48秒+50行以内代码=爬取600+王者荣耀人物皮肤
萌新报到,先搞“农药”!
大佬们都先分析,初学者也分析一下“王者荣耀”角色皮肤的分析程序。
第一,先找到角色网站。百度>>>>王者荣耀>>>>标识“官网”字样>>>>点击,进入主站后点击游戏资料里的>>>>>>英雄资料。
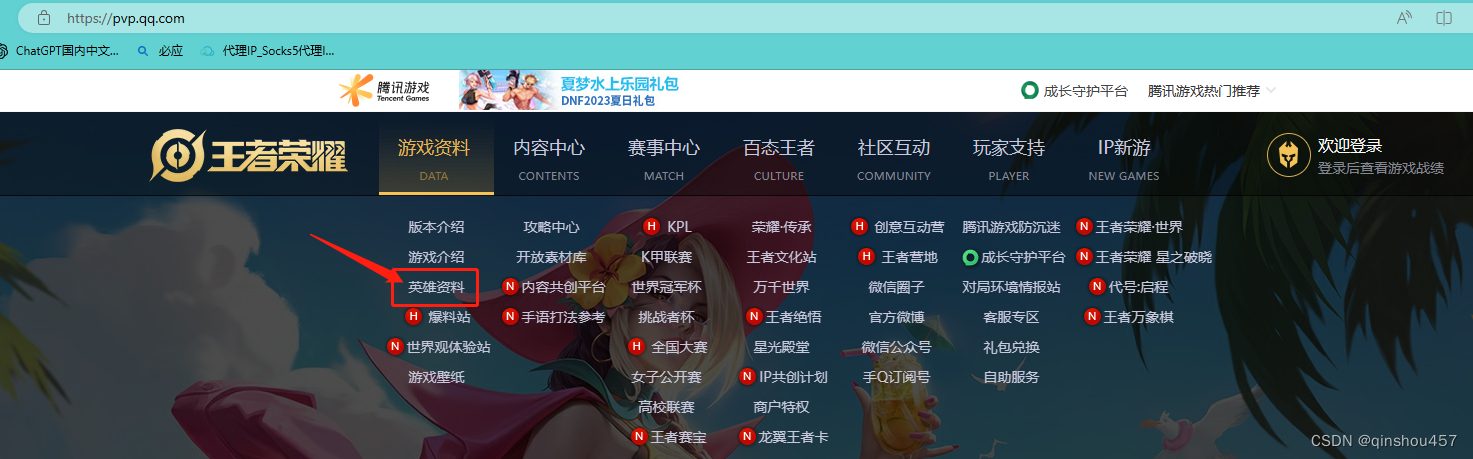
第二,找出这些角色放在哪个“盒子”里。按F12或者右键“检查”或者“审查元素”,点击上面的网络或者network,找一下‘herolist.json’的这个名称(名称已经起的这么明显了,但凡有点基础,也知道这个是英雄列表的意思),点击发现右侧有个预览,嗷嚎,这是个列表式的东西,点开大概看看,应该就是这么多英雄的信息了。点击标头,记下这个网址信息。
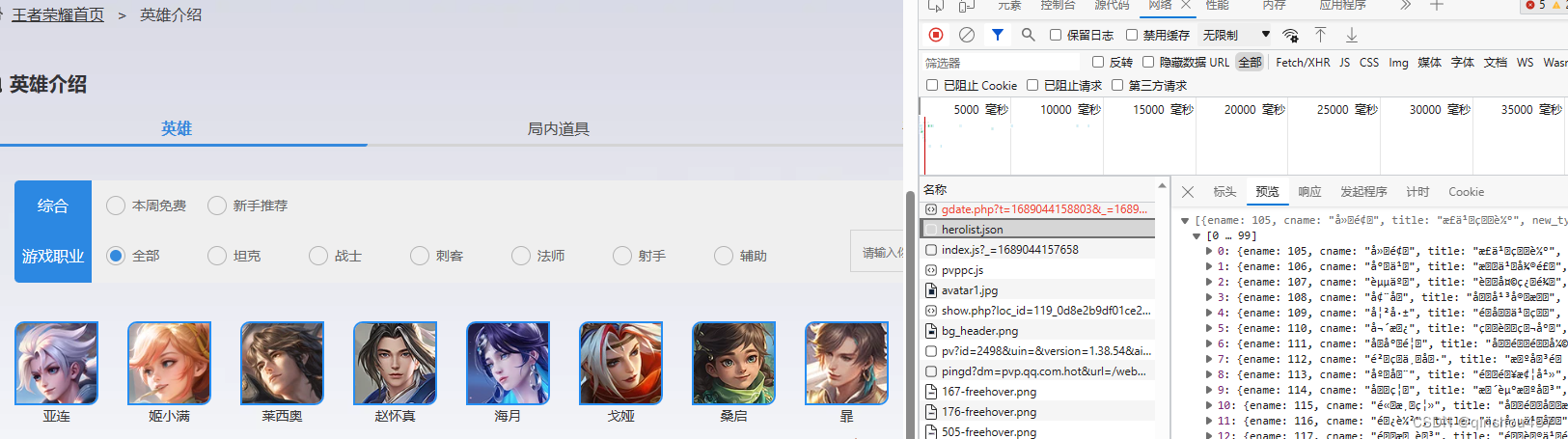

