百度网盘AI大赛—版式分析场景第9名方案
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
一、代码结构
- main.ipynb
- work: 代码与数据集目录
- datasets: 数据集存放
- LanelClas: 多标签分类
- configs 模型配置
- pretrained 预训练权重
- training_log_base 模型训练日志
- utils 模型所需要的一些设置
- dataset.py
- loss.py
- model.py
- PPHGNet.py
- PPHGNetV2.py
- PPLCNetV2.py
- transform.py
- train_base.py 训练脚本
- PaddleDetection: 检测套件
- configs 模型配置
- tools 训练、评估与预测脚本
- predict: 预测与提交
- models 多标签分类模型
- output 预测输出结果
- output_visualize 检测预测可视化
- ppyoloe_plus_crn_x_80e_coco 所选导出模型权重
- predict.py 预测提交
- visualize.py 检测可视化
- preprocess: 数据集预处理
- labelspilt.py 将多标签分类数据集划分为训练集和验证集
- txt2coco.py 生成文字风格检测COCO标签
- txt2label.py 生成多标签分类数据集
- weights: 模型权重
- PPHGNet
- PPHGNetV2
- PPLCNetV2
二、赛题介绍
随着OCR和版面分析处理技术不断发展,信息电子化的效率已经大幅度提高,人工智能已经能够将很多格式规整的资料轻松转化为可编辑的电子文稿;但生活中更多的内容资料往往是复杂的,具有字体样式多元、颜色丰富的特点,因此实现复杂版面的识别至关重要。本次赛题希望选手有所突破,解决复杂版面的分析难点,精准识别扫描资料中的字体样式以及颜色,大幅度提高人们的使用效率。版式分析场景可以看成多标签分类的目标检测问题,需将不同风格样式的文字框选出来,并判断框选出来的文字实例具体包含哪些样式。其中,比赛的样式包含7种——红色、绿色、蓝色、加粗、斜体、删除线、下划线,需要注意的是,文字并非仅包含一种样式,有的文字图像可能既是蓝色,又是斜体。
-
比赛难点:
-
文字检测框并非矩形框,而是任意八点四边形。参赛者可以采用旋转矩形框、语义分割方法或热图方法获得更加精确的坐标结果。
-
文字的分类是多标签分类问题,而非多分类问题,由于风格样式和文字内容的多样性,对网络的泛化能力有一定要求。当然,也可以强行将其看成 2 7 {2}^{7} 27 = 128 类分类问题,但是这种思路计算成本较高,且由于类别随着样式增多指数级增长,不利用后续样式的扩充。
-
本次比赛对推理速度和显存有一定要求,耗时大于50ms性能将记为0分,显存为15G,内存为10G,需要参赛者在精度和速度之间进行权衡。
-
-
数据集样例可视化如下:

-
比赛链接 :https://aistudio.baidu.com/aistudio/competition/detail/850/0/introduction
-
成绩 :在 A 榜分数为 0.94618, 精度为 0.90307, 召回率为 0.98929, 单张图片测试耗时为 0.12455 s,在 B 榜分数为 0.93553, 精度为 0.89068, 召回率为 0.98038, 单张图片测试耗时为 0.12287 s
三、数据分析
-
数据说明: 本次比赛最新发布的数据集共包含训练集、A榜测试集、B榜测试集三个部分,其中训练集共 4904 张图片,A榜测试集共 1001 张图片。训练集包含图片和同名的txt标签,选手在使用中可以自行分配训练和测试。测试集A是A榜的测试集,仅包含图片,不包含标签;训练集中的txt文件中为json格式,格式示例如下:
-
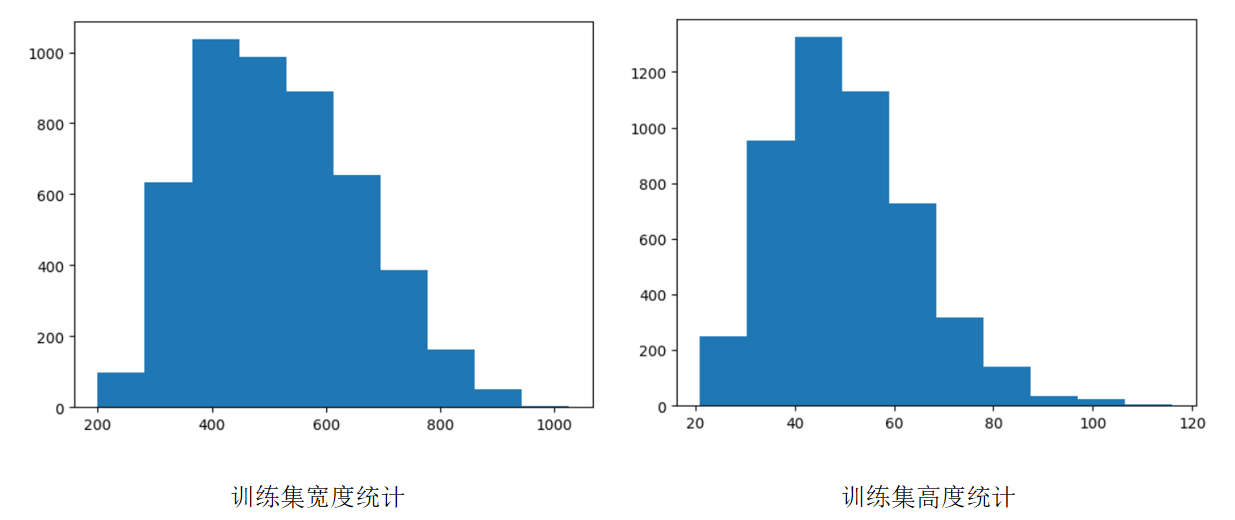
数据集统计: 如下图所示,训练集宽度集中分布在300到800 px之间,高度集中分布在 20-80 px 之间,由于高度小于宽度,我们将网络的按批次缩放范围设置为 320-800 px,以便有效利用各个尺度的文字图像。
