多语言文字半自动标注及识别训练(ZSTU智能科学与技术专业实习)
多语言文字半自动标注及识别训练(ZSTU智能科学与技术专业实习)
ZSTUGWH
1、用户注册与登陆
关注微信公众号“晓图天下”,然后打开网页http://tag.hongeasy.com.cn/pclogin/login使用微信扫码登录
加入群组:测试小组
口令:123123
点击数据集管理后在这里命名两级目录后进入

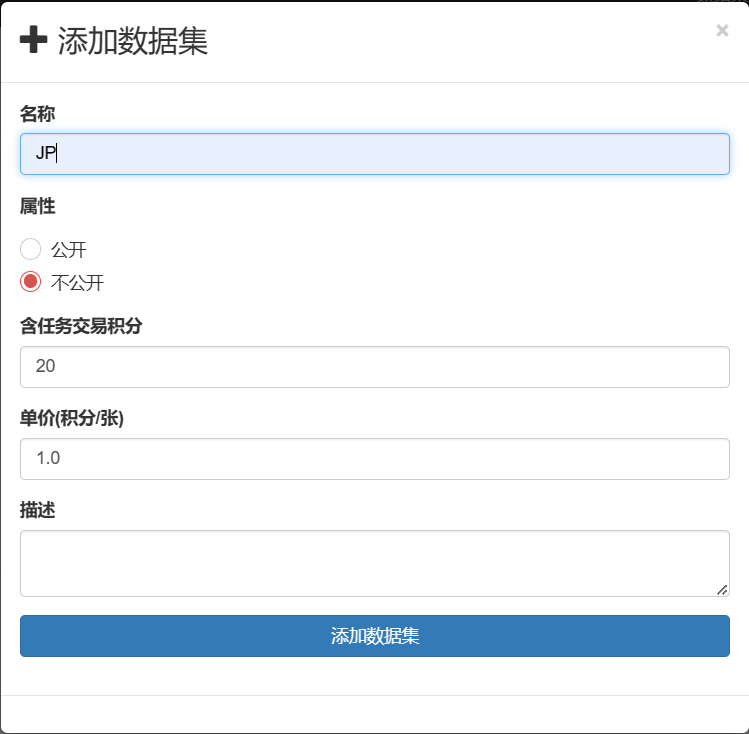
添加数据集,任意命名
2、合成数据集生成
具体使用方式可查看:https://github.com/Belval/TextRecognitionDataGenerator
由于本专业实习只要求日语识别,也可按照以下步骤:
本地cmd
pip install trdg
在某个目录下,运行
trdg -l ja -c 100 -w 1
# ja为Japanese,100为生成数量,1为拆分单词数量

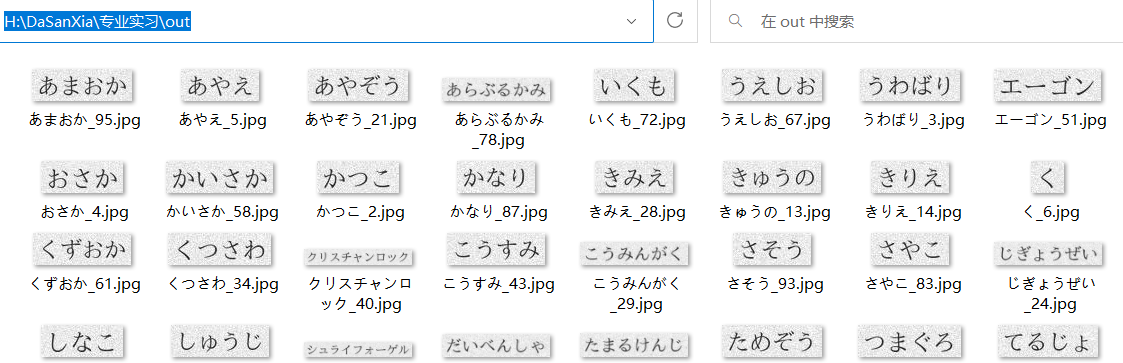
此时可以发现在该目录下多了out文件夹,该文件夹下为日语图片数据集
3、数据集标注与导出
导入
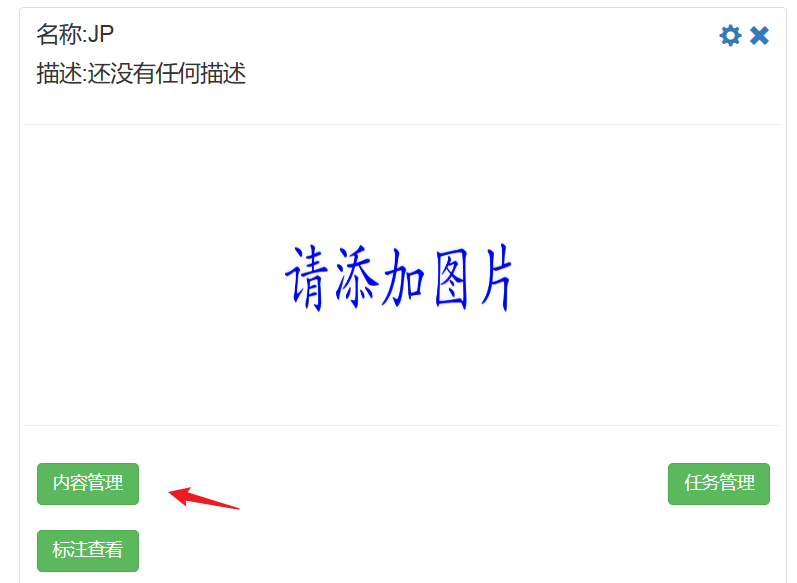
回到第一步的平台,数据集中点击内容管理->OCR图片上传
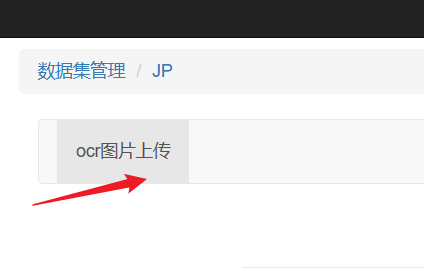
将第二步生成的图片导入即可
任务标注
回到数据集,点击任务管理->添加个人任务,命名任意
点击标注任务

