')] #使用别名往里面添加数据
# session.add(hb)
######################################一对多查询数据###(基于连表查询,基于对象查询)#############################
#基于对象正查
# p=session.query(Person).filter_by(name='阳帅1').first()
# print(p.hobby.caption) #Person中的表通过name 正查到hobby表的内容
#基于对象反查
# h=session.query(Hobby).filter_by(caption='美女2').first()
# print(h.pers)
####基于连表的跨表查(查一次)、默认根据外键连表、
# person_list=session.query(Person,Hobby).join(Hobby,isouter=True).all()
# print(person_list) #(关联表,表)第二个括号(表)
# for row in person_list:
# print(row[0].name,row[1].caption)
############################################多对多查询数据############################
#########################增############### 第一种
# session.add_all([
# Boy(hostname='霍建华'),
# Boy(hostname='胡歌'),
# Girl(name='刘亦菲'),
# Girl(name='林心如')
# ])
# session.add_all([
# Boy2Girl(girl_id=1,boy_id=1),
# Boy2Girl(girl_id=1,boy_id=2)
# ])
#第二种
# girl=Girl(name='张娜拉1')
# girl.boys=[Boy(hostname='张铁林1'),Boy(hostname='费玉清1')] #为Boy表中别名boys
# session.add(girl)
#第三种
# boy=Boy(hostname='蔡徐坤')
# boy.girls=[Girl(name='谢娜'),Girl(name='巧碧螺')] # girls为Boy表中的变量
# session.add(boy)
########查查查查查查查查查查#####基于对象跨表查
# girl=session.query(Girl).filter_by(id=3).first()
# print(girl.boys)
#基于连表跨表查询
# ren=session.query(Girl.name).join(Boy2Girl).join(Boy).filter(Boy.hostname=='蔡徐坤').all()
#初步认为,在(在Girl.name中,目的地)-------(再去连表中)-----(再去Boy中 寻找表明叫 *** 的 {出发地})
ren=session.query(Girl.name).join(Boy2Girl).join(Boy).filter_by(hostname='蔡徐坤').all()
print(ren)#提交
session.commit()
#关闭链接,放回池中`
session.close()
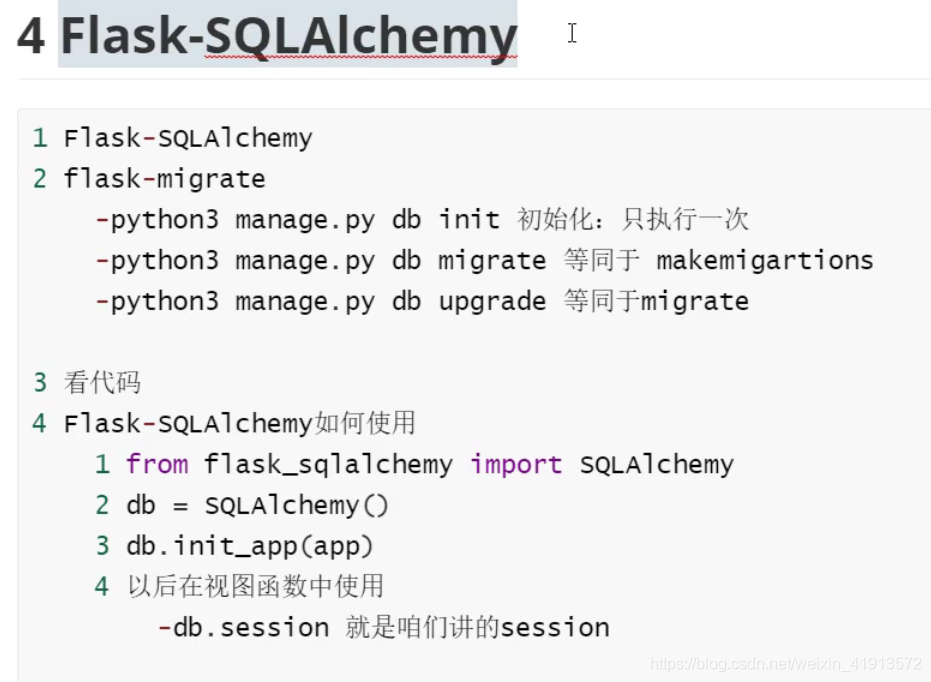
1 Flask-SQLAlchemy #操作
1 Flask-SQLAlchemy #操作
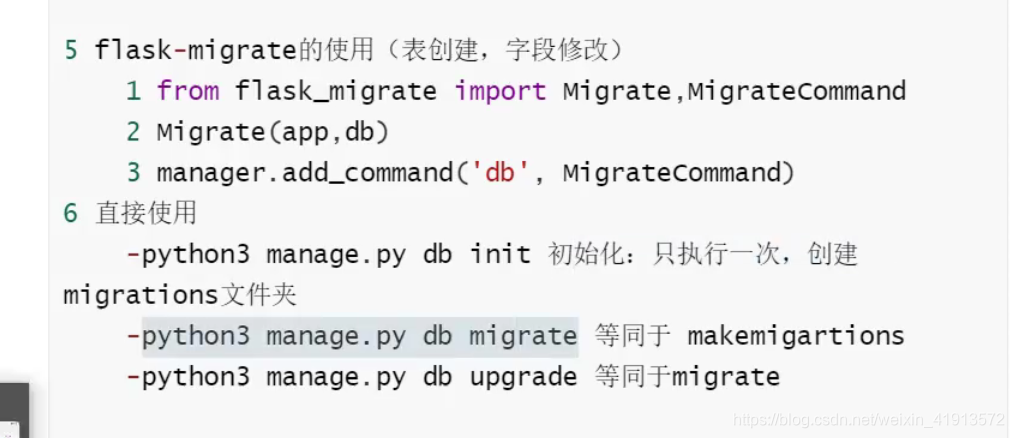
2 flask-migrate
python manage.py db init 初始化:只执行一次
python manage.py db migrate 等同于 makemigartions
python manage.py db upgrade 等同于 migrate
python manage.py runserver启动主文件
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!