四、评价指标
-
本次比赛的评价指标为:precision 和 recall。
- precision计算公式
precision = T P T P + F P \text { precision }=\frac{T P}{T P+F P} precision =TP+FPTP
- 针对每一个类别box,pred box与gt box计算iou>=0.5且水平方向iou>=0.8且类别正确记为TP,未匹配的pred box记为FP,同一gt box仅可正确匹配一次。最终precision为所有类别的平均precision。
- recall计算公式
recall = T P T P + F N \text { recall }=\frac{T P}{T P+F N} recall =TP+FNTP
- 针对每一个类别box,pred box与gt box计算iou>=0.5且水平方向iou>=0.8且类别正确记为TP,未匹配的gt box记为FN,同一gt box仅可正确匹配一次。最终recall为所有类别的平均recall
- 最终排名按照上述两个指标的加权分数从大到小依次排序,计算公式为
score = 0.5 ∗ precision + 0.5 ∗ recall \text { score }=0.5 * \text { precision }+0.5 * \text { recall } score =0.5∗ precision +0.5∗ recall
-
机器配置:V100,显存15G,内存10G;
-
单张图片耗时>50ms,决赛中的性能分数记0分。
-
根据评价指标可知, 边界框的匹配较为宽松,采用矩形框虽然会带来一定精度损失,但是与旋转框等方式不会有太大的差异,但是考虑到文字内容和风格样式的多样性,确定边界框的正确类别可能存在一定难度。此外,将图像推理耗时控制在50ms的性能要求需要参赛者在推理速度和精度上进行有效均衡。
五、方案介绍
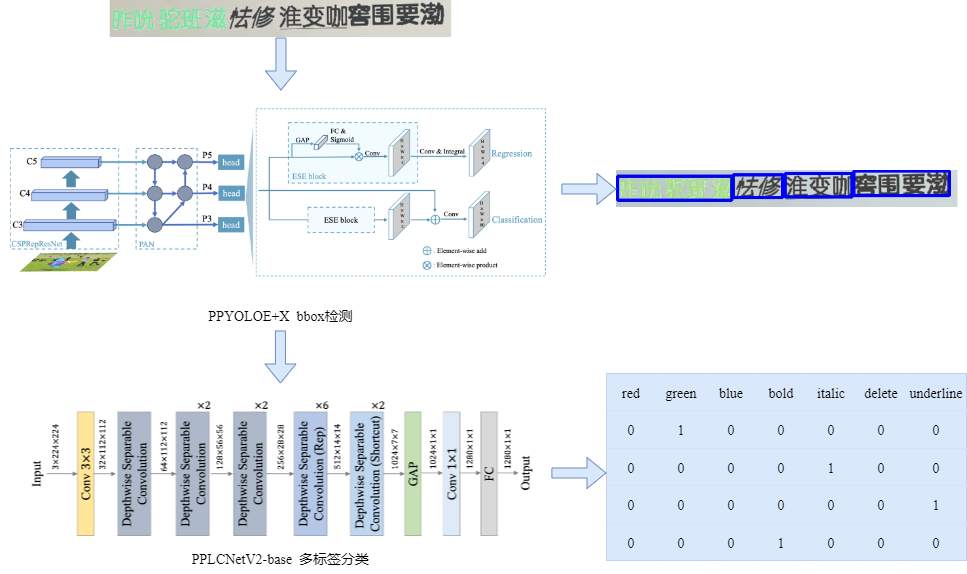
本方案是一种两阶段方案。我们将版式分析场景问题解耦为单目标检测问题和多标签分类问题。首先,我们使用 PP-YOLOE+ x 网络检测出不同样式的文字,之后利用 PP-LCNetV2 进行多标签分类。 对于 7 种样式, 我们使用sigmoid函数将预测分数映射到 0 到 1 之间。对于每一种样式,如果该样式的预测分数大于0.6,我们将该样式的标签设置为1,否则设置为 0。这里, PP-YOLOE+x 网络使用 PaddleDetection 实现, PP-LCNetV2 改写自 PaddleClas 源码。
六、训练细节
6.1 PP-YOLOE+ X
-
数据划分
- 该部分不对数据集进行划分,采用全部数据进行训练,并根据 A 榜样例图片可视化结果和 A 榜测评分数选择最优模型作为 B 榜提交模型。
-
数据增广
- 随机像素内容变换,包括对亮度、对比度、饱和度、色相角度、通道顺序的调整;随机扩张,填充值为 [123.675, 116.28, 103.53];随机裁剪; 随机翻转; 按批次随机缩放,缩放大小选取列表为 [320, 352, 384, 416, 448, 480, 512, 544, 576, 608, 640, 672, 704, 736, 768,800],; 归一化处理, 均值为 [0, 0, 0],标准差为 [1, 1, 1]
-
训练配置
-
总迭代周期: 80 epoch, 除数据处理外,训练配置均采用官方配置。所有训练均在 V100 32G GPU进行,训练时长约4个小时。
-
预训练模型: PP-YOLOE+ X 在 Object365 数据集上的预训练模型。
-
首先,我们采用 LinearWarmup 策略对 PP-YOLOE+ X 进行预热,其中,预热周期为 5 epochs。 之后,采用 CosineDecay 策略对学习率进行调整,其中,训练的基础学习率为 0.001, 训练周期为 75 epochs。此外,我们采用动量为 0.9 的 Momentum 优化器对网络进行优化。同时,我们采用 Focal loss 作为分类损失,采用 GIOU 作为回归损失,采用 L1 Loss 计算预测值与真实值之间的误差,采用 DF loss 计算预测分布与真实分布之间的距离,并将上述四个损失的加权和作为模型的总损失。
