爬虫p站,下载喜欢的博主所有作品——7月2日
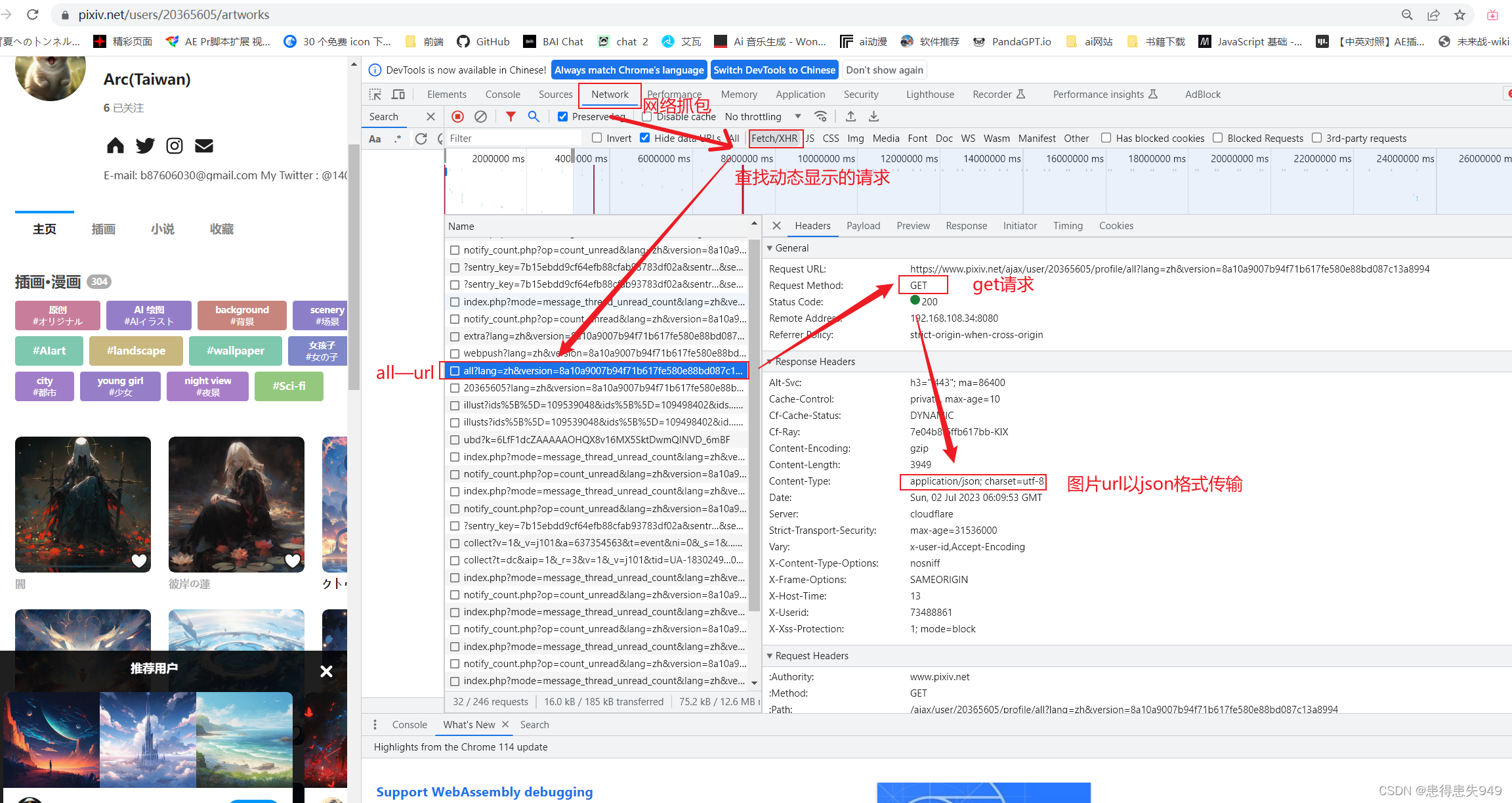
url获得的图片所有链接以
url = ‘https://www.pixiv.net/ajax/user/20365605/profile/all’ 获取
就只需要修改中间的数字
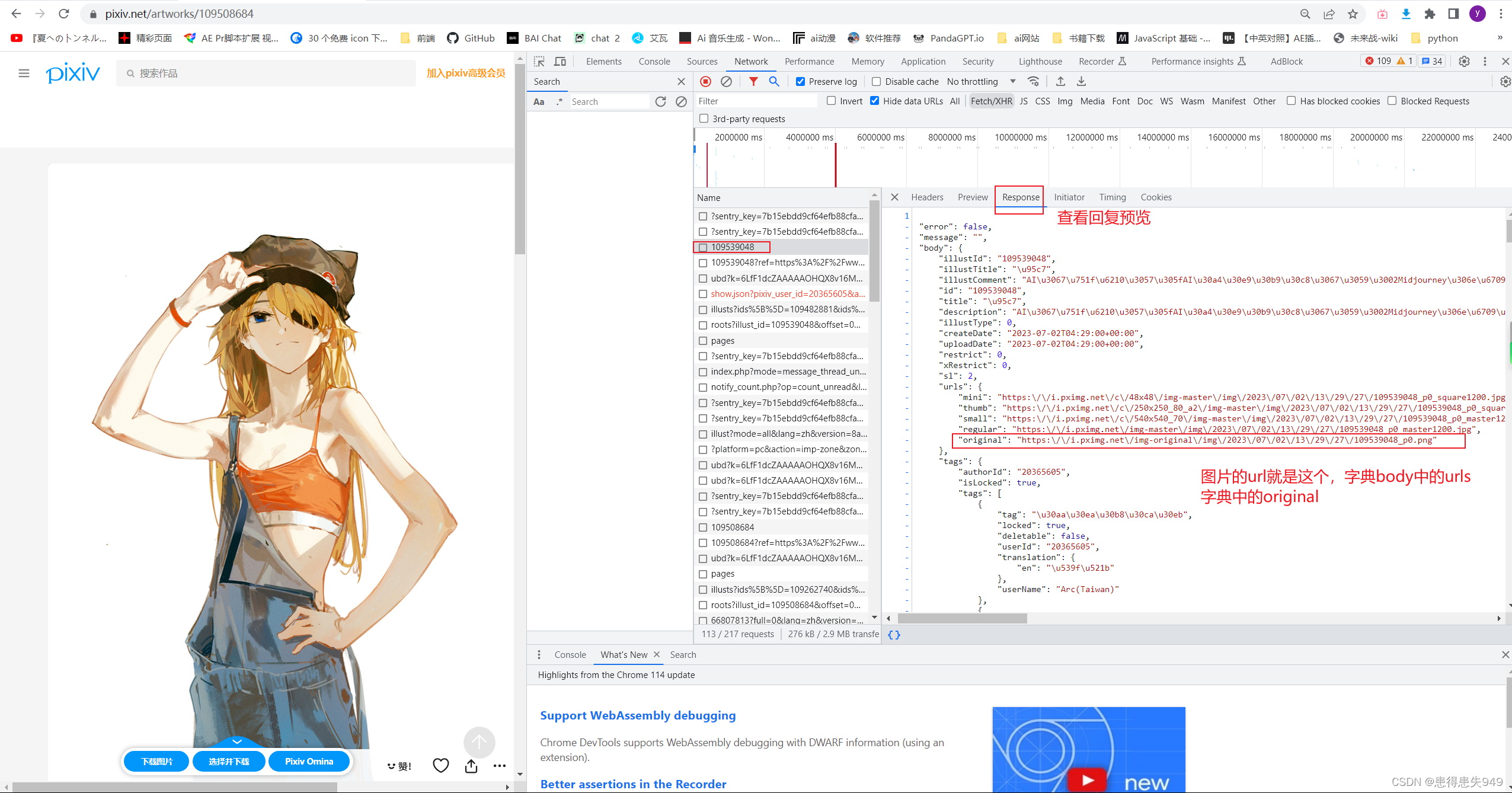
获得到了图片详情页的特定数字,就可拼出详情页的url,url = 'https://www.pixiv.net/ajax/illust/' + str(特定的数字)

import requests
import timedef download_img(url): # 获取到图片url后定义个函数用于下载headers_download = {"referer": "https://www.pixiv.net/"# 这里携带referer因为p站的图片链接都是防盗链# 只要加上这个链接就会认为你是从p站访问过来的就会让你正常访问了}response = requests.get(url=url, headers=headers_download)name = url.split("/")[-1]# 将图片链接以斜杠分割后取最后面的信息作为名字,因为爬取的图片有jeg也有pngwith open("./png/" + name, "wb") as f: # 创建一个以图片链接对应名字的文件,需要自己创建png目录f.write(response.content) # 将图片二进制数据存入,图片也就得到了print(name + "下载成功")url = 'https://www.pixiv.net/ajax/user/20365605/profile/all'
