VDSR
针对论文 Accurate Image Super-Resolution Using Very Deep Convolutional Networks 的理解
1. Introduction
指出论文中需要解决的问题 SISR, 介绍传统的方法和目前使用较多的方法,简单分析了SRCNN的优势(和其他方法的比较),同时指出SRCNN的不足指出(三点:first, it relies on the context of small image regions; second, training converges too slowly; third, the network only works for a single scale)。
从三个方面(对应上面三个问题)来概括论文中的创新点:Context(增大感受野), Convergence(残差学习和高学习率) Scale Factor(使用mutil-scale)
总结论文的贡献
2. Related Work
从三个方面详细分析性论文中提出的模型与SRCNN的不同之处, model, train, scale
model:
SRCNN: filter 9*9 1*1 5*5 , patch extraction/representation, non-linear mapping and reconstruction
13*13(image size)
VDSR: 20 weight layers(3*3)
41 * 41 (image size) 感受野变大
training:
分析SRCNN训练速度慢的原因,并提出VDSR的改进之处
论文中分析认为:SR在HR空间建模,HR 图片可以分解为高频信息和低频信息,输入和输出的图片享有相同的低频信息,SRCNN 把输入传递到末端,构建残差,这与自动编码的概念类似,在自动编码上会消耗训练时间,论文中提出直接对残差进行建模,加快收敛速度。(对SRCNN收敛速度的分析有点牵强) 主要是提出了论文的基于残差建模
scale:
需要结合代码分析坐着是如何实现 一个网络一次训练完成多个scale
3. Proposed Method
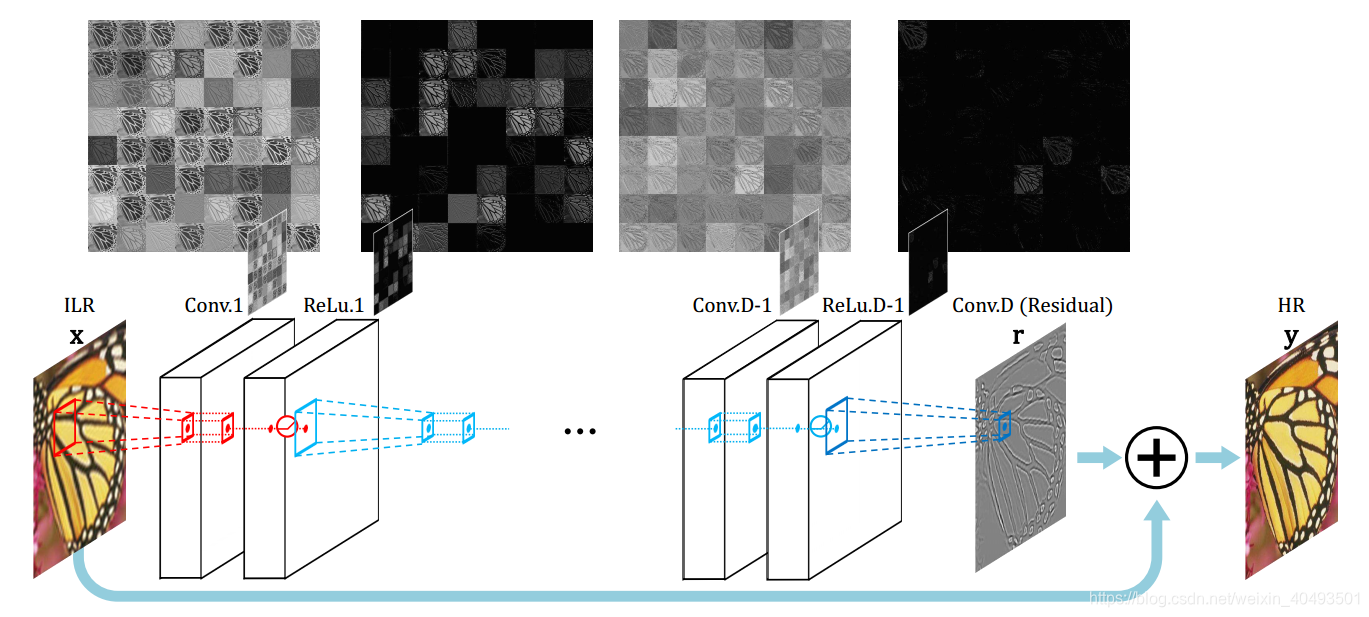
3.1、 提出网络结构
1) 20层的卷积核大小都为3*3*64,
2)使用插值将LR图片放大到期望的尺寸,再作为网络的输入
3)每经过一层,feature map将会变小,论文只用补0 的方法来保持其尺寸不变。
3.2、训练
1)残差学习: 给出残差学习的损失函数,如何利用残差重构图片
2)更高的学习率,结合其他人的实验说明(SRCNN没有更好的收敛,学习率太小是一个重要的原因,)
3) 可调节的梯度裁剪 For maximal speed of convergence, we clip the gradients to [-θ ,θ], where γ denotes the current learning rate. We find the adjustable gradient clipping makes our convergence procedure extremely fast. Our 20-layer network training is done within 4 hours whereas 3-layer SRCNN takes several days to train