-
6.2 PP-LCNetV2-Base
-
数据生成
- 多标签分类数据集通过从原图像裁剪单个文字图像实例生成, 数据集样例可视化如下:

- 多标签分类数据集通过从原图像裁剪单个文字图像实例生成, 数据集样例可视化如下:
-
数据划分
- 训练集和测试集划分比例为 9:1。
-
数据增广
- 缩放填充、归一化(均值为 [0, 0, 0],标准差为 [1, 1, 1])
-
训练配置
-
模型总迭代周期为 40 epoch,(40个epoch后模型精度不再提升,所以epoch设置为40)选取验证集中汉明距离最小的模型作为提交模型 。所有训练均在 V100 32G GPU进行,训练时长约1.5个小时。
-
我们采用 MultiLabelLoss 作为损失函数,采用 AdamW优化器和 MultiStepDecay 学习率调度策略对网络进行优化,初始学习率为 0.5*1e-2, 学习率衰减列表为 [10, 20, 30, 40]。
-
6.3 数据集准备
# 解压数据集
!mkdir /home/aistudio/work/datasets
%cd /home/aistudio/work/datasets
!unzip /home/aistudio/data/data205363/train.zip
!unzip /home/aistudio/data/data205363/test.zip
# 生成文字风格检测COCO标签
!python /home/aistudio/work/preprocess/txt2coco.py
# 生成多标签分类数据集
%cd /home/aistudio/work/datasets
!mkdir crop_image save_weight
!python /home/aistudio/work/preprocess/txt2label.py# 将多标签分类数据集划分为训练集和验证集,划分比例为 9:1
%cd /home/aistudio/work/project
!python /home/aistudio/work/preprocess/labelsplit.py
6.4 PP-YOLOE+X 训练 (文字风格检测)
# 解压 PaddleDetection 套件
%cd /home/aistudio/work/PaddleDetection
!pip install -r requirements.txt --user
# !unzip /home/aistudio/PaddleDetection-develop.zip
# PP-YOLOE+x 训练,训练周期为 80 epochs, 每 1个 epoch 打印一次日志,每 5 个 epoch保存一次模型,耗时约3小时
! python tools/train.py -c configs/ppyoloe/ppyoloe_plus_crn_x_80e_coco.yml
6.5 PP-LCNetV2-Base 训练 (多标签分类)
%cd /home/aistudio/work/LabelClas
!python train_base.py
6.6 测试过程
# PP-YOLOE+x 模型保存目录为 /home/aistudio/PaddleDetection/output/ppyoloe_plus_crn_x_80e_coco/
%cd /home/aistudio/PaddleDetection
! python tools/export_model.py -c configs/ppyoloe/ppyoloe_plus_crn_x_80e_coco.yml \--output_dir=/home/aistudio/work/predict \-o weights=output/ppyoloe_plus_crn_x_80e_coco/best_model.pdparams
