ElasticSearch/Kibana/Logstash+SpringBoot的部署与使用
文章目录
- ElasticSearch/Kibana/Logstash
- 一、环境部署
- Docker
- 1 ElasticSearch/Kibana
- 2 elasticsearch-analysis-ik
- 3 Logstash(回头补充)
- 4 cerebro
- 5 更为简单的安装方法
- Linux
- Windows
- 1 服务端安装
- 2 中文分词器ik安装
- 3 监控端kibana安装
- 二、基本使用
- 2.1 相关名词
- 属性概念
- HTTP方法
- 自动映射规则
- 倒排索引
- 2.2 Kibana操作使用
- 操作映射
- 操作文档
- 普通查询
- DSL查询
- 其他查询方法
- 分词器的使用
- 2.3 SpringBoot项目集成
- 2.4 RestHighLevelClient
- 创建索引
- 还有非常多的Api操作
- 2.5 ElasticsearchRepository
- 示例代码
- 1 实体类
- 2 继承类接口
- 3 使用
- 没时间写,未完待续.....
- over
ElasticSearch/Kibana/Logstash
| 文章 |
|---|
| Elasticsearch:官方分布式搜索和分析引擎 | Elastic |
| ElasticSearch常用命令 - 简书 (jianshu.com) |
| 更简单的docker搭建elk+cerebro环境 - 小跑跑泡 - 博客园 (cnblogs.com) |
一、环境部署
建议使用docker,其他部署的方式屁事太多了,bug调的心情都不好了
Docker
先把国内源换上,然后
1 ElasticSearch/Kibana
## 拉镜像
docker pull elasticsearch:7.8.0
docker pull kibana:7.8.0
docker pull logstash:7.8.0
## 启动
docker run -d --name elasticsearch780 -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.8.0
docker run -d --name kibana780 --link elasticsearch780:elasticsearch -p 5601:5601 kibana:7.8.0
这个链接可能还不够,我们进去kibana里面的config改一下IP指向(宿主机IP:Port),然后重启容器
访问http://192.168.247.177:5601/,开启你的春天
2 elasticsearch-analysis-ik
在线安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.8.0/elasticsearch-analysis-ik-7.8.0.zip
3 Logstash(回头补充)
docker run -d --name=logstash780 -p 5044:5044 logstash:7.8.0
修改config文件

先不研究了,暂时没精力
4 cerebro
docker pull yannart/cerebro
docker run -d --name cerebro -p 9000:9000 yannart/cerebro
然后访问
http://192.168.247.177:9000/