4) Mutil-scale 【论文中只提到将训练数据集融合】 Training a multi-scale model is straightforward. Training datasets for several specified scales are combined into one big dataset。
【数据集准备,在对原始数据进行划分时候 no overlap】
4. Understanding Properties
从三个方面,结合训练数据分析模型的优越性
4.1. The Deeper, the Better
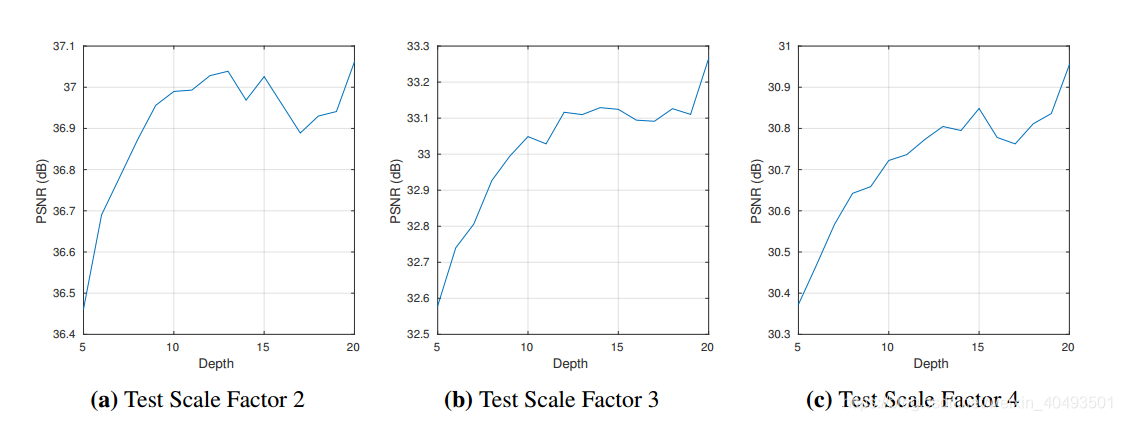
网络从5层增加到 10层
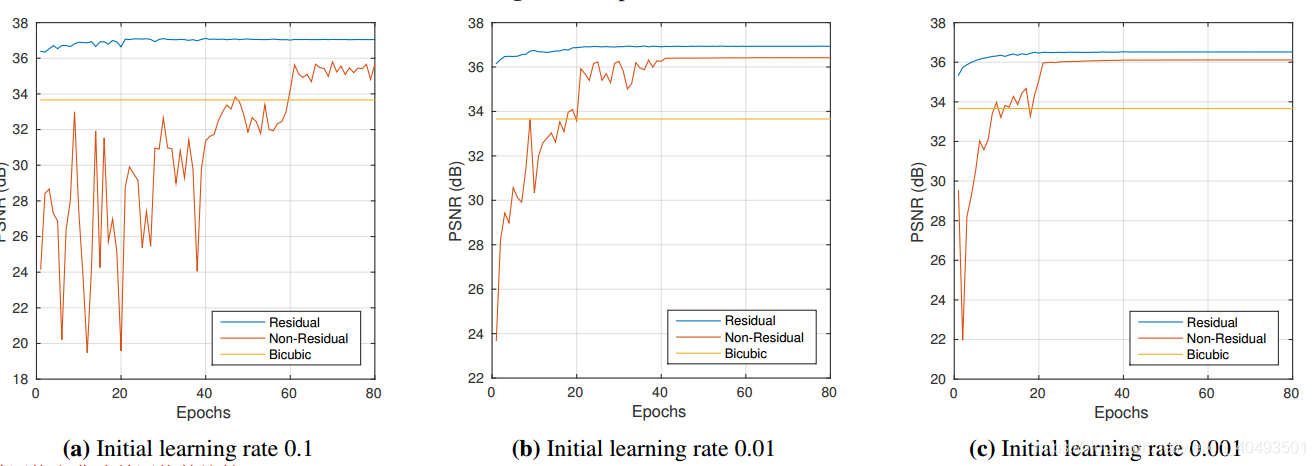
4.2. Residual-Learning
对残差网络,非残差网络,插值 的收敛速度进行对比(用学习epoch和PSNR的关系来看收敛速度)
4.3 Single Model for Multiple Scales
文章中没有说明如何设置的更多细节,用不同的scale 进行了测试和对比,
第一测试了一个a single scale factor模型,用其他scale做测试,结论是A network trained over single-scale
data is not capable of handling other scales. In many tests, it is even worse than bicubic interpolation, the method used
for generating the input image.(基于a single scale factor)
第二个测试了一个scale augmentation 的模型,以及实验结果的描述
5. Experimental Results
训练和测试的数据集
use 291 images (没有overlap,如果用91张图片得到的训练集比较少)
data augmentation (rotation or flip) is used
测试集 Set5 Set14 Dataset ‘Urban100’ dataset ‘B100’
训练参数
20层 3*3*64 momentum=0.9 weight decay parameters=0.0001
We train all experiments over 80 epochs (9960 iterations with batch size 64).
Learning rate was initially set to 0.1 and then decreased by a factor of 10 every 20 epochs.(学习率随步骤变化)
Benchmark
比较
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!