解密Flink的状态管理:探索流处理框架的数据保留之道,释放流处理的无限潜能!
水善利万物而不争,处众人之所恶,故几于道💦
文章目录
- 一、什么是状态
- 二、应用场景
- 三、Flink中状态的分类
- 四、算子状态
- 1. 列表状态(List State)
- 2. 广播状态(Broadcast State)
- 五、键控状态
- 1. ValueState
- 2. ListState
- 3. ReducingState
- 4. AggregatingState
- 1)类实现累加器 - 示例代码
- 2)元组实现累加器 - 示例代码
- 5. MapState
一、什么是状态
在流式计算中,有些计算的中间结果需要进行保存,为下一个计算提供参考,比如,有一个数据流,我需要实时的计算这个流中的总消费金额,那么就需要一个变量来存储截止目前的总消费金额,当下一条数据来的时候我就直接在以前总消费金额的基础上,加上这条数据的消费金额就可以了。那么这个例子中的那个存储总消费金额的变量(或者说是累加变量)就叫状态。
二、应用场景
在流式处理中,状态的应用场景非常广泛。
去重
如果我们需要对数据流中的数据进行去重统计时,我们可以利用状态管理。通过状态来记录数据是否流过应用,当新数据流入时,根据状态来判断去重。
检测
检测输入流中的数据是否符合某个特定的模式。这里的模式不是指数据的格式,而是指数据之间的关系是否符合某个需求模型。比如,根据一个网站访问记录流中的数据,判断用户是否连续登录,然后给予相应的奖励。
聚合
对某个特定时间内的数据进行聚合统计分析。比如统计每小时的 PV 量。
三、Flink中状态的分类
Flink中包括两种基本的状态Managed State和Raw State,分别是管理状态和原始状态
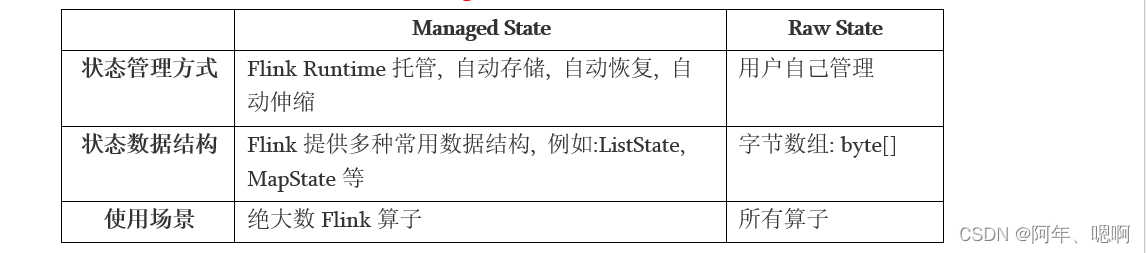
原始状态基本用不到,因为官方提供的管理状态已经够我们使用了
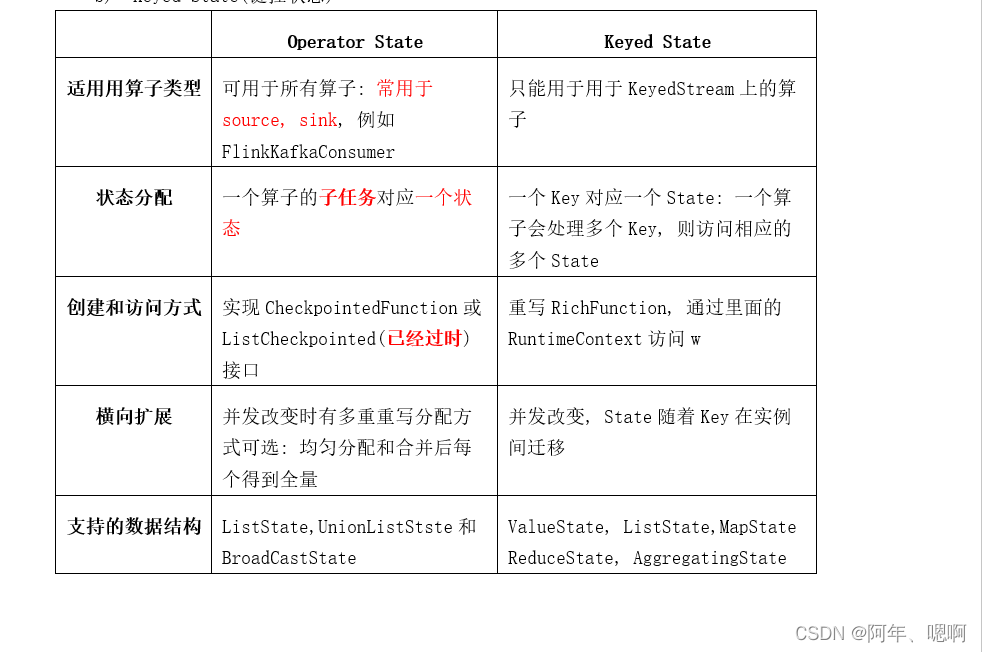
管理状态又分为两类,分别是算子状态(Operator State)和键控状态(Keyed State)
-
算子状态可用于所有的算子,但是常用于source算子和sink算子;他是一个算子的子任务对应一个状态,也就是一个并行度里面一个状态;它通过实现CheckpointedFunction接口创建;它支持的数据结构有ListState,UnionListStste 和 BroadCastState。
-
键控状态只能用于KeyedStream上的算子;这个是一个key对应一个状态,他只和key有关;创建的时候重写RichFunction,通过里面的getRuntimeContext().get…State()获取状态对象;键控状态支持的数据结构有 ValueState,ListState,MapState,ReduceState,AggregatingState
四、算子状态
1. 列表状态(List State)
将状态表示为一组数据的列表。向状态中添加元素add()、更新状态中的所有元素update(),取出状态中的所有元素get(),它会返回一个迭代器。
例:将输入的单词存入到状态中,当程序重启的时候,可以把状态中存的单词恢复。
示例代码:
