为什么要学习汇编?学习汇编有哪些好处?
目录
1、多线程问题实例
2、理解该多线程问题的预备知识
2.1、二进制机器码和汇编代码
2.2、多线程切换与CPU时间片
2.3、多线程创建与线程函数
3、从汇编代码的角度去理解多线程问题
4、问题解决办法
5、熟悉汇编代码有哪些用处?
5.1、在代码中插入汇编代码块,提升代码的执行效率
5.2、在分析C++软件异常时可能需要查看汇编代码
5.3、从汇编代码的角度可以理解很多高级语言没法理解的编程细节
6、在Visual Studio中调试C++源码不知为啥会出问题时,可以尝试转到汇编代码页面去逐行调试汇编代码
6.1、通过调试汇编代码去排查问题的实例
6.2、如何跳转到目标函数的汇编代码中?如何在汇编代码上设置断点呢?
VC++常用功能开发汇总(专栏文章列表,欢迎订阅,持续更新...)![]() https://blog.csdn.net/chenlycly/article/details/124272585C++软件异常排查从入门到精通系列教程(专栏文章列表,欢迎订阅,持续更新...)
https://blog.csdn.net/chenlycly/article/details/124272585C++软件异常排查从入门到精通系列教程(专栏文章列表,欢迎订阅,持续更新...)![]() https://blog.csdn.net/chenlycly/article/details/125529931C++软件分析工具从入门到精通案例集锦(专栏文章正在更新中...)
https://blog.csdn.net/chenlycly/article/details/125529931C++软件分析工具从入门到精通案例集锦(专栏文章正在更新中...)![]() https://blog.csdn.net/chenlycly/article/details/131405795C/C++基础与进阶(专栏文章,持续更新中...)
https://blog.csdn.net/chenlycly/article/details/131405795C/C++基础与进阶(专栏文章,持续更新中...)![]() https://blog.csdn.net/chenlycly/category_11931267.html 以前经常说,C++开发人员要了解汇编,了解汇编后有很多好处,今天正好得空写一篇汇编相关的文章。熟悉汇编,不仅可以辅助排查C++软件异常问题,还可以理解很多高级语言不好理解的编程细节(从汇编代码的角度可以看到代码的完整执行细节),特别是多线程编程中的问题。下面我们就来讲解一个典型的从汇编代码去理解多线程问题的实例,然后详细总结一下熟悉汇编代码的用处。
https://blog.csdn.net/chenlycly/category_11931267.html 以前经常说,C++开发人员要了解汇编,了解汇编后有很多好处,今天正好得空写一篇汇编相关的文章。熟悉汇编,不仅可以辅助排查C++软件异常问题,还可以理解很多高级语言不好理解的编程细节(从汇编代码的角度可以看到代码的完整执行细节),特别是多线程编程中的问题。下面我们就来讲解一个典型的从汇编代码去理解多线程问题的实例,然后详细总结一下熟悉汇编代码的用处。

1、多线程问题实例
《Windows核心编程》一书中,在第八章讲到多线程同步时,有个多线程操作一个全局变量的实例。这个实例是通过汇编代码去理解多线程执行细节的一个很典型的例子。
该例子中定义了一个long型的全局变量,然后创建了两个线程,线程函数分别是ThreadFunc1和ThreadFunc2,这两个线程函数中均对g_x变量进行自加操作(在访问共享变量g_x时未加锁同步),相关代码如下:
// define a global variable
long g_x = 0;DWORD WINAPI ThreadFunc1(PVOID pvParam)
{g_x++;return 0;
}DWORD WINAPI ThreadFunc2(PVOID pvParam)
{g_x++;return 0;
}这里有个问题,当这两个线程函数执行完后,全局变量g_x的值会是多少呢?一定会是2吗?