发现已有新的标注任务
点击标注,开始标注
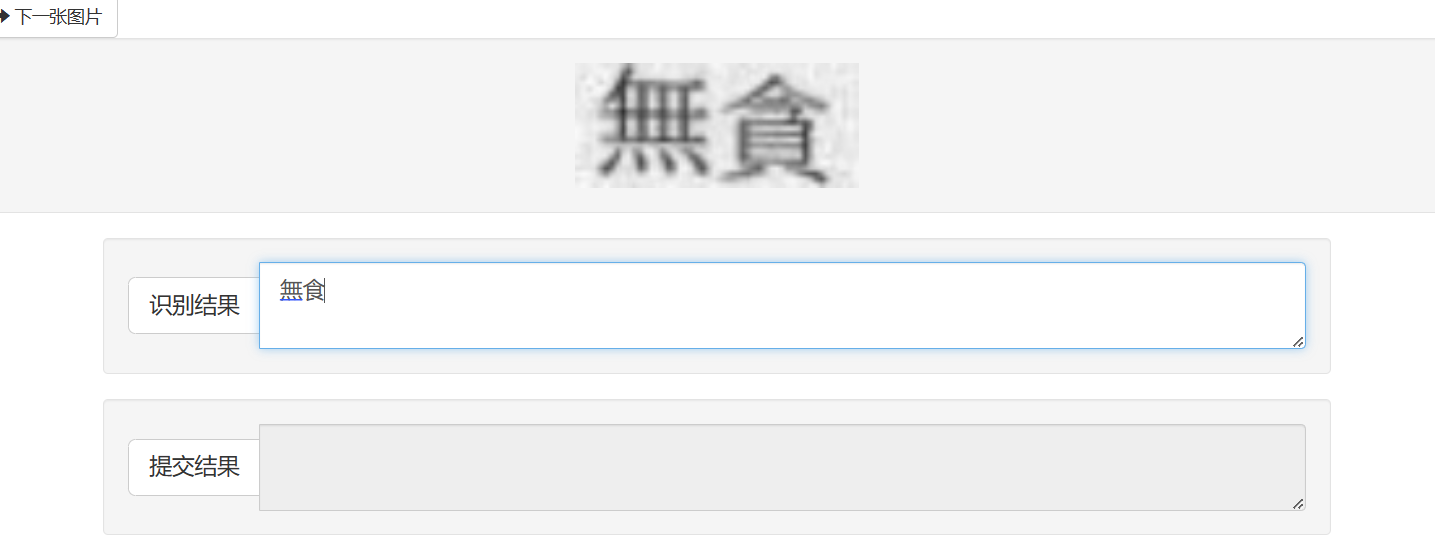
将正确的结果输入到识别结果中,点击接受
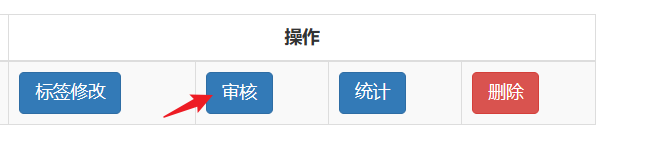
全部标注完之后,回到数据集,点击任务管理,审核
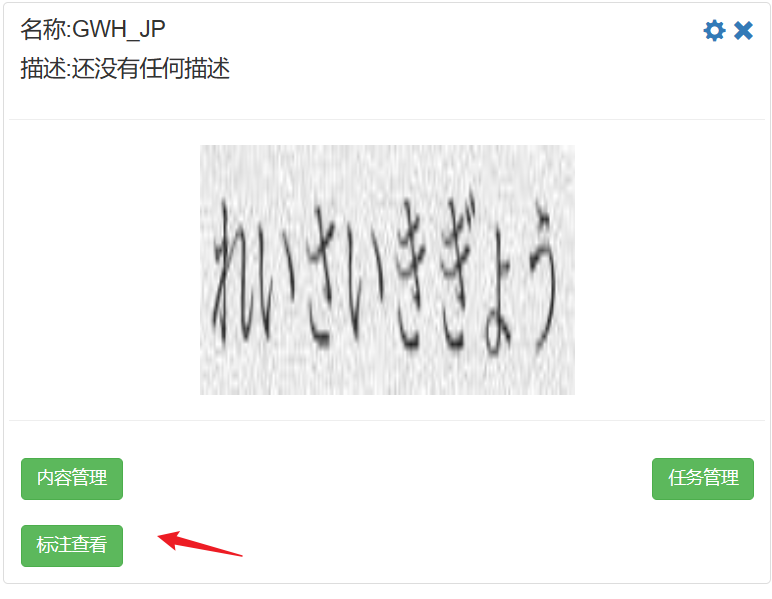
审核完之后,回到数据集,点击标注查看
导出
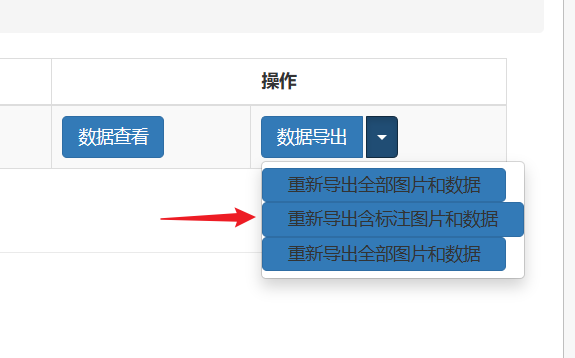
下载解压后可以看到label.txt文件,图片在JPEGImages中

