定制utf8字符集的mysql镜像避免后期字符集大坑
一、关于字符集
字符编码(英语:Character encoding)、字集码是把字符集中的字符编码为指定集合中某一对象(例如:比特模式、自然数序列、8位组或者电脉冲),以便文本在计算机中存储和通过通信网络的传递。常见的例子包括将拉丁字母表编码成摩斯电码和ASCII。其中,ASCII将字母、数字和其它符号编号,并用7比特的二进制来表示这个整数。通常会额外使用一个扩充的比特,以便于以1个字节的方式存储。
在计算机技术发展的早期,如ASCII(1963年)和EBCDIC(1964年)这样的字符集逐渐成为标准。但这些字符集的局限很快就变得明显,于是人们开发了许多方法来扩展它们。对于支持包括东亚CJK字符家族在内的写作系统的要求能支持更大量的字符,并且需要一种系统而不是临时的方法实现这些字符的编码。
二、关于字符编码的各种标准
1、基础标准字符集 ASCII与EASCII, 美国信息交换机标准代码,共定义了128个字符;其中33个字符无法显示(一些终端提供了扩展,使得这些字符可显示为诸如笑脸、扑克牌花式等8-bit符号)
2、西欧标准编码
- ISO-8859-1 最常见西欧标准编码,mysql数据库中默认编码
- ISO-8859-5
- ISO-8859-6
- ISO-8859-7
- ISO-8859-11
- ISO-8859-15
- ISO/IEC 646
3、亚洲字符集
台湾地区:BIG5、CCCII、CNS 11643、EUC(全名为Extended Unix Code,是一个使用8位编码来表示字符的方法)EUC-TW
日本:ISO/IEC 2022、EUC-JP
港澳台地区:GB2312、EUC、GBK(GB13000)、GB18030
朝鲜半岛:EUC-KR、KOI8-R等
4、Unicode字符集
看到前面这么多种类的编码字符集,我都快晕了,幸亏出来了unicode编码统一江湖。Unicode的实现方式称为Unicode转换格式,它的长度不是固定的。
万国码、国际码、统一码、单一码)是计算机科学领域里的一项业界标准。它对世界上大部分的文字系统进行了整理、编码,使得计算机可以用更为简单的方式来呈现和处理文字。
Unicode发展由非营利机构统一码联盟负责,该机构致力于让Unicode方案取代既有的字符编码方案。因为既有的方案往往空间非常有限,亦不适用于多语环境。
Unicode备受认可,并广泛地应用于计算机软件的国际化与本地化过程。有很多新科技,如可扩展置标语言(Extensible Markup Language,简称:XML)、Java编程语言以及现代的操作系统,都采用Unicode编码。
- UTF-7
- 全称:7比特Unicode转换格式)是一种可变长度字符编码方式,用以将Unicode字符以ASCII编码的字符串来呈现,可以应用在邮箱传输之类的应用,SMTP为基本的邮箱传输标准之一,其指明了传输格式为US-ASCII,并且不允许超过ASCII所定义的字符范围以外的比特值,也就是说八比特的字符串将无法正常的被传输。
- UTF-8
- 8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,也是一种前缀码。它可以用来表示Unicode标准中的任何字符,且其编码中的第一个字节仍与ASCII兼容,这使得原来处理ASCII字符的软件无须或只须做少部分修改,即可继续使用。因此,它逐渐成为邮箱、网页及其他存储或发送文字的应用中,优先采用的编码。
- UTF-16
- 是Unicode字符编码五层次模型的第三层:字符编码表(Character Encoding Form,也称为"storage format")的一种实现方式。即把Unicode字符集的抽象码位映射为16位长的整数(即码元)的序列,用于数据存储或传递。Unicode字符的码位,需要1个或者2个16位长的码元来表示,因此这是一个变长表示。
- UTF-32
- 与其他可变长度的Unicode转换格式(UTF)相比,UTF-32编码长度是固定的,UTF-32中的每个32位值代表一个Unicode码位,并且与该码位的数值完全一致。
三、字符集的个人理解总结
1、字符集的复杂主要是因为世界上文字主要分为两大类,表音的英文、西欧文字等与表义的中文、日文等,表音的文字是由几十个基础字母变换构成,对于存储来说一个字节足够,但是表意的文字每个都不一样需要单独表达,数量非常庞大,有数十万,常用的也有大几千,存储表意的文字需要至少2个字节多则4个字节,一句话:存储位数的限制导致复杂;
2、计算机发展的基础导致各自为政
近代计算机发展速度非常快,由西方发明引入,西方设计发展计算机的时候根本不需要统筹考虑表意文字的人该如何通过计算机进行表达,这些问题只有用计算机的国家感觉到不方便才会推动计算机在本国的发展规划设计本国的字符集编码,所以在计算机发展过程中,互联网普及之前字符集是各自为战的阶段野蛮发展,所以非常庞杂;
3、互联网高度发达的今天要求各国文字快速转换,随着互联网的高速发展必然导致大一统的万能编码Unicode的出现。
四、mysql数据库的字符集
1、使用mysql5.7默认镜像,查看数据库镜像使用的默认字符集
docker run -d --rm --name=mysqlserver -e MYSQL_ROOT_PASSWORD=12345678abc mysql/mysql-server:5.7