# 将训练好的模型拷贝到 predict.py 目录下, 这里拷贝的路径为之前训练好的模型路径,
# PP-LCNetV2-Base 模型保存路径为 /home/aistudio/work/weights/PPLCNetV2/save_weight/base_best_model
!cp /home/aistudio/work/weights/PPLCNetV2/save_weight/base_best_model /home/aistudio/work/predict_code
# 预测结果可视化,耗时约48s
%cd /home/aistudio/work/predict/
!rm -r ./output_visualize
!mkdir output_visualize
!python visualize.py /home/aistudio/work/datasets/test /home/aistudio/work/predict/output_visualize
/home/aistudio/work/predict
W0605 14:06:28.039301 21408 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0605 14:06:28.042666 21408 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
# 提交测试,耗时约64s
%cd /home/aistudio/work/predict/
!rm -r ./output
!mkdir output
!python predict.py /home/aistudio/work/datasets/test /home/aistudio/work/predict/output
/home/aistudio/work/predict
W0605 14:07:47.061200 21713 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0605 14:07:47.064639 21713 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
8.2.
# 打包提交,打包前,请务必保证训练模型已经导出,且提交测试通过
%cd /home/aistudio/work/predict_code/
!zip -r together_5_23_1.zip ./ppyoloe_plus_crn_x_80e_coco predict.py ./models base_best_model
六、调参过程
| 网络 | lr | optimizer | score | recall | precision | time_used |
|---|---|---|---|---|---|---|
| PPYOLOE+l&PPLCNet | 0.001 | Momentum | 0.86513 | 0.81548 | 0.91477 | 0.06881 |
| PPYOLOE+l&PPLCNet | 0.001 | AdamW | 0.88006 | 0.85694 | 0.90319 | 0.07733 |
| PPYOLOE+x&PPLCNet | 0.001 | AdamW | 0.88648 | 0.85221 | 0.92075 | 0.08264 |
| PPYOLOE+x&PPLCNetV2-Base(A榜) | 0.001 | AdamW | 0.94618 | 0.90307 | 0.98929 | 0.12455 |
| PPYOLOE+x&PPLCNetV2-Base(B榜) | 0.001 | AdamW | 0.93553 | 0.89068 | 0.98038 | 0.12287 |
七、总结与展望

参考项目
[1] 百度网盘AI大赛——版式分析场景 Baseline
https://aistudio.baidu.com/aistudio/projectdetail/5869129
[2] 百度网盘AI大赛-表格检测第2名方案
https://aistudio.baidu.com/aistudio/projectdetail/5398861
此文章为搬运
原项目链接
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!