实际上,在两个线程函数执行完后,g_x的值不一定为2。这个实例需要从汇编代码的角度去理解,从C++源码看则很难搞懂,这是一个从汇编代码角度去理解代码执行细节的典型实例。
2、理解该多线程问题的预备知识
要理解上述多线程问题,需要了解一些基础知识,下面我们就来看看这些知识。
2.1、二进制机器码和汇编代码

C++代码经过编译链接后生成的是二进制机器代码,存放在二进制文件中。在CPU中最终执行的是一条一条二进制机器码。汇编代码和二进制机器代码是等价的,汇编代码可读性比较强,所以我们一般去看汇编代码。一条汇编指令是CPU中执行的最小粒度。
2.2、多线程切换与CPU时间片
线程是系统调度CPU时间片的最小单元,当线程失去CPU时间片时,会将当前线程的上下文信息保存到CONTEXT结构体中(这其中就包含各个寄存器的值),线程暂停执行。线程上下文结构体CONTEXT的定义类似如下:(该结构体定义位于winnt.h头文件中)
//
// Context Frame
//
// This frame has a several purposes: 1) it is used as an argument to
// NtContinue, 2) is is used to constuct a call frame for APC delivery,
// and 3) it is used in the user level thread creation routines.
//
// The layout of the record conforms to a standard call frame.
//typedef struct _CONTEXT {//// The flags values within this flag control the contents of// a CONTEXT record.//// If the context record is used as an input parameter, then// for each portion of the context record controlled by a flag// whose value is set, it is assumed that that portion of the// context record contains valid context. If the context record// is being used to modify a threads context, then only that// portion of the threads context will be modified.//// If the context record is used as an IN OUT parameter to capture// the context of a thread, then only those portions of the thread's// context corresponding to set flags will be returned.//// The context record is never used as an OUT only parameter.//DWORD ContextFlags;//// This section is specified/returned if CONTEXT_DEBUG_REGISTERS is// set in ContextFlags. Note that CONTEXT_DEBUG_REGISTERS is NOT// included in CONTEXT_FULL.//DWORD Dr0;DWORD Dr1;DWORD Dr2;DWORD Dr3;DWORD Dr6;DWORD Dr7;//// This section is specified/returned if the// ContextFlags word contians the flag CONTEXT_FLOATING_POINT.//FLOATING_SAVE_AREA FloatSave;//// This section is specified/returned if the// ContextFlags word contians the flag CONTEXT_SEGMENTS.//DWORD SegGs;DWORD SegFs;DWORD SegEs;DWORD SegDs;//// This section is specified/returned if the// ContextFlags word contians the flag CONTEXT_INTEGER.//DWORD Edi;DWORD Esi;DWORD Ebx;DWORD Edx;DWORD Ecx;DWORD Eax;//// This section is specified/returned if the// ContextFlags word contians the flag CONTEXT_CONTROL.//DWORD Ebp;DWORD Eip;DWORD SegCs; // MUST BE SANITIZEDDWORD EFlags; // MUST BE SANITIZEDDWORD Esp;DWORD SegSs;//// This section is specified/returned if the ContextFlags word// contains the flag CONTEXT_EXTENDED_REGISTERS.// The format and contexts are processor specific//BYTE ExtendedRegisters[MAXIMUM_SUPPORTED_EXTENSION];} CONTEXT;上述结构体的部分字段就对应着各个寄存器。
当该线程获取时间片时,会将之前保存的CONTEXT结构体中的线程上下文信息恢复到线程中(包括恢复各个寄存器的值),线程继续向下执行。
2.3、多线程创建与线程函数
调用CreateThread或者__beginthreadex发起创建线程请求,线程创建起来后就会进入线程函数,但注意CreateThread或者__beginthreadex返回时不代表已经运行到线程函数中了(这个问题我们在排查C++软件异常崩溃时领教过)。线程函数执行完,线程函数退出后,线程也就结束了。
3、从汇编代码的角度去理解多线程问题
对g_x变量的自加这句C++代码,对应的汇编代码如下:
MOV EAX, [g_x] // 将g_x变量的值读到EAX寄存器中
INC EAX // 将EAX中的值执行自加操作
MOV [g_x], EAX // 然后将EAX中的值设置到g_x变量内存中看C++代码:g_x++,有些人可能觉得就一个自加操作,应该执行很快的,中间似乎不会被打断。会不会被打断,其实要看汇编代码的,这行C++源码对应三行汇编代码,只能保证CPU执行某条汇编指令时不会被打断(汇编指令是CPU执行的最小粒度),但3条汇编指令,指令与指令之间是可能被打断的。
为什么说两个线程执行完成后g_x变量的值是不确定的呢?比如可能存在两种场景:
1)场景1(最终结果g_x=2)
假设线程1先快速执行了三行汇编指令,未被打断,g_x的值变成1。然后紧接着线程2执行,在g_x=1的基础上累加,最终两个线程执行完后,g_x等于2。
2)场景2(最终结果g_x=1)
假设线程1先执行,当执行完前两条汇编指令后,线程1失去时间片(线程上下文信息保存到CONTEXT结构体中):

即线程1前两条汇编指令执行完,第3条汇编指令还没来得及执行,就失去CPU时间片了!
