纯Python实现:函数求导切线图、求偏导、梯度下降法(4)
记录鱼书4:
1.y = 0.01x2 + 0.1x经过某点画切线图(微分)
import numpy as np
import matplotlib.pyplot as plt
def numerical_diff(f,x):h=1e-4return (f(x+h)-f(x-h))/(2*h)def fun1(b):return 0.01*b**2+0.1*bdef tangent_line(f,x):#d就是调用numerical_diff求得在x点的导数d=numerical_diff(f,x)#这里直接y=kx+b求截距的,简单粗暴,y就是截距y=f(x)-d*x#使用lambda匿名函数,t是形参,“:”后是要执行的函数表达式return lambda t:d*t+yx=np.arange(0.0,20.0,0.1)
y=fun1(x)
plt.xlabel("x")
plt.ylabel("f(x)")
#把函数作为形参时i,传入实参函数时,只要函数名即可,不用()
tf=tangent_line(fun1,10)
#因为tf返回的是lambda函数,所有要多调一次函数
y2=tf(x)
plt.plot(x,y)
plt.plot(x,y2)
plt.show()结果:
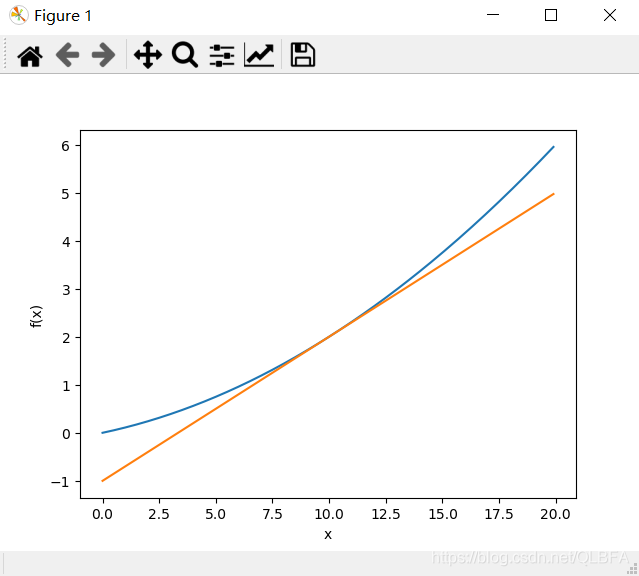
一元用上面的微分即可,二元用偏导数,见下
2.对f(x0,x1)=xo2+x12求梯度(偏导数)(求梯度就是求各权值偏导汇总)
梯度表示的是各点处的函数值减小最多的方向。因此,
无法保证梯度所指的方向就是函数的最小值或者真正应该前进的方向。实际
上,在复杂的函数中,梯度指示的方向基本上都不是函数值最小处。

import numpy as np
import matplotlib.pyplot as plt
#函数f(x0,x1)=xo**2+x1**2
def fun2(x):return x[0]**2+x[1]**2#该函数对NumPy数组x的各个元素求数值微分。
def numerical_gradient(f,x):h=1e-4#grad初始化为0的arraygrad=np.zeros_like(x)for idx in range(x.size):#获得输入array的值tmp_val=x[idx]#f(x+h)的计算x[idx]=tmp_val+h#加0.0001后的x带入上面的fun2得到的值eg:25.00060001fxh1=f(x)#f(x-h)的计算x[idx]=tmp_val-hfxh2=f(x)#计算分别两个值的微分,合起来(全部变量)就是grad[]向量就是梯度了grad[idx]=(fxh1-fxh2)/(2*h)x[idx]=tmp_val #还原值,因为前面-h,不然由于for循环保留了前一个的值,会影响结果的return gradprint(numerical_gradient(fun2,np.array([3.0,4.0])))
print(numerical_gradient(fun2,np.array([0.0,2.0])))
输出:
[6. 8.]
[0. 4.]
3.梯度下降法(求梯度就是求各权值偏导汇总)

式(4.7)的η表示更新量,在神经网络的学习中,称为学习率(learning rate)。学习率决定在一次学习中,应该学习多少,以及在多大程度上更新参数。
式(4.7)是表示更新一次的式子,这个步骤会反复执行。也就是说,每一步都按式(4.7)更新变量的值,通过反复执行此步骤,逐渐减小函数值。虽然这里只展示了有两个变量时的更新过程,但是即便增加变量的数量,也可以通过类似的式子(各个变量的偏导数)进行更新。
学习率需要事先确定为某个值,比如0.01或0.001。一般而言,这个值过大或过小,都无法抵达一个“好的位置”。在神经网络的学习中,一般会一边改变学习率的值,一边确认学习是否正确进行了。
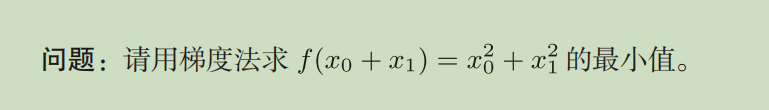
代码:
import numpy as np
import matplotlib.pyplot as plt
#函数f(x0,x1)=xo**2+x1**2
def fun2(x):return x[0]**2+x[1]**2#该函数对NumPy数组x的各个元素求数值微分。
def numerical_gradient(f,x):h=1e-4#grad初始化为0的arraygrad=np.zeros_like(x)for idx in range(x.size):#获得输入array的值tmp_val=x[idx]#f(x+h)的计算x[idx]=tmp_val+h#加0.0001后的x带入上面的fun2得到的值eg:25.00060001fxh1=f(x)#f(x-h)的计算x[idx]=tmp_val-hfxh2=f(x)#计算分别两个值的微分,合起来(全部变量)就是grad[]向量就是梯度了grad[idx]=(fxh1-fxh2)/(2*h)x[idx]=tmp_val #还原值,因为前面-h,不然由于for循环保留了前一个的值,会影响结果的return grad
def gradient_descent(f,init_x,lr=0.01,step_num=100):x=init_xfor i in range(step_num):#numerical_gradient(f,x)会求函数的#梯度,用该梯度乘以学习率得到的值进行更新操作,由step_num指定重复的次数。grad=numerical_gradient(f,x)x-=lr*gradreturn x
init_x=np.array([-3.0,4.0])
print(gradient_descent(fun2,init_x,0.1,100))
输出:[-6.11110793e-10 8.14814391e-10]
这里是输出的是x0,x1的最小值(在这个学习率(超参数)和步,用不同的值)
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!