第三,确定角色皮肤网址。随意点开一个角色,在新的页面按F12或者检查或者审查元素,点击网络,第一个名称是一个数字后.shtml,记住这个数字,往下找,找到bigskin相关的jpg文件(别的不认识,big我还是知道是大的意思),一看预览,就是它了。点标头,记住它的网址。
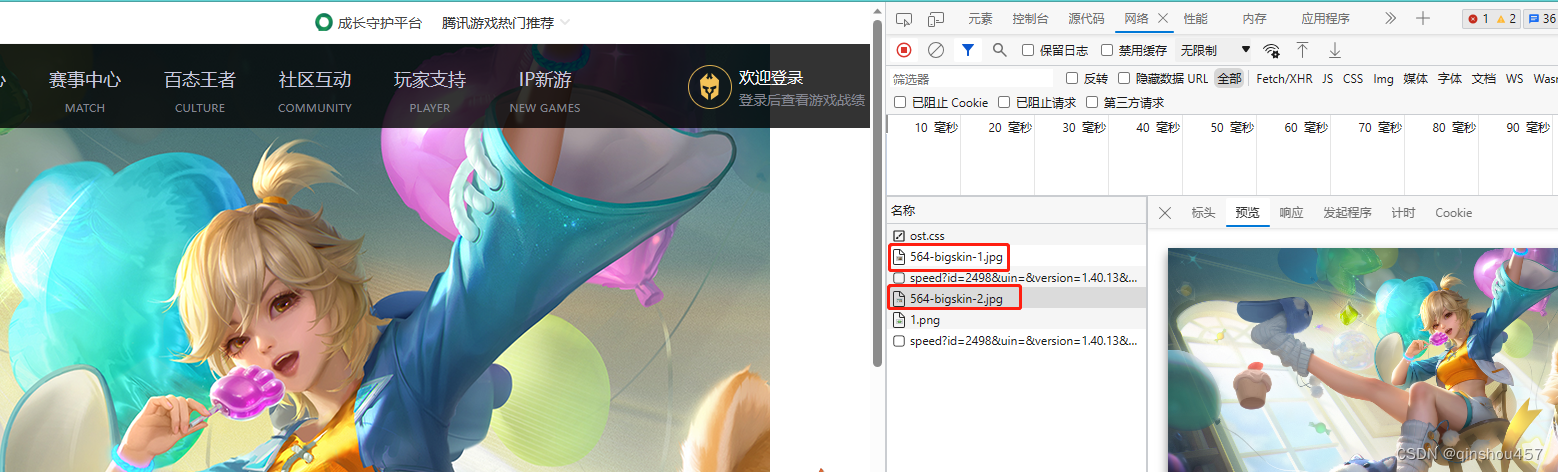

第四,分析一下网址。小编拿到了两个角色的网址,可恶的标签,可能看不太清,两个角色bigskin网址区别是下面两个位置。这里小编告诉你,刚才拿到的“herolist”的json数据里有一个ename,就对应的是下面第一个位置了,后面的数字,就是这个角色的皮肤编号了。

总结,我们拿到“herolist.json”中的ename,用来拼接网址,cname和title用来给爬下来的文件命名,就是这个程序,开搞!