简直酷的不行
5 更为简单的安装方法
docker pull sebp/elk
docker run -p 5601:5601 -p 9200:9200 -p 5044:5044 -e ES_MIN_MEM=128m -e ES_MAX_MEM=1024m -it --name elk sebp/elk
Linux
# 官网下载包,解压
wget -i -c https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.4.0-linux-x86_64.tar.gz
# 创建es用户,软件禁止使用Root用户启动
groupadd es
useradd es -g es
passwd es# 目录赋权
chown -R es:es elasticsearch-7.4.0# 进入config目录修改yml文件,追加如下配置
network.host: 0.0.0.0
http.port: 9200
equire explicit names when deleting indices:
http.cors.enabled: true
http.cors.allow-origin: "*"
xpack.ml.enabled: false
cluster.initial_master_nodes: ["node-1"] #这里的node-1为node-name配置的值# 追加修改limits文件,不然启动时会出现error提示内存不足
# max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
vim /etc/security/limits.conf
* soft nofile 65536
* hard nofile 65536
* soft nproc 5000
* hard nproc 5000
root soft nproc 5000
root hard nproc 5000vim /etc/sysctl.conf
vm.max_map_count=262144# 最后,进入bin目录,启动程序
./bin/elasticsearch
Windows
装这些东西挺烦的
第三个是可视化界面,可以不装
1 服务端安装
首先安装第一个
修改elasticsearch.yml文件
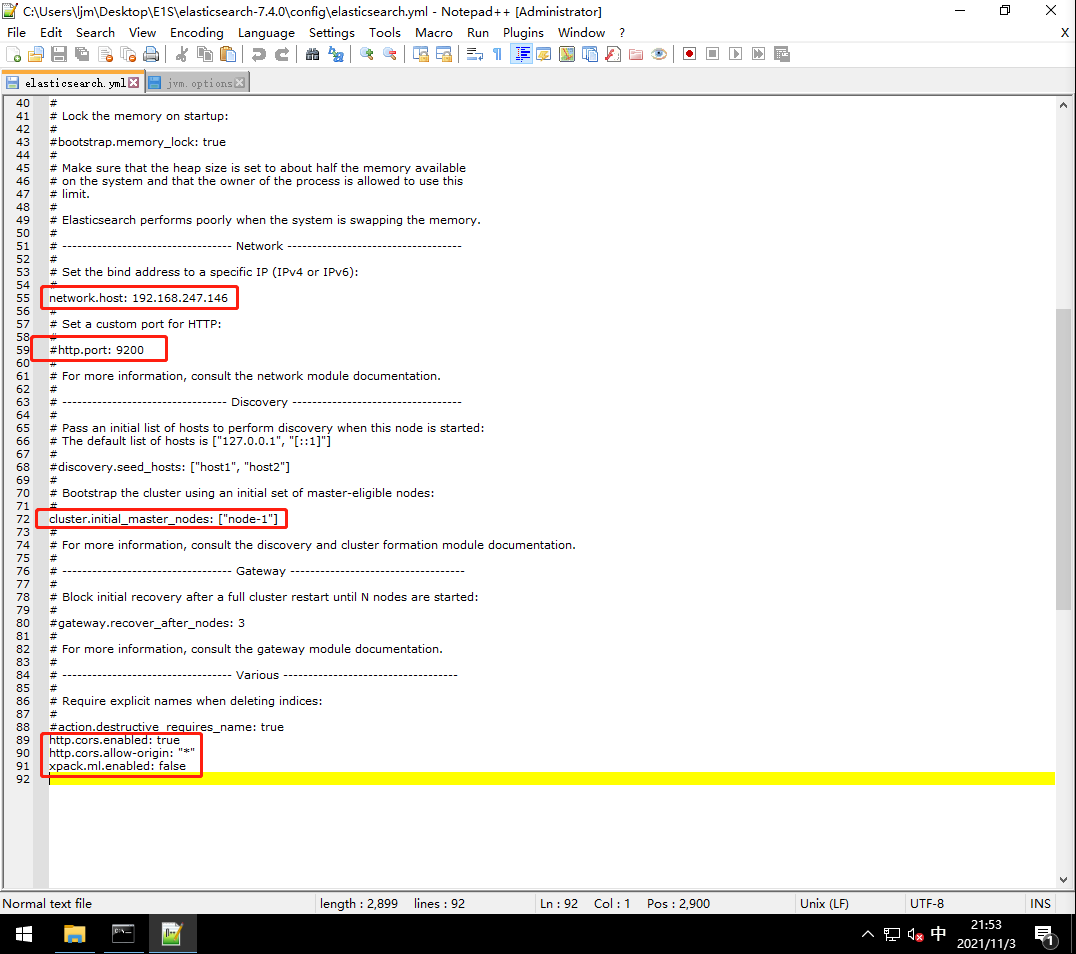
2 中文分词器ik安装
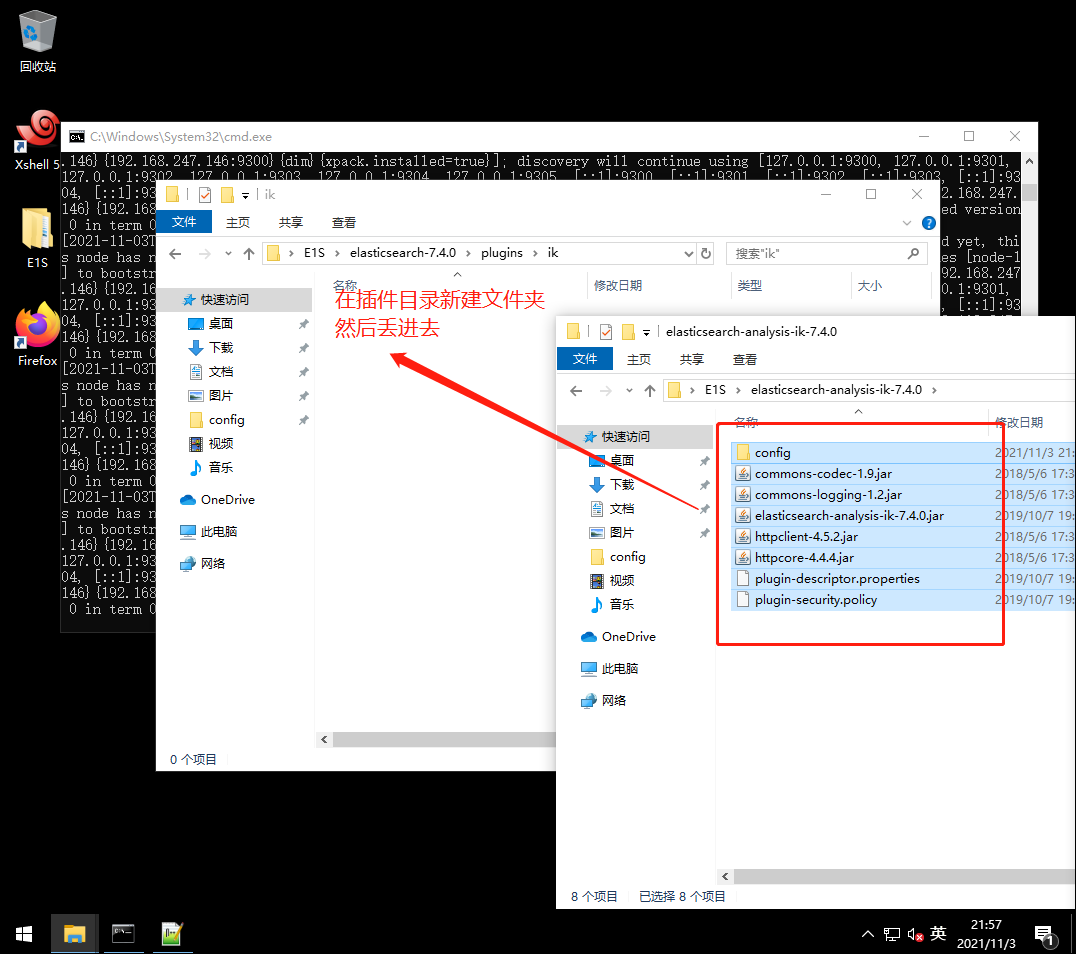
3 监控端kibana安装
这个比较无脑,改一个config文件的指向地址就行了,这里就不细说了
二、基本使用
目前SpringBootDataES那个模板已经预备弃用了,所以不要用那个了
2.1 相关名词
属性概念
| 关键字名称 | 名词解释 | 对应SQL |
|---|---|---|
| 索引 index | 在我们建立索引之后,可以直接往索引中写入文档 | 库 |
| 类型 type | 字段的类型,例如是short类型还是integer类型 | 类型 |
| 字段 Field | 相当于是数据表的字段,字段在ES中可以理解为JSON数据的键 | 字段 |
| 映射mapping | 映射是对文档中每个字段的类型进行定义,类似说是short类型还是integer类型;;但是在es已经实现了动态映射,我们并不需要特意去创建映射,它也有相应的规则来应对映射,看下面的图片 | 表 |