线程2执行,一次执行完三条指令,当前g_x=1。然后线程1获得CPU时间片,因为上次执行两条汇编指令后EAX寄存器中的值为1,因为线程1获取了时间片,保存线程上下文信息的CONTEXT恢复到线程1中,EAX=1,继续执行第3条指令,执行完后g_x还是1。
所以,这个多线程问题,需要从汇编代码的角度去理解,从C++源码的角度很难想明白。
4、问题解决办法
从本例可以看出,即使是简单的变量自加操作,多线程操作时也要做同步,可以加锁,可以使用系统的原子锁Interlocked系列函数,比如原子自加函数InterlockedIncrement和原子自减函数InterlockedDecrement:
LONG InterlockedIncrement( LPLONG volatile lpAddend // variable to increment
);LONG InterlockedDecrement( LPLONG volatile lpAddend // variable address
);这些原子函数能保证会被原子地被执行,中间不会被打断。 修改后的代码为:
// define a global variable
long g_x = 0;DWORD WINAPI ThreadFunc1(PVOID pvParam)
{InterlockedIncrement(&g_x); // 调用原子锁函数InterlockedIncrement实现自加return 0;
}DWORD WINAPI ThreadFunc2(PVOID pvParam)
{InterlockedIncrement(&g_x); // 调用原子锁函数InterlockedIncrement实现自加return 0;
}5、熟悉汇编代码有哪些用处?
汇编代码是底层语言,从事高级语言开发的开发人员在编码过程中没有接触过,但熟悉汇编代码有很多好处。
5.1、在代码中插入汇编代码块,提升代码的执行效率
一般我们会在一些对执行效率要求比较高的代码中嵌入汇编代码,提高代码的执行效率,汇编代码的执行效率是最高的。比如我们在处理音视频编解码的算法代码中,时常会嵌入一些汇编代码,以提高代码的运行速度,比如音视频编解码模块负责色彩空间转换的接口都是汇编代码实现的(汇编代码实现的函数是开源的),如下:

有人可能会问,经过IDE编译出来的二进制文件中也都是汇编指令,你人为的添加一段汇编代码,都是汇编代码,为啥会有执行速度上的差别呢?因为源代码经过编译器的处理生成的汇编代码在实现上可能不是最优的,这要依赖编译器,而我们人为地添加汇编,可以直接控制汇编代码,保证汇编代码是最优的,不再依赖编译器。
5.2、在分析C++软件异常时可能需要查看汇编代码
一般程序是崩溃在某一条汇编指令上,汇编指令才能最直接反映为什么会发生崩溃。比如汇编指令中访问了一个不应该访问的地址,比如一个很小的内存地址(64K地址范围内的地址是小地址内存 区,禁止访问),如下:

或者一个很大的内核态地址(用户态的代码不能访问内核态的地址),如下:

都会引发崩溃。此外,有时分析崩溃时,需要查看汇编代码上下文去辅助分析。
排查的C++软件异常与崩溃问题多了,就会知道汇编代码的好了,才会有深刻的理解和体会的!
