泣血之作: 安装kube-prometheus堆栈报错,无法执行kubectl top node,prometheus监控指标重复
安装kube-prometheus堆栈的时候遇到一个错误,排查了很久:
起初问题表象是无法执行Kubectl top node ,显示api not available类似的信息,然而执行kubectl top pod却可以显示资源占用信息。根据这个问题排查了很久,因为会有很多原因导致这个问题,后来暂时忽略这个问题。
当把prometheus接入grafana时,在执行查询语句:
container_memory_working_set_bytes{container!=“”,node!=“”}
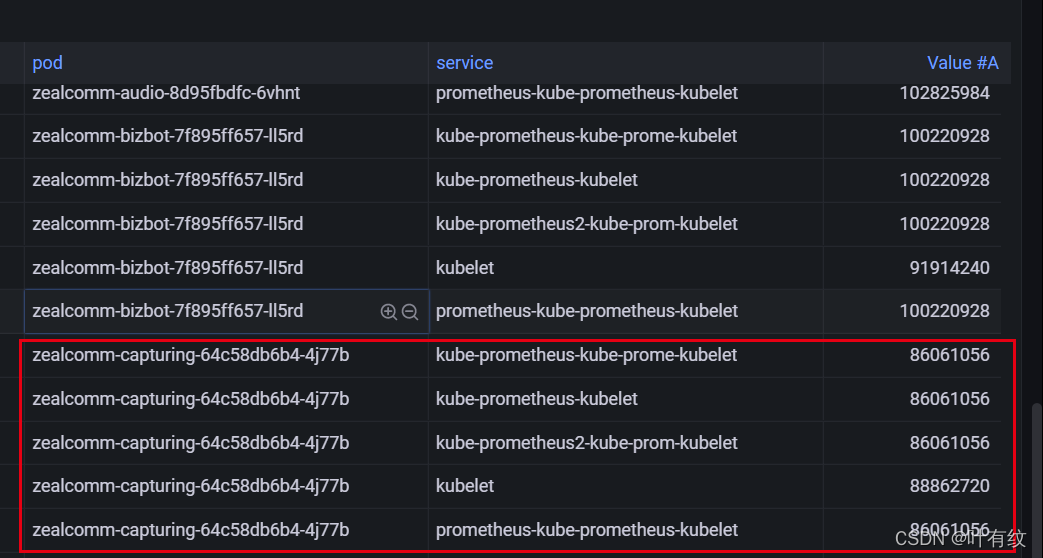
发现同一个容器内存占用竟然有多个重复的指标,如果做内存占用监控,这样肯定是不准确的。
根据图中内存的service的名字,大致猜想这个集群安装卸载prometheus很多次,应该是有残留了什么东西没删除干净。但是得知之前安装过prometheus的namespace都删除了。
使用以下命令查找出所有prometheus相关的service:
kubectl get svc -A|grep prometheus
发现kube-system有残留的promehtheus的service:
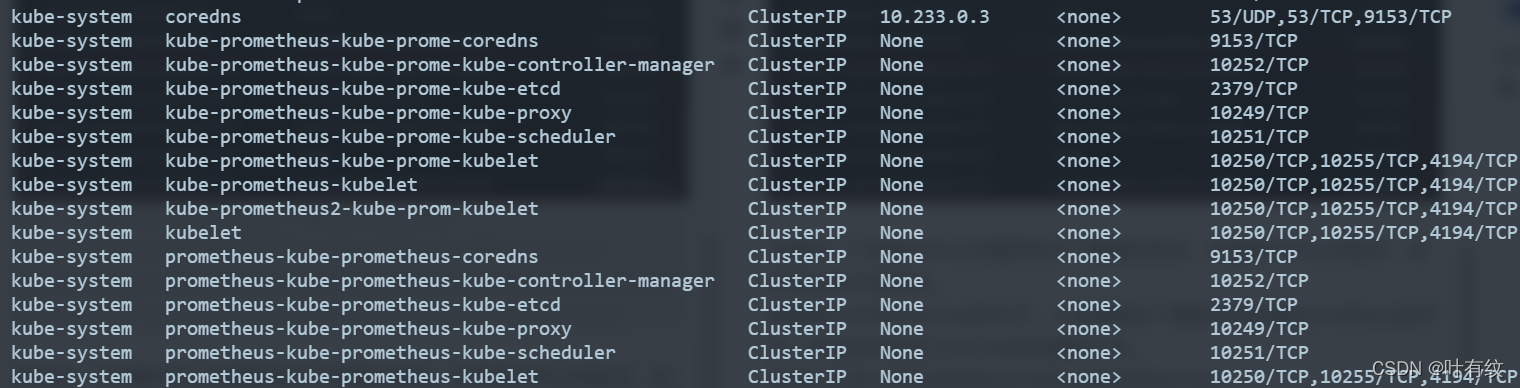
干净的集群,Kube-system一般只有coredns和kubelet两个service,残留的prometheus相关的service直接删除即可。
不过到这里还是没有彻底解决问题。继续执行以下命令把所有prometheus相关的残留找出来:
kubectl get service -A |grep prometheus
kubectl get crd -A |grep monitoring
kubectl get mutatingwebhookconfigurations -A |grep prometheus
kubectl get validatingwebhookconfigurations -A |grep prometheus
删除后重新建立kube-prometheus堆栈即可
对Kubernetes感兴趣的朋友可以+我入群一起讨论(备注: k8s)

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!