代码部分
想48秒解决600多张皮肤图,小编采用异步的形式开爬,如果你的电脑还不错的话,应该用不了48秒才对。
首先,小编用的是Python3.10的环境,导入我们用到的库(导包):aiohttp、asyncio、time
aiohttp是第三方库,所以需要 终端,‘pip install aiohttp’一下
采用面向对象的方法写的代码
import time
import aiohttp
import asyncio# 备用网站
# https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/564/564-bigskin-1.jpg
# https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/521/521-bigskin-2.jpg
# https://pvp.qq.com/web201605/js/herolist.jsonclass Wangzhe():def __init__(self):self.url = 'https://pvp.qq.com/web201605/js/herolist.json'self.skin_url = 'https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{}/{}-bigskin-{}.jpg'self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'}async def gat_data(self, client, ename, cname, title):# 我不知道每个角色有多少皮肤,但是应该不会超过10个吧for i in range(1, 10):res = await client.get(self.skin_url.format(ename, ename, i), headers=self.headers)# 这里判断,如果请求的状态正常,就去拿数据if res.status == 200:content = await res.read()with open(f'./{cname}{title}{i}.jpg', mode='wb') as f:f.write(content)print(f'正在下载{cname}{title}的第{i}张图片')else:breakasync def run(self):# 将aiohttp的Client什么什么的方法赋值给client,以后都可以用client进行请求async with aiohttp.ClientSession() as client:res = await client.get(self.url, headers=self.headers)wz_data = await res.json(content_type=None)# print(wz_data)task_list = []for i in wz_data:ename = i['ename']cname = i['cname']title = i['title']# print(i)response = self.gat_data(client, ename, cname, title)task = asyncio.create_task(response)task_list.append(task)await asyncio.wait(task_list)if __name__ == '__main__':wangzhe = Wangzhe()t1 = time.time()loop = asyncio.new_event_loop()asyncio.set_event_loop(loop)loop.run_until_complete(wangzhe.run())print('总耗时:', str(time.time() - t1))
最终的结果,就是这个样子

总结一下
注意:本文只是以王者荣耀网站为例,作技术分享,并未查询到robots文件,如有侵权,请联系删除。
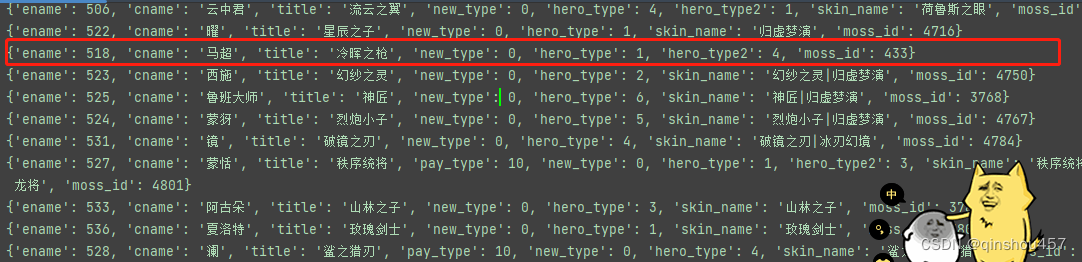
小编作为萌新,只是用了一种省力的方式得到了这些皮肤图片。其实本来是想在命名的时候加入skin_name这个标签里的内容的,但是由于json文件中,马超名下并没有这个标签,所以不得已,仅仅加入了title数据。
其实小编认为,使用re表达式能够更直接的将角色、皮肤名、皮肤描述加入到文件名中,甚至更方便的将每个角色分别放入不同的文件夹,但是那样分析起来也很麻烦,就偷了个懒,水了一篇文,哇嘎嘎。
谢谢大家的关注,以后有了实际案例还会发表出来的。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!