python+selium模拟浏览器,在知网高级检索页面进行全文检索,获取页面数据并录入excel(非下载文献)
目录
- 序言
- 函数模块介绍
- 创建模拟浏览器对象
- 只需要执行一次的部分
- 需要批量执行的重复操作部分
- 获取网页数据
- 录入excel
- 主函数
- 本地文件结构
- 全部代码
- 结果预览
- 控制台
- 文件
序言
场景是在知网高级检索界面中,选择报纸–>点击包含非学术文献–>改成全文模式–>点击检索页发表年度–>获取括号内的数字和对应的年份
需要三个库,都可以用pip install轻松下载,稍微麻烦点儿的是需要去下载个对应版本的chromedriver.exe驱动,放到python或者Anaconda的文件夹目录下,然后添加环境变量(这部分报错了自行百度即可,操作起来不麻烦的)
注意time.sleep()是必要的,一是为了避免频繁操作被浏览器提醒,二是在网络不好的情况下让网页加载完全,否则都会导致报错
一定不要图快,目前我是8s左右完成一次检索和数据录入,老师给我的要求是700次左右,也就运行个一个半个小时
这之中还会遇到诸多问题,在代码的注释里也都写到了
函数模块介绍
创建模拟浏览器对象
# 返回虚拟浏览器对象
def openUrl(url):driver = webdriver.Chrome()driver.get(url)time.sleep(3)return driver
只需要执行一次的部分
xpath如何获取百度一下即可
# 只运行一次,避免重复操作影响效率
def onceClick(driver):#选择报纸栏driver.find_element_by_xpath('/html/body/div[3]/div[1]/div/ul[1]/li[4]/a').click()time.sleep(2)#点击包含非学术文献driver.find_element_by_xpath('/html/body/div[2]/div/div[2]/div/div[1]/div[1]/div[2]/div[1]/div[1]/label/input').click()time.sleep(1)#更改为全文模式driver.find_element_by_xpath('//*[@id="gradetxt"]/dd[1]/div[2]/div[1]').click()time.sleep(2)driver.find_element_by_xpath('//*[@id="gradetxt"]/dd[1]/div[2]/div[1]/div[2]/ul/li[5]').click()time.sleep(2)
需要批量执行的重复操作部分
这部分主要是知网页面的交互产生的问题,反复改了好几次终于解决了
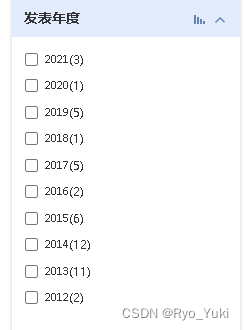
第一次检索的时候发表年度页面是关着的
第二次又变成了不关,但是如果要获取更多需要点击最下面的键,因此引入了flag(结合主函数看)
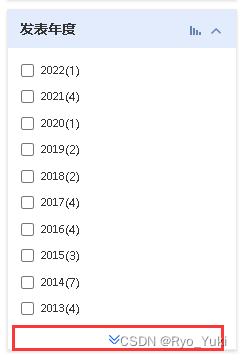
try-except是为了防止年份数量不足而报错,因为有些关键词出现得很少,就不需要点击上图这个键,如果不try掉就会报错终止运行
# 输入关键词并点击,循环操作
def send_and_click(driver,kw,np,flag): #输入主题词driver.find_element_by_xpath('//*[@id="gradetxt"]/dd[1]/div[2]/input').send_keys(kw)time.sleep(0.5)#输入报纸名字driver.find_element_by_xpath('//*[@id="gradetxt"]/dd[3]/div[2]/input').send_keys(np)time.sleep(0.5)#点击检索driver.find_element_by_xpath('/html/body/div[2]/div/div[2]/div/div[1]/div[1]/div[2]/div[2]/input').click()time.sleep(1.5)if flag==True:#第一次检索时需要展开发表年度大标题driver.find_element_by_xpath('//*[@id="divGroup"]/dl[3]/dt').click()time.sleep(2)if flag==False:#第二次开始,发表年度仅缩小,没有收回到大标题,所以展开发表年度缩小的页面,#使用try-except是为了防止年份数量不足而报错,影响程序进行try:driver.find_element_by_xpath('//*[@id="divGroup"]/dl[3]/dd/div/a').click()time.sleep(1)except:pass#打开被缩小的检索页driver.find_element_by_xpath('/html/body/div[2]/div/div[2]/div/div[2]/a[2]').click()time.sleep(0.5)#清空原有内容driver.find_element_by_xpath('//*[@id="gradetxt"]/dd[1]/div[2]/input').clear()driver.find_element_by_xpath('//*[@id="gradetxt"]/dd[3]/div[2]/input').clear()time.sleep(1)