5.3、从汇编代码的角度可以理解很多高级语言没法理解的编程细节
比如函数调用时主调函数是如何将参数传递给被调用函数的。比如,有如下的实现两个整型变量相加的函数AddSum,在调用该函数时传入的参数代码如下:
int AddNum( int a, int b)
{int nSum = a + b;return nSum;
}void CTestDlgDlg::OnBnClickedBtnTest()
{int a = 3;int b = 4;int nSum = AddNum( a, b );
}我们在调用AddSum接口是通过栈将要传递的参数传给被调用函数AddSum的,我们通过汇编代码可以清楚看到这一过程:(可以直接在Visual Studio中看到上述C++代码的汇编代码)
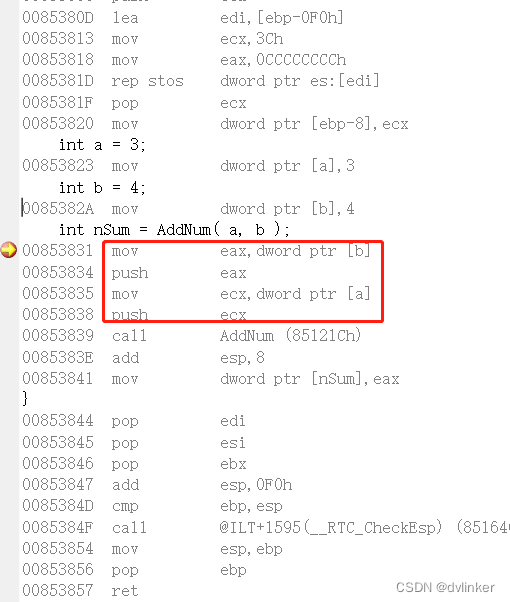
从上述汇编代码上我们清楚地看到,在call AddSum函数之前,把要传递的参数a和b都压到了栈上!
在Visual Studio中查看C++代码对应的汇编代码的方法:在要查看汇编代码的函数中添加断点,然后开启调试,在命中断点后,右键点击,在弹出的右键菜单中点击“查看反汇编”,即可查看汇编代码。
再比如,从汇编代码的角度可以很好地理解多线程编程中的细节问题,比如上面讲到的两个线程同时对一个long型变量进行自加操作的多线程问题。
还比如,之前讲到Switch...case语句中case分支过多引发Stack Overflow线程栈溢出问题时,虽然变量定义在case分支中,虽然生命周期在case分支中,但变量的栈内存在所在函数的入口处就已经分配了,可以通过汇编代码看出来。比如如下的case分支代码:
void TestCaseFunc()
{int nType = 3;switch(nType){case 0:{//STARTUPINFO startInfo;//memset(&startInfo, 0, sizeof(startInfo));// ...break;}case 1:{SHELLEXECUTEINFO shellexecuteInfo;memset(&shellexecuteInfo, 0, sizeof(shellexecuteInfo));// ...break;}case 2:{STARTUPINFO startInfo2;memset(&startInfo2, 0, sizeof(startInfo2));// ...break;}case 3:{SHELLEXECUTEINFO shellexecuteInfo2;memset(&shellexecuteInfo2, 0, sizeof(shellexecuteInfo2));// ...break;}case 4:{STARTUPINFO startInfo4;memset(&startInfo4, 0, sizeof(startInfo4));// ...break;}}
}直接在Visual Studio中查看该函数的汇编代码:
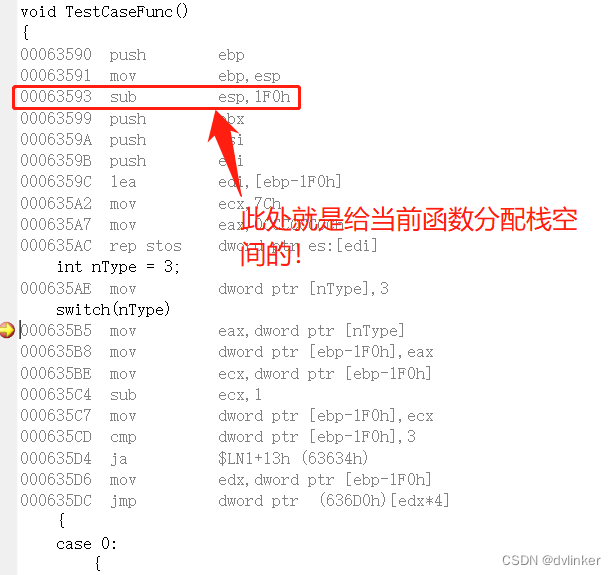
可以新增或删减case分支,然后观察函数入口处分配的栈空间大小的变化!