这种情况下存储中文字符是一定会失败并且出现乱码的,我查看mysql在其官网上公布的方法试一下如发生什么
2、采用mysql官网公布方法启动镜像,查看数据库启动字符集
docker run -d --rm --name=mysqlserver -e MYSQL_ROOT_PASSWORD=12345678abc mysql/mysql-server:5.7 --character-set-server=utf8mb4 --collation-server=utf8mb4_unicode_ci

show variables like "%character%";
可以看到这种方法还有character_set_client等三项内容是默认为西欧字符集的,这种情况下使用数据库存储数据,会出现乱码现象。
3、定制自己的utf8编码专有镜像

本地目录创建data目录,准备后面启动实例时挂载本地目录保存mysql数据,否则实例退出后数据全部丢失,创建mysqld_charset.cnf配置文件已经一个Dockerfile文件
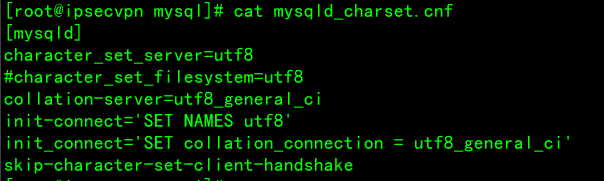
mysqld_charset.cnf配置文件内容
[mysqld]
character_set_server=utf8
collation-server=utf8_general_ci
init-connect='SET NAMES utf8'
init_connect='SET collation_connection = utf8_general_ci'
skip-character-set-client-handshake
Dockerfile文件内容
FROM mysql:5.7
COPY mysqld_charset.cnf /etc/mysql/conf.d/mysqld_charset.cnf

编译生成自己的utf8-mysql镜像
docker build -t mysqlutf8:v1 .

编译生成成功,使用docker images查看本地镜像

docker run --name=mysqlserver -d --rm -v "$PWD/data":/var/lib/mysql -e MYSQL_ROOT_PASSWORD=12345678abc -e MYSQL_DATABASE=mpcdb -e TZ=Asia/Shanghai -p 3306:3306 mysqlutf8:v1
加载使用mysqlutf:v1新镜像,将本地data目录作为存储mysql的卷加载,并新创建了一个业务数据库mpcdb,对外发布端口3306,时区默认设置为格林威治时间,需要通过TZ变量设置为中国时区,否则在数据库中显示的就不是北京时间。

下面使用docker exec -it mysqlserver bash 登陆容器内部查看mysql数据库启动的字符集如何

如果实例需要通过外部进行访问,需要在数据库中对用户的远程访问权限进行显式授权,比如运行root用户通过133.3这个网段进行访问数据库就需要执行下面的语句,后面有方法介绍通过docker启动参数调整直接对用户访问网络授权。
grant all privileges on *.* to 'root@133.3.%' identified by '12345678abc' with grant option;

五、总结
1、使用docker inspect mysqlserver查看学习mysql在docker中的配置结构


2、关于mysql容器中非常有用的环境变量说明
-
MYSQL_RANDOM_ROOT_PASSWORD:当此变量为true(这是默认状态,除非MYSQL_ROOT_PASSWORD已设置或MYSQL_ALLOW_EMPTY_PASSWORD设置为true)时,将在启动Docker容器时生成服务器root用户的随机密码。密码打印到stdout容器中,可以通过查看容器的日志找到。 -
注意
有没有必要使用这种机制创建根超级用户,这是默认与在描述所讨论的机制的任何一个设置密码创建
MYSQL_ROOT_PASSWORD和MYSQL_RANDOM_ROOT_PASSWORD,除非MYSQL_ALLOW_EMPTY_PASSWORD是真的。 -
docker run --name=mysqlserver -d --rm -v "$PWD/data":/var/lib/mysql -e MYSQL_ROOT_PASSWORD=12345678abc -e MYSQL_DATABASE=mpcdb -e TZ=Asia/Shanghai -e MYSQL_ROOT_HOST="133.3.%" -p 3306:3306 mysqlutf8:v1
-
上面这段启动mysql容器的代码可以实现:
-
初始化root密码
-
新建业务数据库
-
指定数据库时区为上海
-
对root账号的外部访问网络予以授权
-
将容器内部的3306端口接入到主机物理网络暴露给外部调用
-
完整彻底的支持中文UTF8编码
-
注意
如果已装入主机的服务器配置文件,则该变量无效(请参阅 绑定装配配置文件时的保持数据和配置更改)。
-
MYSQL_ROOT_PASSWORD:此变量指定为MySQL root帐户设置的密码。警告
在命令行上设置MySQL root用户密码是不安全的。作为显式指定密码的替代方法,您可以使用容器文件路径为密码文件设置变量,然后从主机中装入包含容器文件路径中密码的文件。这仍然不是很安全,因为密码文件的位置仍然暴露。最好使用默认设置,
MYSQL_RANDOM_ROOT_PASSWORD并且MYSQL_ONETIME_PASSWORD两者都为真。 -
将此变量设置为true是不安全的,因为它会使您的MySQL实例完全不受保护,从而允许任何人获得完整的超级用户访问权限。最好使用默认设置,
MYSQL_RANDOM_ROOT_PASSWORD并且MYSQL_ONETIME_PASSWORD两者都为真。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!