| 文档(_doc) document | 在ES中相当于传统数据库中的行的概念,ES中的数据都以JSON的形式来表示,在MySQL中插入一行数据和ES中插入一个JSON文档是一个意思 | 实际数据 |
| 元数据 metadata | 一个文档不只有数据。它还包含了元数据(metadata)——关于文档的信息。三个必须的元数据节点是:index(文档存储位置)、type(类型)、id(文档的唯一标识) | 描述 |
HTTP方法
| HTTP方法 | 说明 |
|---|---|
| GET | 获取请求对象的当前状态 |
| POST | 改变对象的当前状态 |
| PUT | 创建一个对象 |
| DELETE | 销毁对象 |
| HEAD | 请求获取对象的基础信息 |
自动映射规则
自动判断的规则如下

支持的类型如下

你学废了吗
倒排索引
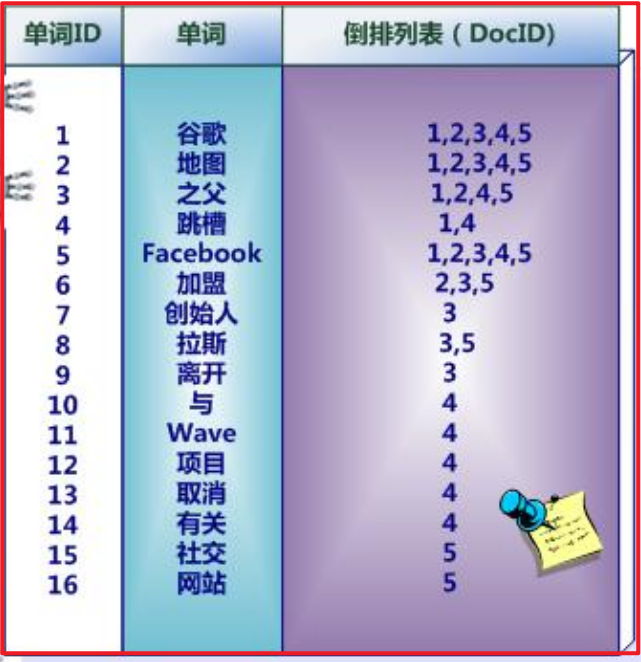
2.2 Kibana操作使用
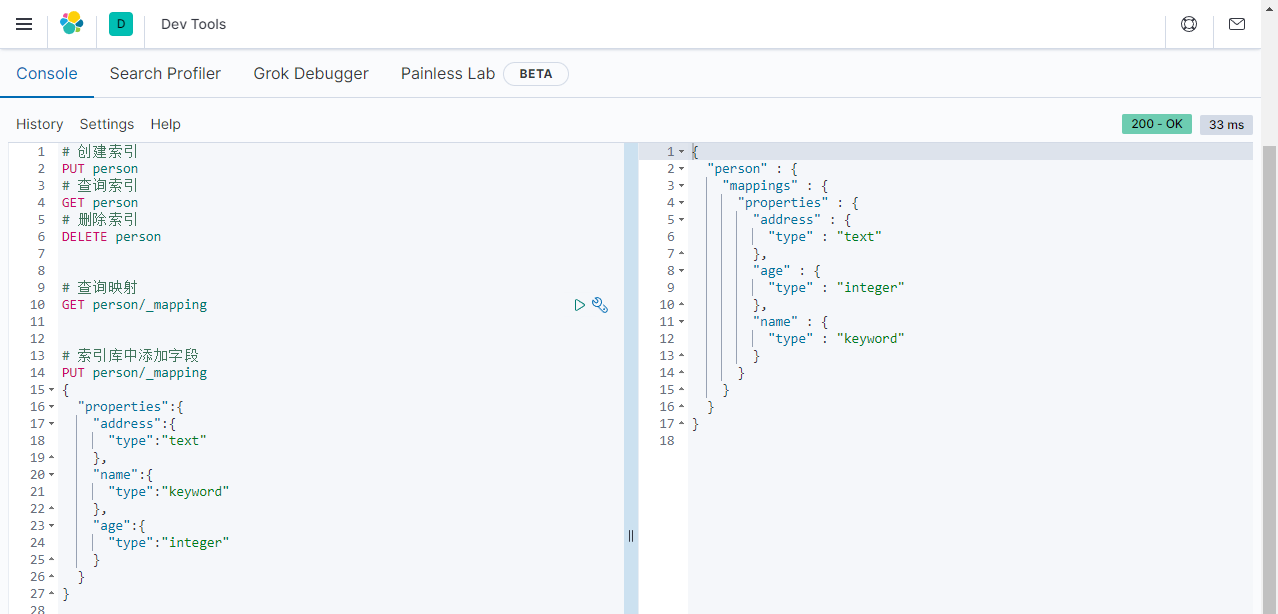
操作映射
# 创建索引
PUT person
# 查询索引
GET person
# 删除索引
DELETE person
# 查询映射
GET person/_mapping
# 索引库中添加字段
PUT person/_mapping
{"properties":{"address":{"type":"text"},"name":{"type":"keyword"},"age":{"type":"integer"}}
}
操作文档
# 添加文档,指定id
PUT person/_doc/1
{"name":"张三","age":20,"address":"深圳宝安区"
}# 查询文档
GET person/_doc/1# -----# 添加文档,不指定id
POST person/_doc/
{"name":"李四","age":20,"address":"深圳南山区"
}# 查询文档
GET person/_doc/c5-l8HwBuywWr9m6rrmr# -----# 查询所有文档
GET person/_search# 删除文档
DELETE person/_doc/1# 修改文档 根据id,id存在就是修改,id不存在就是添加
PUT person/_doc/2
{"name":"硅谷","age":20,"address":"深圳福田保税区"
}
普通查询
# 全文查询-match查询
# match 先会对查询的字符串进行分词,在查询,求交集
# 很像模糊匹配查询
GET person/_search
{"query": {"match": {"address": "南山"}}
}# ---# 查询所有数据
GET person/_search# 查询 深开头的数据
GET person/_search
{"query": {"term": {"address": {"value": "深"}}}
}# ---# 查询名字等于张三的用户
GET person/_search?q=name:张三
DSL查询
做一些数据出来
get person/_searchput person/_doc/101
{"name":"t1","age":21,"address":"釜山市晋城县"
}put person/_doc/102
{"name":"t2","age":23,"address":"北京市三里屯"
}put person/_doc/103