在我们排查不出问题时,可以尝试着去查看汇编代码,甚至可以直接去调试汇编代码!
6、在Visual Studio中调试C++源码不知为啥会出问题时,可以尝试转到汇编代码页面去逐行调试汇编代码
程序最终执行的是二进制文件中的一条一条汇编指令,看汇编指令才能看到代码的详细执行步骤与细节。当我们在Visual Studio调试C++源码不知为啥会出问题时,可以尝试跳转到汇编页面去单步调试汇编代码,调试汇编代码会更直接更直观,能看到具体的执行细节和问题的本质。在日常工作中,我们在调试C++源码搞不清楚问题时,会去尝试调试汇编代码,确实解决了一些问题。
6.1、通过调试汇编代码去排查问题的实例
比如前段时间遇到的Stack overflow线程栈溢出的问题,问题是出在某个函数中,但崩溃时的函数调用堆栈中并没有看到这个函数,后来查看代码上下文才感觉问题可能出在这个函数中。至于函数调用堆栈中没有该函数,可能是执行到函数的入口处就出问题了,还没有安全进入该函数。
从C++源码看,函数入口处就是函数最开始的源码,实际上从汇编代码的角度看,函数入口处有很多除C++源码对应汇编代码之外的汇编代码,比如保存主调函数栈基址和设置当前被调用函数的栈基址的汇编:
push ebp
mov ebp, esp还有保护主调函数中相关寄存器值的保护现场的汇编代码,还有给当前函数分配栈空间的汇编代码,甚至有校验当前线程的栈空间是否溢出的汇编代码。然后接下来,才是函数中C++源码对应的汇编代码。
而本问题就崩溃在校验当前线程栈空间是否达到上限的汇编代码test dword ptr [eax],eax上,如下所示:
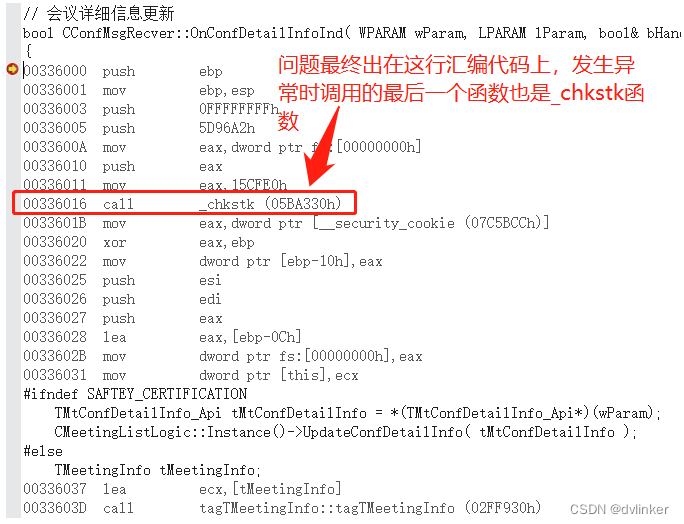
为什么会引发线程占用的栈空间达到上限呢?是因为该函数中使用了几个很大的结构体定义了局部变量,局部变量占用的是栈空间,导致当前线程占用的栈空间达到上限,进而产生Stack overflow线程栈溢出的异常。当时想到了调试汇编代码,跳转到该问题函数的汇编代码处,在函数入口处的汇编代码上打断点,然后单步调试汇编代码定位问题的。
关于这个问题的详细排查过程,可以查看我之前写的文章:
线程栈溢出异常,程序崩溃在汇编代码test dword ptr [eax],eax上的问题排查![]() https://blog.csdn.net/chenlycly/article/details/131743305
https://blog.csdn.net/chenlycly/article/details/131743305
6.2、如何跳转到目标函数的汇编代码中?如何在汇编代码上设置断点呢?
其实很简单,只要在程序初始化的地方随便添加一个断点,然后启动调试,当命中断点后,找到目标函数的源码,然后右键点击函数的源码,在弹出的右键菜单中点击“转到反汇编”菜单项,就跳转到目标函数的汇编代码页,然后就可以在汇编代码中设置断点了。设置完断点后,按下F5让程序继续运行,直到命中汇编代码中的断点,就能单步调试汇编代码了。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!