改进数据集标注方法
我觉得
上面的标注太麻烦了,而且用trdg生成的数据集,图片名字即为标注,那写个脚本整理一下不就行了吗
import osdef get_image_filenames(directory):image_extensions = ['.jpg', '.jpeg', '.png']image_filenames = []for root, dirs, files in os.walk(directory):for file in files:if any(file.lower().endswith(ext) for ext in image_extensions):image_filenames.append(file)return image_filenamesdef write_to_txt(filenames, output_file):with open(output_file, 'w') as file:for filename in filenames:name = filename.split('_')[0]name = filename + "\t" + namefile.write(name + '\n')directory_path = 'train_data/'output_file_path = 'train_label.txt'image_filenames = get_image_filenames(directory_path)write_to_txt(image_filenames, output_file_path)print("end")
这样和上面导出的数据集和标注效果和平台上是一样的
不想折腾的直接用我的数据集
链接:https://pan.baidu.com/s/1Anszd9TKD5cJeS0tfY6v5g
提取码:gwh6
4、平台环境
百度飞桨平台https://aistudio.baidu.com/aistudio/index
创建项目
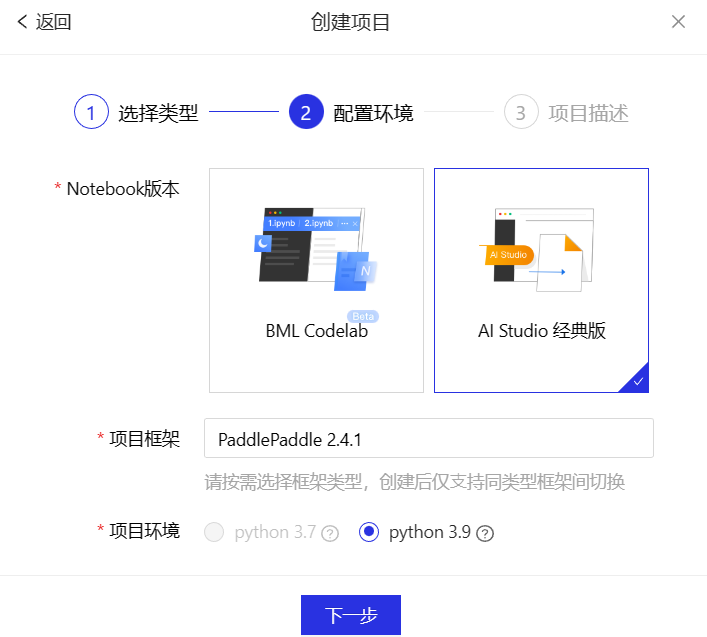
进入控制台
git clone https://github.com/PaddlePaddle/PaddleOCR.git
下载模型文件和yml配置
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/doc/doc_en/models_list_en.md
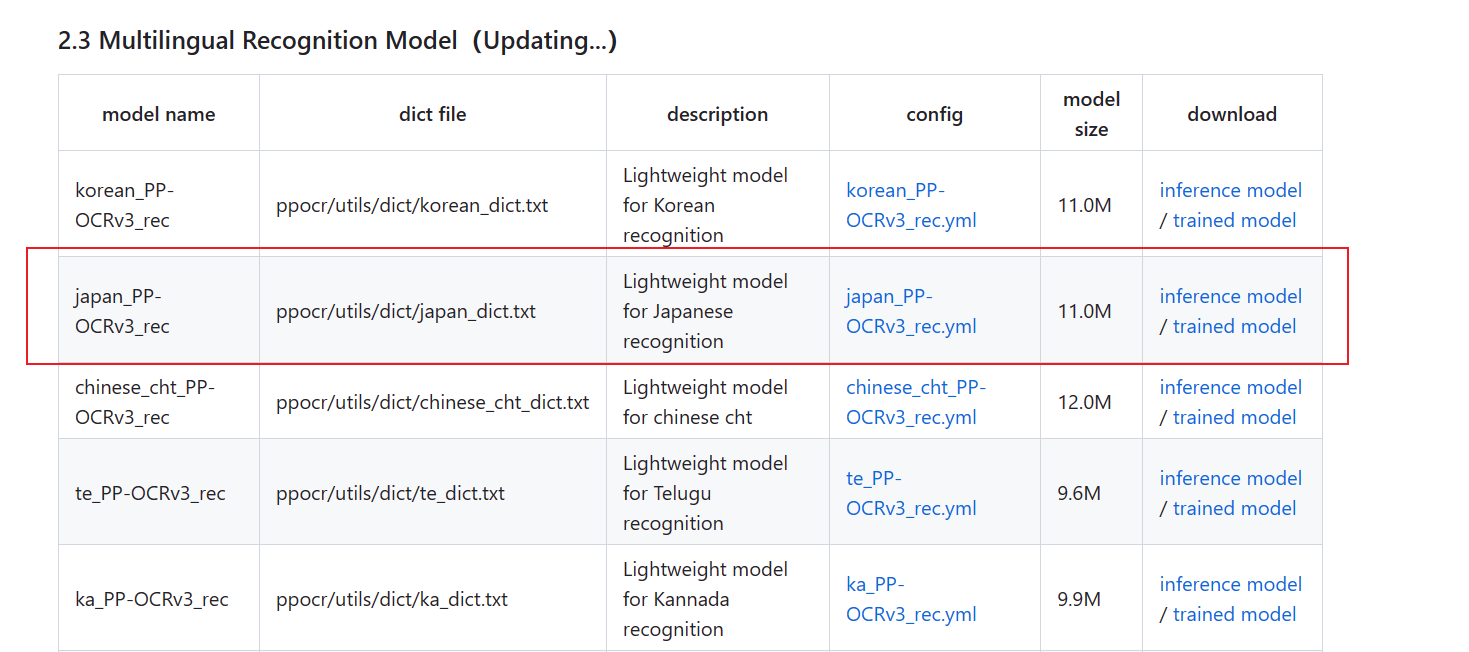
三个文件都下,然后上传到服务器上
再把数据集也上传到服务器上
最终项目结构如下:
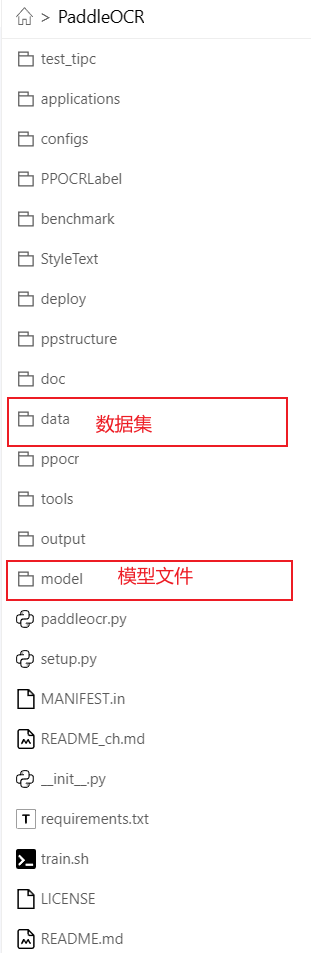
环境配置
pip install scikit-image
pip install imgaug
pip install pyclipper
pip install polygon3
pip install lanms-neo
pip install lmdb
pip install rapidfuzz