{"name":"t3","age":25,"address":"广州市天河区"
}put person/_doc/104
{"name":"t4","age":51,"address":"广州市白云区"
}
玩起来
get person/_search# 根据年龄查询
POST person/_doc/_search
{"query":{"match":{"age":20}}
}# 查询年龄大于20岁 在深圳的 并且高亮显示
GET person/_doc/_search
{"query":{"bool":{"filter":{"range":{"age":{"gt":19}}},"must":{"match":{"address":"深圳"}}}},"highlight": {"fields": {"address": {}}}
}
其他查询方法
get person/_search# group by
# 这里的terms可以指定多个匹配条件
GET person/_search
{"aggs": {"all_interests": {"terms": {"field": "age"}}}
}# 指定返回数据的响应字段
GET person/_doc/101?_source=id,name,address# 判断文档是否存在 存在返回200 - OK
HEAD person/_doc/101
分词器的使用
刚开始我们装了分词器,现在解释一下ik里面的两个分词算法
- ik_smart 最少切分
- ik_max_word 最细粒度划分
可以用作映射里的type类型
2.3 SpringBoot项目集成
上面说了这么多,但是我们是Java开发,还得从SpringBoot入手
导入依赖,这里的依赖版本对应你的es版本
<dependencies><dependency><groupId>junitgroupId><artifactId>junitartifactId><scope>testscope>dependency><dependency><groupId>org.springframework.bootgroupId><artifactId>spring-boot-starter-testartifactId>dependency><dependency><groupId>org.projectlombokgroupId><artifactId>lombokartifactId>dependency><dependency><groupId>org.springframework.bootgroupId><artifactId>spring-boot-devtoolsartifactId>dependency><dependency><groupId>org.springframework.bootgroupId><artifactId>spring-boot-starterartifactId>dependency><dependency><groupId>org.springframework.bootgroupId><artifactId>spring-boot-starter-data-elasticsearchartifactId>dependency><dependency><groupId>com.alibabagroupId><artifactId>fastjsonartifactId>dependency>dependencies>
配置yaml文件