headers = {'User-Agent':'你的user—agent','Cookie': '你的cookie', "referer": "https://www.pixiv.net/"
}
params = {'lang': 'zh','version': '8a10a9007b94f71b617fe580e88bd087c13a8994',
}
html = requests.get(url=url, headers=headers, params=params).json()
print(type(html))
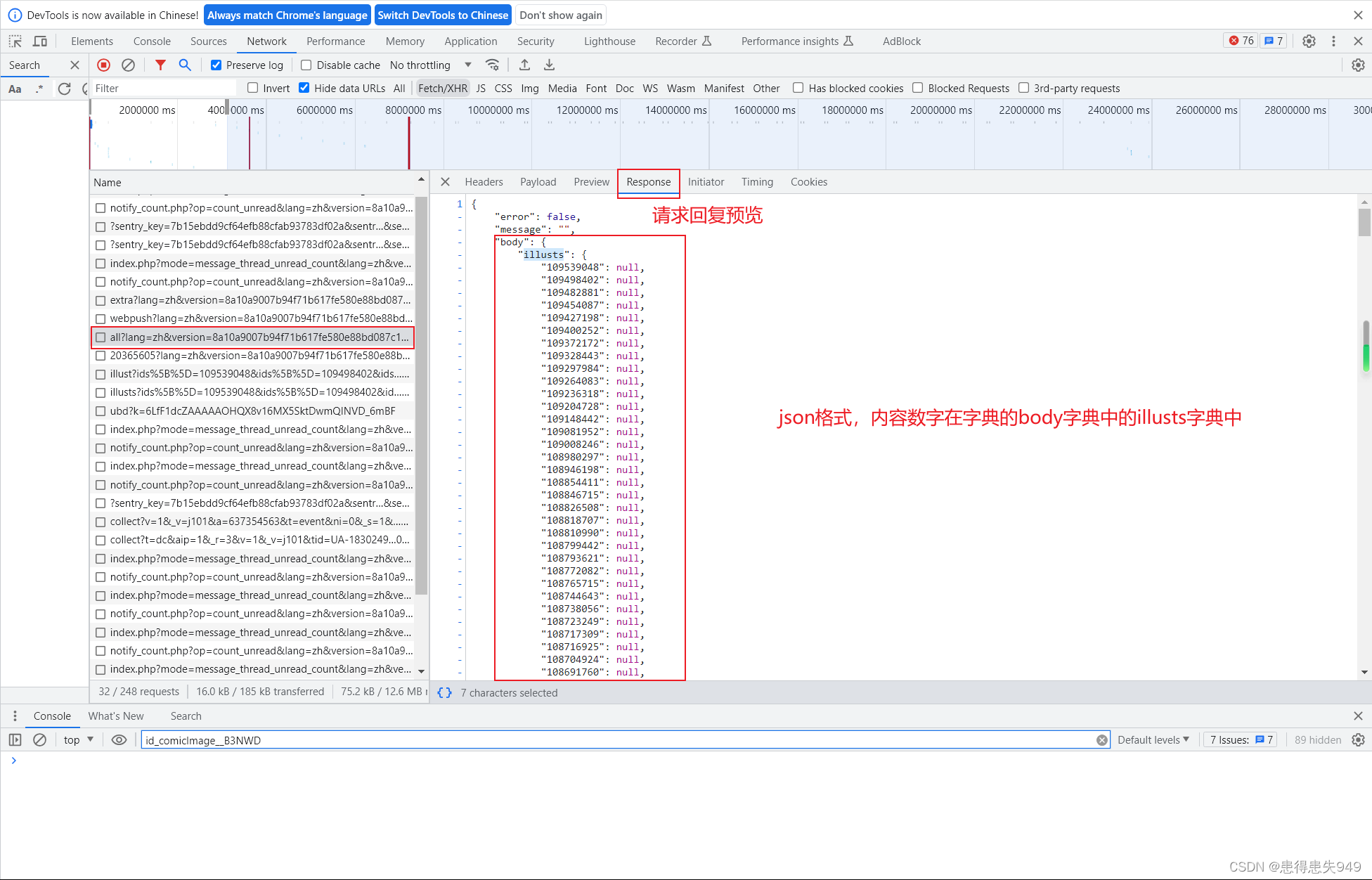
# 提取博主所有作品的图片特定数字链接
urls = html['body']['illusts']
print(urls)
key_id_list = []
for number, key in enumerate(urls.keys(), start=1):print(key)key_id_list.append(int(key))print(number)
print(key_id_list)
time.sleep(2)#休息两秒# 得到所有图片的链接
url = 'https://www.pixiv.net/ajax/user/20365605/profile/illusts'
params = {'ids[]': key_id_list[:48],'work_category': 'illustManga','is_first_page': 1,'lang': 'zh','version': '8a10a9007b94f71b617fe580e88bd087c13a8994',
}
img_all_url = requests.get(url=url, headers=headers, params=params).json()
print(img_all_url)
##下载缩略图
# numeric_values = [value['url'] for key, value in img_all_url['body']['works'].items() if key.isdigit()]
# print(numeric_values)
# print(len(numeric_values))
# for index,i in enumerate(numeric_values,start=1):
# print(index,"图片正在下载中")
# download_img(i)
# time.sleep(1)
# print(index,"图片下载完成")
# 下载原图
for index, i in enumerate(key_id_list, start=1):print(index, "图片正在下载中")url = 'https://www.pixiv.net/ajax/illust/' + str(i)img_json = requests.get(url=url, headers=headers).json()urls = img_json['body']['urls']['original']download_img(urls)time.sleep(2)print(index, "图片下载完成")
# download_img(urls)
# 下载图片# with open('pixiv.html','w',encoding='utf-8') as f:
# f.write(html)参考文章
参考文章:https://zhuanlan.zhihu.com/p/557657010
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!