修改 japan_PP-OCRv3_rec.yml
Global:debug: falseuse_gpu: true # 服务器有gpu就true,没有就falseepoch_num: 50log_smooth_window: 20print_batch_step: 10save_model_dir: ./output/v3_japan_mobilesave_epoch_step: 3eval_batch_step: [0, 2000]cal_metric_during_train: truepretrained_model: model/japan_PP-OCRv3_rec_train/japan_PP-OCRv3_rec_train/best_accuracy.pdparamscheckpoints:save_inference_dir:use_visualdl: falseinfer_img: doc/imgs_words/ch/word_1.jpgcharacter_dict_path: ppocr/utils/dict/japan_dict.txtmax_text_length: &max_text_length 25infer_mode: falseuse_space_char: truedistributed: truesave_res_path: ./output/rec/predicts_ppocrv3_japan.txtOptimizer:name: Adambeta1: 0.9beta2: 0.999lr:name: Cosinelearning_rate: 0.001warmup_epoch: 5regularizer:name: L2factor: 3.0e-05Architecture:model_type: recalgorithm: SVTRTransform:Backbone:name: MobileNetV1Enhancescale: 0.5last_conv_stride: [1, 2]last_pool_type: avgHead:name: MultiHeadhead_list:- CTCHead:Neck:name: svtrdims: 64depth: 2hidden_dims: 120use_guide: TrueHead:fc_decay: 0.00001- SARHead:enc_dim: 512max_text_length: *max_text_lengthLoss:name: MultiLossloss_config_list:- CTCLoss:- SARLoss:PostProcess: name: CTCLabelDecodeMetric:name: RecMetricmain_indicator: accignore_space: FalseTrain:dataset:name: SimpleDataSetdata_dir: data/train_dataext_op_transform_idx: 