server:port: 19200spring:elasticsearch:rest:uris: 192.168.247.177:9200
测试
@RunWith(SpringRunner.class)
@SpringBootTest
public class TestEs {@Autowiredprivate RestHighLevelClient restHighLevelClient;@Testpublic void contextLoads() throws IOException {CreateIndexRequest request = new CreateIndexRequest("user");CreateIndexResponse response = restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);boolean acknowledged = response.isAcknowledged();System.out.println(acknowledged);}
}
2.4 RestHighLevelClient
创建索引
@RunWith(SpringRunner.class)
@SpringBootTest
public class TestEs {@Autowiredprivate RestHighLevelClient restHighLevelClient;@Testpublic void contextLoads() throws IOException {// 1.使用client获取操作索引的对象IndicesClient indicesClient = restHighLevelClient.indices();// 2.具体操作,获取返回值CreateIndexRequest createRequest = new CreateIndexRequest("indexName");CreateIndexResponse response = indicesClient.create(createRequest, RequestOptions.DEFAULT);// 3.根据返回值判断结果System.out.println(response.isAcknowledged());}
}
还有非常多的Api操作
我就不一一写了
| api文档 |
|---|
| Document APIs | Java REST Client Elastic |
| Java High Level REST Client 中文API(仅供参考)_含江君-CSDN博客 |
| https://gitee.com/li-xiaoming411/drawing-bed/raw/master/RestHighLevelClient-Run.rar |
2.5 ElasticsearchRepository
示例代码
1 实体类
封装好的实体类对象,用于与es交互
@Data
@Document(indexName = "goods", type = "info", shards = 3, replicas = 1)