获取网页数据
这个部分主要还是根据自己的需求来,这边我是返回列表
# 获取内容并返回数量列表
def getData_and_print(driver,tw,dp):cntDict={}for index in range(1,13):try:text1=driver.find_element_by_xpath('//*[@id="divGroup"]/dl[3]/dd/div/ul/li['+str(index)+']').textcntDict[text1[:4]]=text1[5:-1]except:continue for i in years:if i not in cntDict.keys():cntDict[i]='0' cnttuplelist=[]cntlist=[]for i in sorted (cntDict,reverse=False): if int(i)>=2011 and int(i)<=2018:cnttuplelist.append((i, cntDict[i]))cntlist.append(cntDict[i]) else:continuefor ct1,ct2 in cnttuplelist:print(dp+'\t\t\t'+ct1+'\t'+tw+'\t\t'+ct2) return cntlist
录入excel
这个部分也是根据自己的需求来,主要是找准数据的录入规则
#加载并将数据写入excel指定位置
def load_into_excel(datalist,indexi,indexj):wb=openpyxl.load_workbook('data.xlsx')ws=wb['Sheet1']for i in range(len(datalist)):ws.cell(row=i+8*indexi+2,column=4+indexj).value=datalist[i] wb.save("data.xlsx")
主函数
#主函数
if __name__ =='__main__':driver=openUrl('https://kns.cnki.net/kns8/AdvSearch?dbprefix=CFLS&&crossDbcodes=CJFQ%2CCDMD%2CCIPD%2CCCND%2CCISD%2CSNAD%2CBDZK%2CCCJD%2CCCVD%2CCJFN')onceClick(driver)flag=Truefor indexi,dp in enumerate(dailyPapers):#报纸为行for indexj,tw in enumerate(topicWords):#关键词为列send_and_click(driver,tw,dp,flag)flag=False #运行第一次后,标记flag为Falsecntlist=getData_and_print(driver,tw,dp)load_into_excel(cntlist,indexi,indexj)driver.close()
本地文件结构
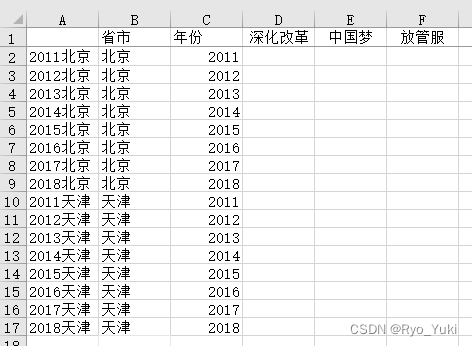
只需要将data.xlsx和代码文件放一起即可,或者用绝对路径也可

data.xlsx要求标题等事先按自己的要求准备好,代码只输入数据
全部代码
from selenium import webdriver
import time
import openpyxl
#自定义内容
topicWords=['深化改革','中国梦','放管服']
dailyPapers=['北京日报','天津日报']
years='2022','2021','2020','2019','2018','2017','2016','2015','2014','2013','2012','2011']# 返回虚拟浏览器对象
def openUrl(url):driver = webdriver.Chrome()driver.get(url)time.sleep(3)return driver# 只运行一次,避免重复操作影响效率
def onceClick(driver):#选择报纸栏driver.find_element_by_xpath('/html/body/div[3]/div[1]/div/ul[1]/li[4]/a').click()time.sleep(2)#点击包含非学术文献driver.find_element_by_xpath('/html/body/div[2]/div/div[2]/div/div[1]/div[1]/div[2]/div[1]/div[1]/label/input').click()time.sleep(1)#更改为全文模式driver.find_element_by_xpath('//*[@id="gradetxt"]/dd[1]/div[2]/div[1]').click()time.sleep(2)driver.find_element_by_xpath('//*[@id="gradetxt"]/dd[1]/div[2]/div[1]/div[2]/ul/li[5]').click()time.sleep(2)# 输入关键词并点击,循环操作
