python爬虫之 requests实战之网页采集器
今天继续我们的爬虫学习,学习一个requests实战之网页采集器:以搜狗首页为例
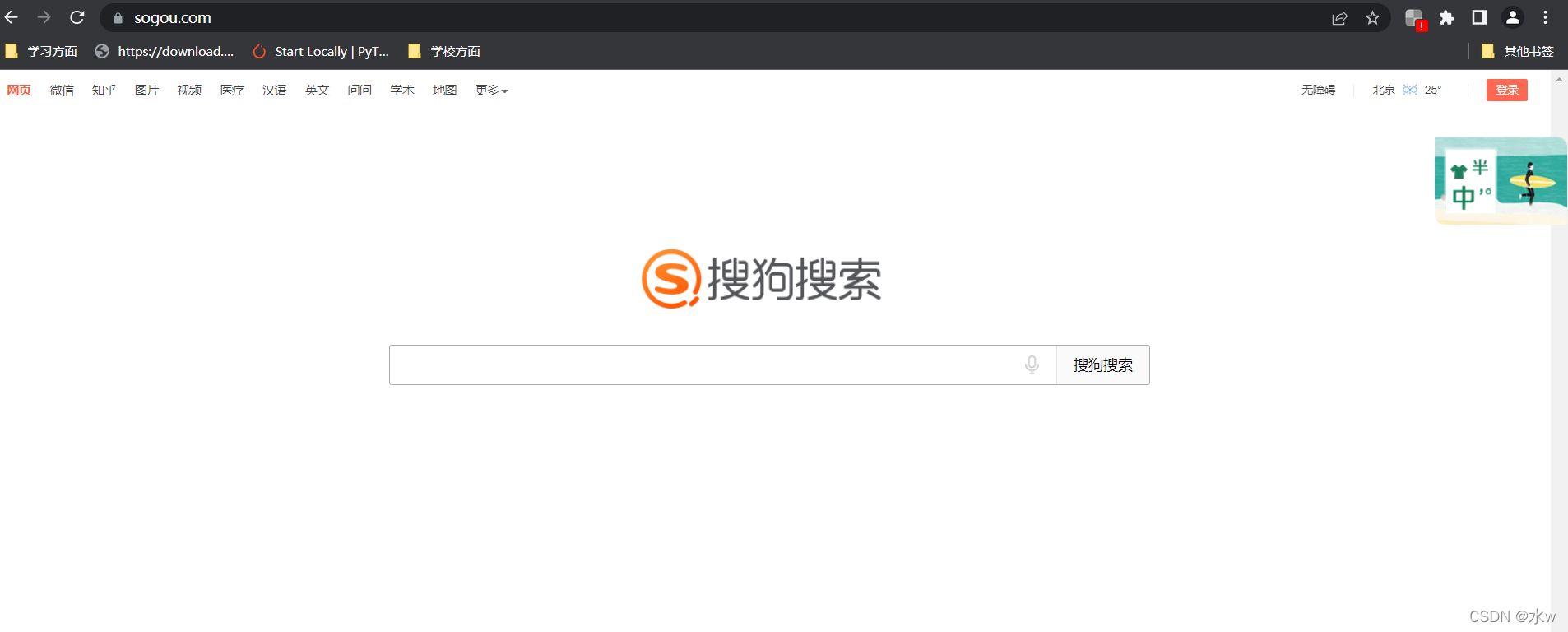
代码的设计步骤:
我们就按照这个设计流程进行开发网页采集器:
(1)UA伪装:将对应的User-Agent封装到一个字典内
这里,补充一点小知识:
UA:User-Agent(请求载体的身份标识)
UA检测:门户网站的服务器会检测对应请求载体的身份标识,如果是浏览器则说明是一个正常请求,否则很有可能拒绝该请求
UA伪装:让爬虫对应的请求载体身份标识伪装成某一个浏览器
(2)发起请求,get方式会返回一个响应对象
(3)获取响应数据,text返回的是字符串形式的响应数据
(4)持久化存储数据
下面,附上我的代码部分:
import requests
'''
网页采集器UA:User-Agent(请求载体的身份标识)
UA检测:门户网站的服务器会检测对应请求载体的身份标识,如果是浏览器则说明是一个正常请求,否则很有可能拒绝该请求
UA伪装:让爬虫对应的请求载体身份标识伪装成某一个浏览器
'''
if __name__ == "__main__":#UA伪装:将对应的User-Agent封装到一个字典内headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}url = 'https://www.sogou.com/web'# 2.发起请求,get方式会返回一个响应对象#处理url携带的参数:封装到字典内kw = input('enter a word:')param = {'query':kw}#对指定的url发起的请求对应的url是携带参数的,并且请求过程中处理了参数response = requests.get(url=url,params=param,headers=headers)# 3.获取响应数据,text返回的是字符串形式的响应数据page_text = response.textfileName = kw+'.html'# 4.持久化存储with open(fileName, 'w', encoding='utf-8') as fp:fp.write(page_text)print(fileName,"保存成功!!!")运行python代码,我输入了“huazhuangpin”,那么就生成了huazhuangpin.html文件
huazhuangpin.html文件详细代码为:
化妆品生产许可信息管理系统服务平台
【全部许可证】【业务办理】许可证编号企业名称社会信用代码所属省份生产类别- 发证日期
企业名称
许可证编号
发证机关
有效期至
本站由国家药品监督管理局主办版权所有 未经许可禁止转载或建立镜像 Copyright © NMPA All Rights Reserved
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!