public class Flink01_State_Operator_List {public static void main(String[] args) {Configuration conf = new Configuration();conf.setInteger("rest.port",1000);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(2);// 启用checkpoint 周期是2000毫秒,也就是2秒,每隔2s将状态保存一下env.enableCheckpointing(2000);env.socketTextStream("hadoop101",9999).map(new MyMapFunction()).print();try {env.execute();} catch (Exception e) {e.printStackTrace();}}// 算子状态,不能用内部类了,因为要实现两个接口,算子状态要实现CheckpointedFunction接口private static class MyMapFunction implements MapFunction<String,String>, CheckpointedFunction {List<String> words = new ArrayList();private ListState<String> wordsState;@Overridepublic String map(String line) throws Exception {//抛个异常他就会自动重启,输入x就让他抛异常if (line.contains("x")) {throw new RuntimeException("手动抛出异常..."); }String[] data = line.split(" ");words.addAll(Arrays.asList(data));return words.toString();}// 保存状态:周期性的执行// 每个并行度都会周期性的执行@Overridepublic void snapshotState(FunctionSnapshotContext context) throws Exception {// 这个方法是把数据存入到算子状态(状态列表)
// System.out.println("MyMapFunction.snapshotState");// wordsState.clear(); 清空状态
// wordsState.addAll(words); 向状态中写数据// 上面两个方法能用下面这一个方法代替wordsState.update(words);}// 程序启动的时候每个并行度执行一次// 这个方法可以把状态中的数据恢复到Java的集合中@Overridepublic void initializeState(FunctionInitializationContext context) throws Exception {// 从状态中恢复数据//System.out.println("MyMapFunction.initializeState");System.out.println("程序重启,从状态中恢复数据...");// 获取列表状态wordsState = context.getOperatorStateStore().getListState(new ListStateDescriptor<String>("wordsState", String.class));// 从列表中获取数据// 将状态中的数据遍历出来,在添加到集合中,也就是恢复数据
// Iterable it = wordsState.get(); for (String word : wordsState.get()) {words.add(word);}}}
}
输入数据:

运行结果:

2. 广播状态(Broadcast State)
广播状态一般是两个流用,一个数据流,一个广播流,用广播流中的数据控制数据流中数据的处理逻辑。向状态里面写数据用put(),从状态里面拿数据用get()
例:通过广播流输入1,2,3…控制数据流中的数据使用不同的处理逻辑
示例代码:
public class Flink03_State_Operator_BroadCast {public static void main(String[] args) {Configuration conf = new Configuration();conf.setInteger("rest.port",1000);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(2);//获取一个数据流DataStreamSource<String> dataStream = env.socketTextStream("hadoop101", 8888);// 获取一个配置流DataStreamSource<String> configStream = env.socketTextStream("hadoop101", 9999);// 1. 把配置流做成一个广播流 需要一个map状态描述器 一个key的类型,一个valueMapStateDescriptor<String, String> bcStateDesc = new MapStateDescriptor<>("bcState", String.class, String.class);BroadcastStream<String> bcStream = configStream.broadcast(bcStateDesc);// 2. 让数据流去connect广播流BroadcastConnectedStream<String, String> coStream = dataStream.connect(bcStream);// 泛型分别表示,数据流类型,广播流类型,输出类型coStream.process(new BroadcastProcessFunction<String, String, String>() {// 4. 处理数据流中的数据:从广播状态中取配置@Overridepublic void processElement(String value,ReadOnlyContext ctx,Collector<String> out) throws Exception {System.out.println("Flink03_State_Operator_BroadCast.processElement");ReadOnlyBroadcastState<String, String> broadcastState = ctx.getBroadcastState(bcStateDesc);String conf = broadcastState.get("aSwitch");if("1".equals(conf)){out.collect(value +" 使用 1 号逻辑...");}else if ("2".equals(conf)){out.collect(value +" 使用 2 号逻辑...");}else if ("3".equals(conf)){out.collect(value +" 使用 3 号逻辑...");}else {out.collect(value +" 使用 default 号逻辑...");}}// 3. 把广播流中的数据放入到广播状态@Overridepublic void processBroadcastElement(String value, // 广播流中的数据Context ctx, // 上下文Collector<String> out) throws Exception {System.out.println("Flink03_State_Operator_BroadCast.processBroadcastElement");// 获取广播状态,把配置信息写入到状态中BroadcastState<String, String> broadcastState = ctx.getBroadcastState(bcStateDesc);broadcastState.put("aSwitch",value);}}).print();try {env.execute();} catch (Exception e) {e.printStackTrace();}}
}
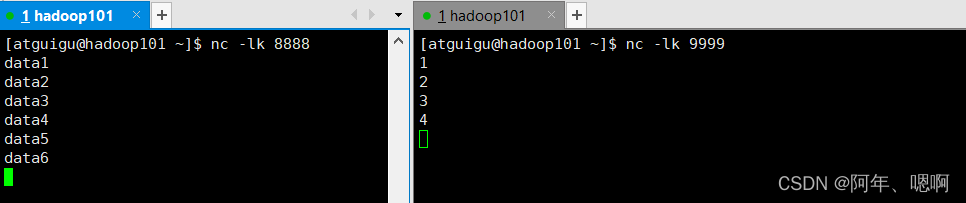
输入数据:
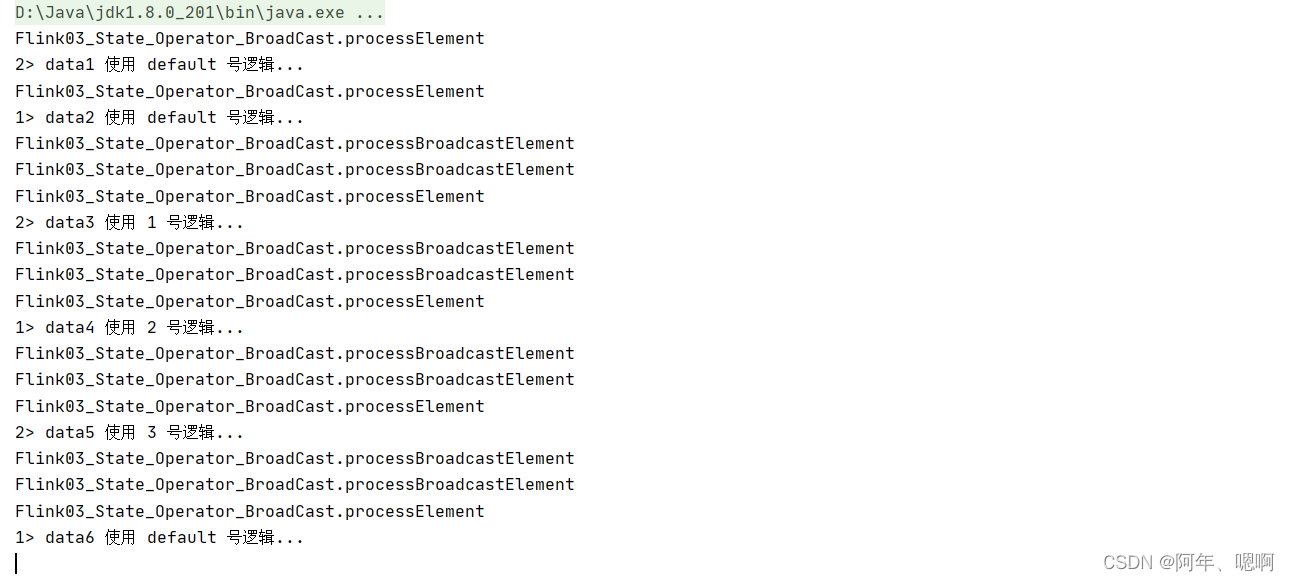
运行结果:
五、键控状态
1. ValueState
保存单个值. 每个key有一个状态值. 向状态中保存数据使用 update(T)方法, 获取状态中的数据使用value()方法。
例:检测传感器的水位值,如果连续的两个水位值超过10,就输出报警。
示例代码:
public class Flink04_State_Key_Value {public static void main(String[] args) {Configuration conf = new Configuration();conf.setInteger("rest.port",1000);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(2);env.socketTextStream("hadoop101", 9999) // socket只能是1.map(line -> {String[] data = line.split(",");return new WaterSensor(data[0],Long.valueOf(data[1]),Integer.valueOf(data[2]));}).keyBy(WaterSensor::getId)// 键控状态必须在keyBy后使用.process(new KeyedProcessFunction<String, WaterSensor, String>() {// 状态private ValueState<Integer> lastVcState;// 每个并行度执行一次 初始化的时候执行一次@Overridepublic void open(Configuration parameters) throws Exception {
// System.out.println("Flink04_State_Key_Value.open");// 因为他已经把状态封装在运行时上下文了,所以直接获取就行了lastVcState = getRuntimeContext().getState(new ValueStateDescriptor<Integer>("lastVcState", Integer.class));}@Overridepublic void processElement(WaterSensor value,Context ctx,Collector<String> out) throws Exception {// 获取状态里面的值 通过 .value() 方法Integer lastVc = lastVcState.value();System.out.println(lastVc+ "" +" " + value.getVc());if (lastVc != null) {if (value.getVc() >10 && lastVc > 10) {out.collect(ctx.getCurrentKey()+" 连续两次超过10,发出红色预警...");}}// 更新状态的值 只能保存一个值,所以用update更新lastVcState.update(value.getVc());}}).print();try {env.execute();} catch (Exception e) {e.printStackTrace();}}
}
输入数据:
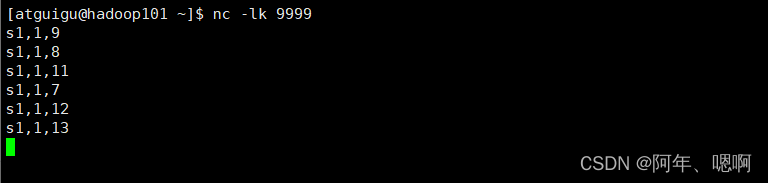
运行结果:

2. ListState
保存元素列表。添加一个元素用add(T),添加多个元素用addAll(List,获取元素用get()他会返回一个迭代器,可遍历出每个元素,覆盖所有元素用update(List
例:针对每个传感器输出最高的3个水位值
示例代码:
public class Flink05_State_Key_List {public static void main(String[] args) {Configuration conf = new Configuration();conf.setInteger("rest.port",1000);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(2);env.socketTextStream("hadoop101", 9999) // socket只能是1.map(line -> {String[] data = line.split(",");return new WaterSensor(data[0],Long.valueOf(data[1]),Integer.valueOf(data[2]));}).keyBy(WaterSensor::getId)// 键控状态必须在keyBy后使用.process(new KeyedProcessFunction<String, WaterSensor, String>() {private ListState<Integer> top3VcState;@Overridepublic void open(Configuration parameters) throws Exception {top3VcState = getRuntimeContext().getListState(new ListStateDescriptor<Integer>("top3VcState", Integer.class));}@Overridepublic void processElement(WaterSensor value,Context ctx,Collector<String> out) throws Exception {// 因为用的是list状态,可以存多个值,所以每来一个数据要先存进状态top3VcState.add(value.getVc());// 获取状态里面的元素Iterable<Integer> iterable = top3VcState.get();List<Integer> list = AnqclnUtil.toList(iterable);list.sort(new Comparator<Integer>() {@Overridepublic int compare(Integer o1, Integer o2) {return o2.compareTo(o1);}});// 因为要取的是前三,所以第四个元素进来的时候就不要了if (list.size() ==4){list.remove(list.size()-1);}top3VcState.update(list);out.collect(ctx.getCurrentKey()+" 最高的三个水位值:"+list);}}).print();try {env.execute();} catch (Exception e) {e.printStackTrace();}}
}
输入数据:

运行结果:

3. ReducingState
存储单个值,表示把所有元素的聚合结果添加到状态中,当向状态中添加元素的时候,他会使用指定的ReduceFunction进行聚合。添加元素是add(T),取出元素是get()
例:计算每个传感器的水位和
示例代码:
public class Flink06_State_Key_Reduce {public static void main(String[] args) {Configuration conf = new Configuration();conf.setInteger("rest.port", 1000);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(2);env.socketTextStream("hadoop101", 9999) // socket只能是1.map(line -> {String[] data = line.split(",");return new WaterSensor(data[0],Long.valueOf(data[1]),Integer.valueOf(data[2]));}).keyBy(WaterSensor::getId)// 键控状态必须在keyBy后使用.process(new KeyedProcessFunction<String, WaterSensor, String>() {private ReducingState<WaterSensor> vcSumState;@Overridepublic void open(Configuration parameters) throws Exception {vcSumState = getRuntimeContext().getReducingState(new ReducingStateDescriptor<WaterSensor>("vcSumState",new ReduceFunction<WaterSensor>() {@Overridepublic WaterSensor reduce(WaterSensor value1,WaterSensor value2) throws Exception {value1.setVc(value1.getVc() + value2.getVc());return value1;}},WaterSensor.class));}@Overridepublic void processElement(WaterSensor value,Context ctx,Collector<String> out) throws Exception {// 将传过来的每个元素加入到状态里面去,然后就行了,他会自己聚合,因为在上面创建状态的时候就已经写了聚合的逻辑vcSumState.add(value);out.collect(ctx.getCurrentKey()+" 的水位和为:"+vcSumState.get().getVc());}}).print();try {env.execute();} catch (Exception e) {e.printStackTrace();}}
}
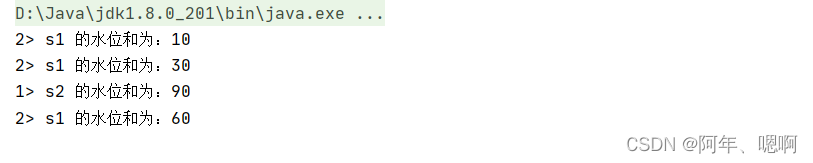
输入数据:

运行结果:
4. AggregatingState
存储单个值。 与ReducingState类似, 都是进行聚合。 不同的是,AggregatingState的聚合的结果和输入的元素类型可以不一样。存数据用add(),取数据用get()
例:计算每个传感器的平均水位
1)类实现累加器 - 示例代码
public class Flink07_State_Key_Aggregate {public static void main(String[] args) {Configuration conf = new Configuration();conf.setInteger("rest.port", 1000);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(2);env.socketTextStream("hadoop101", 9999) // socket只能是1.map(line -> {String[] data = line.split(",");return new WaterSensor(data[0],Long.valueOf(data[1]),Integer.valueOf(data[2]));}).keyBy(WaterSensor::getId)// 键控状态必须在keyBy后使用.process(new KeyedProcessFunction<String, WaterSensor, String>() {private AggregatingState<WaterSensor, Double> avgVcState;@Overridepublic void open(Configuration parameters) throws Exception {avgVcState = getRuntimeContext().getAggregatingState(new AggregatingStateDescriptor<WaterSensor, Avg, Double>("avgVcState",new AggregateFunction<WaterSensor, Avg, Double>() {@Overridepublic Avg createAccumulator() {return new Avg();}@Overridepublic Avg add(WaterSensor value, Avg acc) {acc.sum += value.getVc();acc.count++;return acc;}@Overridepublic Double getResult(Avg acc) {return acc.avg();}@Overridepublic Avg merge(Avg a, Avg b) {return null;}},Avg.class));}@Overridepublic void processElement(WaterSensor value,Context ctx,Collector<String> out) throws Exception {avgVcState.add(value);out.collect(ctx.getCurrentKey()+" 的平均水位:"+avgVcState.get());}}).print();try {env.execute();} catch (Exception e) {e.printStackTrace();}}private static class Avg {public Integer sum = 0;public Long count = 0L;public Double avg(){return sum *1.0 / count;}}
}
输入数据:

运行结果:

2)元组实现累加器 - 示例代码
public class Flink08_State_Key_Aggregate_Tuple2 {public static void main(String[] args) {Configuration conf = new Configuration();conf.setInteger("rest.port", 1000);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(2);env.socketTextStream("hadoop101", 9999) // socket只能是1.map(line -> {String[] data = line.split(",");return new WaterSensor(data[0],Long.valueOf(data[1]),Integer.valueOf(data[2]));}).keyBy(WaterSensor::getId)// 键控状态必须在keyBy后使用.process(new KeyedProcessFunction<String, WaterSensor, String>() {private AggregatingState<WaterSensor, Double> avgVcState;@Overridepublic void open(Configuration parameters) throws Exception {avgVcState = getRuntimeContext().getAggregatingState(new AggregatingStateDescriptor<WaterSensor, Tuple2<Integer, Long>, Double>("avgVcState",new AggregateFunction<WaterSensor, Tuple2<Integer, Long>, Double>() {@Overridepublic Tuple2<Integer, Long> createAccumulator() {return new Tuple2<Integer, Long>(0,0L);}@Overridepublic Tuple2<Integer, Long> add(WaterSensor value, Tuple2<Integer, Long> acc) {acc.f0 += value.getVc();acc.f1++;return acc;}@Overridepublic Double getResult(Tuple2<Integer, Long> acc) {return acc.f0 * 1.0 / acc.f1;}@Overridepublic Tuple2<Integer, Long> merge(Tuple2<Integer, Long> a, Tuple2<Integer, Long> b) {return null;}},
// TypeInformation.of(new TypeHint>() {}) // 类型还可以这样声明,简单Types.TUPLE(Types.INT,Types.LONG)));}@Overridepublic void processElement(WaterSensor value,Context ctx,Collector<String> out) throws Exception {avgVcState.add(value);out.collect(ctx.getCurrentKey()+" 的平均水位:"+avgVcState.get());}}).print();try {env.execute();} catch (Exception e) {e.printStackTrace();}}
}
输入数据:
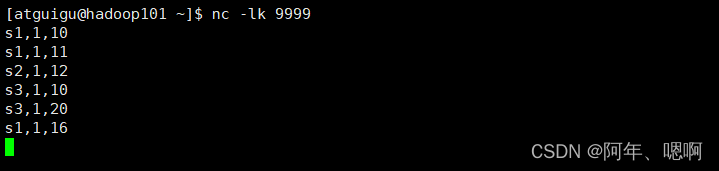
运行结果:

5. MapState
存储键值对列表。
添加键值对: put(UK, UV) 、 putAll(Map
根据key获取值: get(UK)
获取所有: entries()、keys() 、 values()
检测是否为空: isEmpty()
例:去重: 去掉重复的水位值. 思路: 把水位值作为MapState的key来实现去重, value随意
示例代码:
public class Flink09_State_Key_Map {public static void main(String[] args) {Configuration conf = new Configuration();conf.setInteger("rest.port", 1000);StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf);env.setParallelism(2);env.socketTextStream("hadoop101", 9999) // socket只能是1.map(line -> {String[] data = line.split(",");return new WaterSensor(data[0],Long.valueOf(data[1]),Integer.valueOf(data[2]));}).keyBy(WaterSensor::getId)// 键控状态必须在keyBy后使用.process(new KeyedProcessFunction<String, WaterSensor, String>() {private MapState<Integer, Object> vcMapState;@Overridepublic void open(Configuration parameters) throws Exception {vcMapState = getRuntimeContext().getMapState(new MapStateDescriptor<Integer, Object>("vcMapState",TypeInformation.of(new TypeHint<Integer>() {}),TypeInformation.of(new TypeHint<Object>() {})));}@Overridepublic void processElement(WaterSensor value,Context ctx,Collector<String> out) throws Exception {vcMapState.put(value.getVc(),new Object());Iterable<Integer> keys = vcMapState.keys();out.collect(ctx.getCurrentKey() + " 的所有不同水位: " + AnqclnUtil.toList(keys));}}).print();try {env.execute();} catch (Exception e) {e.printStackTrace();}}
}
输入数据:

运行结果:

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!