def send_and_click(driver,kw,np,flag): #输入主题词driver.find_element_by_xpath('//*[@id="gradetxt"]/dd[1]/div[2]/input').send_keys(kw)time.sleep(0.5)#输入报纸名字driver.find_element_by_xpath('//*[@id="gradetxt"]/dd[3]/div[2]/input').send_keys(np)time.sleep(0.5)#点击检索driver.find_element_by_xpath('/html/body/div[2]/div/div[2]/div/div[1]/div[1]/div[2]/div[2]/input').click()time.sleep(1.5)if flag==True:#第一次检索时需要展开发表年度大标题driver.find_element_by_xpath('//*[@id="divGroup"]/dl[3]/dt').click()time.sleep(2)if flag==False:#第二次开始,发表年度仅缩小,没有收回到大标题,所以展开发表年度缩小的页面,#使用try-except是为了防止年份数量不足而报错,影响程序进行try:driver.find_element_by_xpath('//*[@id="divGroup"]/dl[3]/dd/div/a').click()time.sleep(1)except:pass#打开被缩小的检索页driver.find_element_by_xpath('/html/body/div[2]/div/div[2]/div/div[2]/a[2]').click()time.sleep(0.5)#清空原有内容driver.find_element_by_xpath('//*[@id="gradetxt"]/dd[1]/div[2]/input').clear()driver.find_element_by_xpath('//*[@id="gradetxt"]/dd[3]/div[2]/input').clear()time.sleep(1)# 获取内容并返回数量列表
def getData_and_print(driver,tw,dp):cntDict={}for index in range(1,13):try:text1=driver.find_element_by_xpath('//*[@id="divGroup"]/dl[3]/dd/div/ul/li['+str(index)+']').textcntDict[text1[:4]]=text1[5:-1]except:continue for i in years:if i not in cntDict.keys():cntDict[i]='0' cnttuplelist=[]cntlist=[]for i in sorted (cntDict,reverse=False): if int(i)>=2011 and int(i)<=2018:cnttuplelist.append((i, cntDict[i]))cntlist.append(cntDict[i]) else:continuefor ct1,ct2 in cnttuplelist:print(dp+'\t\t\t'+ct1+'\t'+tw+'\t\t'+ct2) return cntlist #加载并将数据写入excel指定位置
def load_into_excel(datalist,indexi,indexj):wb=openpyxl.load_workbook('data.xlsx')ws=wb['Sheet1']for i in range(len(datalist)):ws.cell(row=i+8*indexi+2,column=4+indexj).value=datalist[i] wb.save("data.xlsx")#主函数
if __name__ =='__main__':driver=openUrl('https://kns.cnki.net/kns8/AdvSearch?dbprefix=CFLS&&crossDbcodes=CJFQ%2CCDMD%2CCIPD%2CCCND%2CCISD%2CSNAD%2CBDZK%2CCCJD%2CCCVD%2CCJFN')onceClick(driver)flag=Truefor indexi,dp in enumerate(dailyPapers):#报纸为行for indexj,tw in enumerate(topicWords):#关键词为列send_and_click(driver,tw,dp,flag)flag=False #运行第一次后,标记flag为Falsecntlist=getData_and_print(driver,tw,dp)load_into_excel(cntlist,indexi,indexj)driver.close()
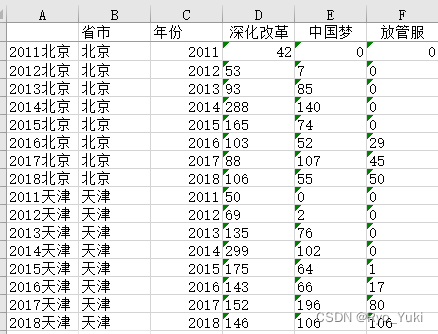
结果预览
控制台
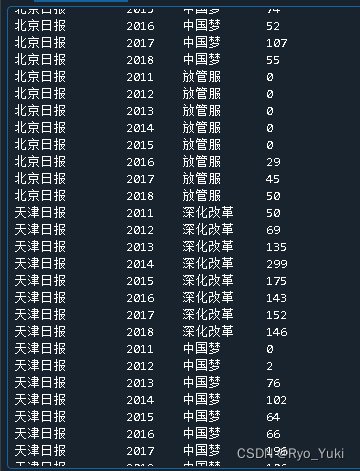
文件
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!