public class Goods {/*** 商品Id*/@Idprivate Long id;/*** 默认图片*/@Field(type = FieldType.Keyword, index = false)private String defaultImg;/*** title = skuName*/@Field(type = FieldType.Text, analyzer = "ik_max_word")private String title;/*** 商品价格*/@Field(type = FieldType.Double)private Double price;/*** 创建时间*/@Field(type = FieldType.Date)private Date createTime;/*** 品牌Id*/@Field(type = FieldType.Long)private Long tmId;/*** 品牌名称*/@Field(type = FieldType.Keyword)private String tmName;/*** 品牌的logo*/@Field(type = FieldType.Keyword)private String tmLogoUrl;/*** 一级分类Id*/@Field(type = FieldType.Long)private Long category1Id;@Field(type = FieldType.Keyword)private String category1Name;@Field(type = FieldType.Long)private Long category2Id;@Field(type = FieldType.Keyword)private String category2Name;@Field(type = FieldType.Long)private Long category3Id;@Field(type = FieldType.Keyword)private String category3Name;/*** 热度排名*/@Field(type = FieldType.Long)private Long hotScore = 0L;/*** 平台属性集合对象* Nested 支持嵌套查询*/@Field(type = FieldType.Nested)private List<SearchAttr> attrs;
}
2 继承类接口
@Component
public interface GoodsElasticsearchRepository extends ElasticsearchRepository<Goods, Long> {
}
3 使用
直接看代码吧,你看得懂的
@Overridepublic void cancelSale(Long skuId) {goodsElasticsearchRepository.deleteById(skuId);}@Overridepublic void onSale(Long skuId) {// 数据映射Goods goods = new Goods();goods.setId(skuId);goods.setHotScore(0L);// 各种set方法.....省略// 插入数据goodsElasticsearchRepository.save(goods);}@Overridepublic void createGoods() {// 创建索引,插入映射elasticsearchRestTemplate.createIndex(Goods.class);elasticsearchRestTemplate.putMapping(Goods.class);}
}
1
没时间写,未完待续…
over
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!