量化交易 实战第十二课 回归法选股 part 2
量化交易 实战第十二课 回归法选股 part 2
- 概述
- 代码
- 效果
概述
继上一片的理论, 我们这次来进行一下回测, 看一下结果如何.

代码
# 可以自己import我们平台支持的第三方python模块,比如pandas、numpy等。
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
# 在这个方法中编写任何的初始化逻辑。context对象将会在你的算法策略的任何方法之间做传递。
def init(context):# 初始化股票因子权重context.weights = np.array([0.04549957, 0.01249463, -0.02397849, 0.06077185, -0.00195205, -0.00892116, -0.04641399, -0.05644752, -0.08393869]) # 定义股票池数量context.stocknum = 20# 定时每月运行函数scheduler.run_monthly(regression_select, tradingday=1)def regression_select(context, bar_dict):"""回归预测选股逻辑"""# 获取沪深300context.hs300 = index_components("000300.XSHG")# 1. 查询因子q = query(fundamentals.eod_derivative_indicator.pe_ratio,fundamentals.eod_derivative_indicator.pb_ratio,fundamentals.eod_derivative_indicator.market_cap,fundamentals.financial_indicator.ev,fundamentals.financial_indicator.return_on_asset_net_profit,fundamentals.financial_indicator.du_return_on_equity,fundamentals.financial_indicator.earnings_per_share,fundamentals.income_statement.revenue,fundamentals.income_statement.total_expense).filter(fundamentals.stockcode.in_(context.hs300))fund = get_fundamentals(q)context.factors_data = fund.T# 2. 数据预处理process_data(context)# 3. 根据每月预测下月的收益率select_stocklist(context)# 4. 调仓reblance(context)def process_data(context):"""删除空值, 去极值, 标准化, 因子的市值中性化"""# 删除空值context.factors_data = context.factors_data.dropna()# 市值因子不进行去极值, 标准化处理market_cap_factor = context.factors_data["market_cap"]# 去极值化, U型你换对每个因子进行处理for name in context.factors_data.columns:context.factors_data[name] = mad(context.factors_data[name])context.factors_data[name] = stand(context.factors_data[name])# 对因子(除了市值因子) 中性化处理if name == "market_cap":continue# 建立回归方程, 市值中性化lr = LinearRegression()x = market_cap_factor.valuesy = context.factors_data[name]# x: 要求二维, y: 要求一维lr.fit(x.reshape(-1, 1), y)y_predict = lr.predict(x.reshape(-1, 1))# 得出误差进行替换原有因子值context.factors_data[name] = y - y_predictdef select_stocklist(context):"""回归计算预测得出收益率结果, 筛选收益率高的股票"""# 特征值是: context.factors_Date (300, 9) 系数: 因子权重# 进行矩阵运算 (300, 9) * (9, 1) = (300, 1)stock_return = np.dot(context.factors_data.values, context.weights)logger.info(stock_return)# 赋值给因子数据, 注意都是默认对应的股票代码和收益率context.factors_data["stock_return"] = stock_return# 进行收益率排序ordered = context.factors_data.sort_values(by="stock_return", ascending=False)# 加入股票池context.stock_list = ordered.index[:context.stocknum]def reblance(context):# ----------------卖出----------------# 遍历股票池for stock in context.portfolio.positions.keys():# 判断是否还在股票池if stock not in context.stock_list:# 如果不在, 卖出order_target_percent(stock, 0)# ----------------买入-----------------# 买入的百分比weight = 1.0 / len(context.stock_list)# 遍历股票池for stock in context.stock_list:# 等比例买入order_target_percent(stock, weight)# before_trading此函数会在每天策略交易开始前被调用,当天只会被调用一次
def before_trading(context):pass# 你选择的证券的数据更新将会触发此段逻辑,例如日或分钟历史数据切片或者是实时数据切片更新
def handle_bar(context, bar_dict):# 开始编写你的主要的算法逻辑pass# after_trading函数会在每天交易结束后被调用,当天只会被调用一次
def after_trading(context):passdef mad(factor):"""3倍中位数去极值"""# 求出因子值的中位数median = np.median(factor)# 求出因子值与中位数的差值, 进行绝对值mad = np.median(abs(factor - median))# 定义几倍的中位数上下限high = median + (3 * 1.4826 * mad)low = median - (3 * 1.4826 * mad)# 替换上下限factor = np.where(factor > high, high, factor)factor = np.where(factor < low, low, factor)return factordef stand(factor):"""数据标准化"""mean = factor.mean()std = factor.std()return (factor - mean) / std
效果
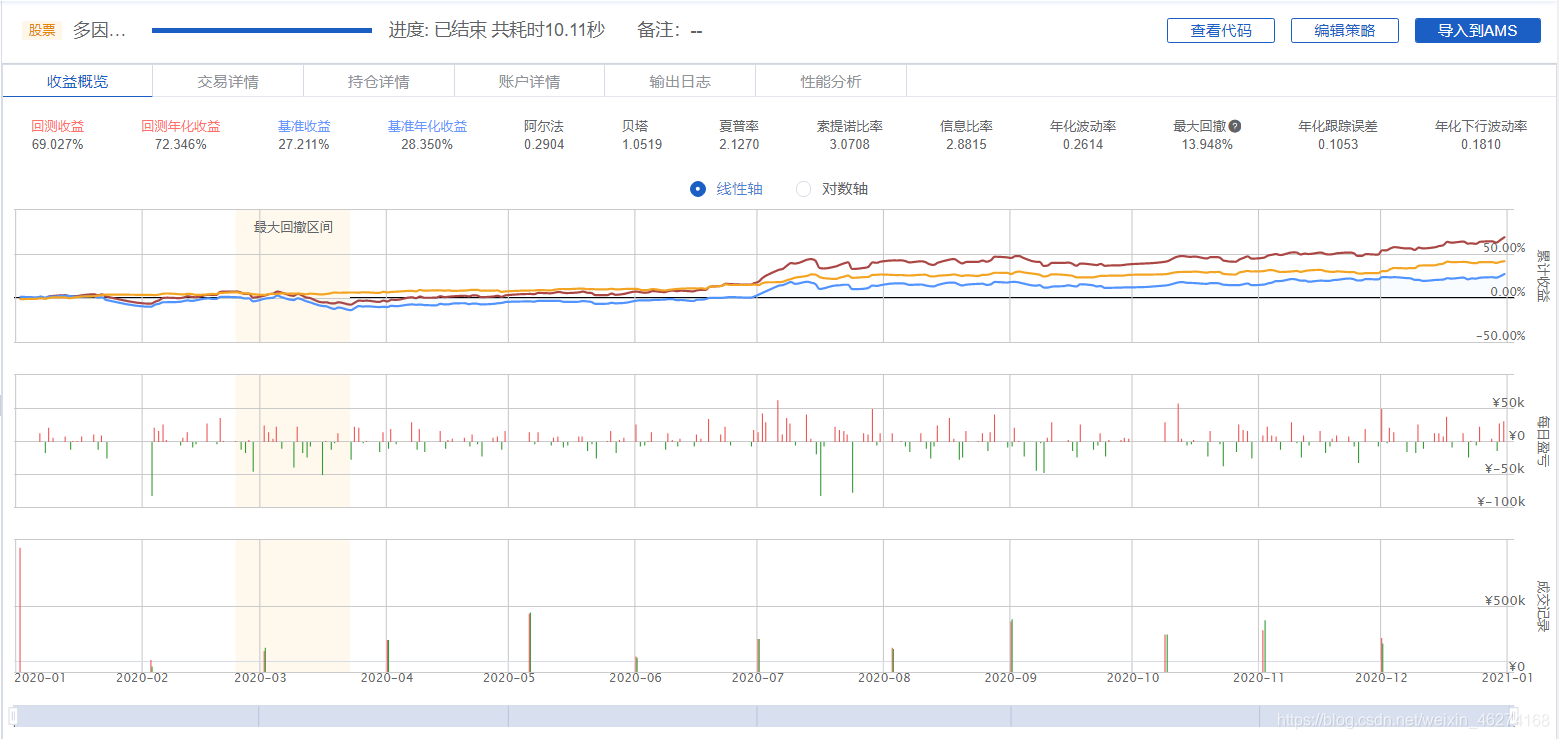
注: 在实际的应用中大概率不会跑赢大盘 46%, 因为分析的区间较短.
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!