1label_file_list:- data/train_label.txttransforms:- DecodeImage:img_mode: BGRchannel_first: false- RecConAug:prob: 0.5ext_data_num: 2image_shape: [48, 320, 3]- RecAug:- MultiLabelEncode:- RecResizeImg:image_shape: [3, 48, 320]- KeepKeys:keep_keys:- image- label_ctc- label_sar- length- valid_ratioloader:shuffle: truebatch_size_per_card: 16drop_last: truenum_workers: 4
Eval:dataset:name: SimpleDataSetdata_dir: data/test_datalabel_file_list:- data/test_label.txttransforms:- DecodeImage:img_mode: BGRchannel_first: false- MultiLabelEncode:- RecResizeImg:image_shape: [3, 48, 320]- KeepKeys:keep_keys:- image- label_ctc- label_sar- length- valid_ratioloader:shuffle: falsedrop_last: falsebatch_size_per_card: 16num_workers: 45、训练
python3 tools/train.py -c model/japan_PP-OCRv3_rec.yml
可能会报错,大概就是我们label.txt文件编码是gbk,而数据处理代码是utf-8,只需要将PaddleOCR/ppocr/data/simple_dataset.py这个代码中的98行和124行中的utf-8改为gbk即可
训练日志,数据集弄多了。。时间有点长

跑去本地训练了。。。本地环境也需要配置(需要配置cuda,cudnn,paddle等,paddle可以在https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/install/pip/windows-pip.html下载,cuda和cudnn就不细说了)
你还别说,3070就是快啊

6、测试
python3 tools/eval.py -c model/japan_PP-OCRv3_rec.yml

效果还是可以的
7、验证
python3 tools/infer_rec.py -c model/japan_PP-OCRv3_rec.yml -o Global.infer_img=data/test_data/霧積山_45.jpg
验证图片

结果:

8、总结
总之,我觉得没啥技术含量
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!