LinkedList源码分析
LinkedList几个重要方法的实现机制:首先,简单介绍一下linkedList的数据结构。ArrayList与linkedList的区别在于前者是用数组实现,而后者则是使用双向循环链表结构组成,这里我就不细讲啦,对数据结构不熟悉的小伙伴可以先去熟悉一下链表的组成和特性。
一、add(E e)方法的实现过程:
(1)第一步,进入linkLast(e)方法中,在这个方法中又会细分为几个步骤,先创建一个 Node
(2)第二步,把存储起来的尾节点数据、新添加的参数和一个null数据传入Node<>的构造方法中,构造成一个新的节点对象。并把生成的新节点数据赋值到链表尾节点的位置。(这部分比较绕,大家需要慢慢体会)
(3)第三步,对链表尾节点做非空验证,如果为空,则把新节点数据赋值到链表的头节点位置。若不为空,则把新节点数据赋值到原尾节点的直接后继指针(next),然后把链表的长度自加一。
(4)第四步,通过图解的来描述:
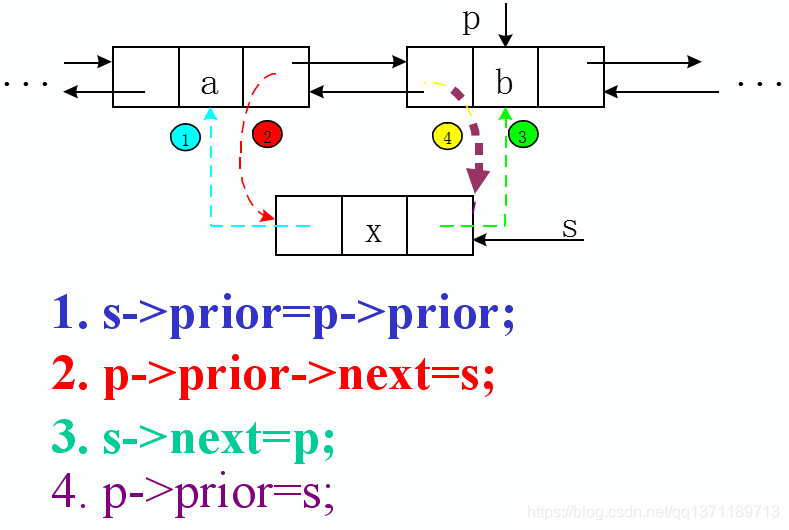
第一步:首先找到插入位置,节点 s 将插入到节点 p 之前
第二步:将节点 s 的前驱指向节点 p 的前驱,即 s->prior = p->prior;
第三步:将节点 p 的前驱的后继指向节点 s 即 p->prior->next = s;
第四步:将节点 s 的后继指向节点 p 即 s->next = p;
第五步:将节点 p 的前驱指向节点 s 即 p->prior = s;
二、remove(Object o)方法的实现过程:
(1)第一步,先判断传入参数是否为空,当参数不为空的情况进行一个循环遍历 for (Node
(2)第二步,当判断传入参数与链表的数据相同时进入unlink(x)方法(这个是用来分解链表的方法),在这个方法中首先把传入参数的数据部分、前驱节点和后继节点分别赋值给新的Node
(3)第三步,通过图示可能描述的很清晰一点:
插入元素位置的前一个数据节点
| prev | data | next |
a b c
插入的元素
| prev | data | next |
d e f
插入元素位置的后一个节点
| prev | data | next |
g h i
我把每个节点的数据用一个小写的英文字母代替,便于大家更好的理解。下面建议大家根据unlink(Node
(4)第四步,再进行分解时,还是会先判断传入参数的前驱节点和后继节点的值是否为空,当不为空的情况下,可分层这几个步骤:
1. c = h , d = null
2. g = b , f = null
3. e = null.
(5)第五步,数据分割以后,使集合的长度自减一,并返回参数节点的数据部分。
(6)链表删除元素图解:
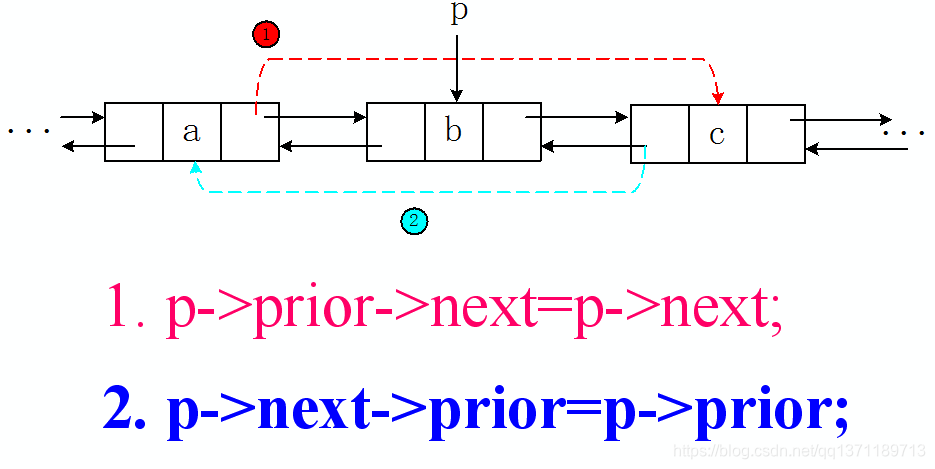
第一步:找到即将被删除的节点 p
第二步:将 p 的前驱的后继指向 p 的后继,即 p->prior->next = p->next;
第三步:将 p 的后继的前驱指向 p 的前驱,即 p->next->prior = p->prior;
第四步:删除节点 p 即 delete p;
三、set(int index, E element)方法的实现过程:
(1)第一步,首先通过checkElementIndex(index)方法来判断是否下标越界。
(2)第二步,通过node(index)方法来找到对应下标元素。进入node方法后,先判断传入下标索引参数值是靠近头节点还是靠近尾节点。如果靠近头节点,就从链表第一个节点开始循环遍历,一直到索引参数值的位置。找到位置后把此位置的尾节点赋值给链表头节点,并返回。如果靠近尾节点,就从链表最后一个节点开始遍历,一直索引到参数值的位置。找到位置后把此位置的头节点赋值给链表的尾节点,并返回。
(3)第三步,把查询到的节点赋值存储起来,并把传入参数值赋值到原来的数据域位置,并返回原数据值。
四、get(int index)方法的是实现过程:
(1)第一步,首先通过checkElementIndex(index)方法来判断是否下标越界。
(2)第二步,通过上文提到的node(index)返回对应的数据节点,并返回节点的数据域部分。
以上文章,来自于我个人对源码的理解,在一些知识点上可能有些不足,读者若有些好的建议与想法可以及时指出。谢谢大家!
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!