基于fbprophet的模型预测世界新冠肺炎确诊人数
基于fbprophet的模型预测世界新冠肺炎确诊人数
文章目录
- 基于fbprophet的模型预测世界新冠肺炎确诊人数
- 前言
- 一、fbprophet模型简介
- 使用fbprophet预测有以下好处:
- 二、Prophet安装
- 第一步:安装PyStan
- 第二步:安装fbprophet
- 第三步:解决方案:
- 三、Prophet的使用
- 1.使用的数据
- 2.处理数据
- 3.初步预测
- 4.调整模型
- 5.结果:
- 四、源码:
- 五、总结
前言
随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,一次偶然的机会学习了fbprophet时序预测模型,就决定使用这个框架来进行未来5天的确诊人数的预测。但是传染病模型比较复杂,此次使用此模型来预测,仅仅是用来练习,结果仅供参考。
提示:以下是本篇文章正文内容,下面案例可供参考
一、fbprophet模型简介
1.相对于传统的时间序列预测方法,例如:ARIMA(autoregressive integrated moving average)模型,在R与Python中都有实现。虽然这些传统方法已经用在很多场景中了,但它们通常有如下缺陷:
a.适用的时间序列过于局限
例如最通用的ARIMA模型,其要求时序数据是稳定的,或者通过差分化后是稳定的,且在差分运算时提取的是固定周期的信息。这往往很难符合现实数据的情况。
b.缺失值需要填补
对于数据中存在缺失值的情况,传统的方法都需要先进行缺失值填补,这很大程度上损害了数据的可靠性。
c.模型缺乏灵活性
传统模型仅在于构建数据中的临时依赖关系,这种模型过于不够灵活,很难让使用者引入问题的背景知识,或者一些有用的假设。
d.指导作用较弱
当前,虽然R与Python中实现了这些方法并提供了可视化效果,降低了模型的使用门槛。但由于模型本身的原因,这些展现的结果也很难让使用者更清楚地分析影响预测准确率的潜在原因。
总之,传统的时间序列预测在模型的准确率以及与使用者之间的互动上很难达到理想的融合。
使用fbprophet预测有以下好处:
-
这个模型上手非常容易,即便是很一般的数据分析师也能够做一个比较精准的预测。
-
该模型只需要设置基本配置,并传入指定格式的数据,就可以完成数据的预测。 整体框架分为Modeling、Forecast
-
Evaluation、Surface Problems以及Visually Inspect Forecasts这四个部分。
-
模型有三部分组成,增长趋势,季节趋势,节假日影响。
更多关于这个模型的介绍,请自行前往:
腾讯技术工程 | 基于Prophet的时间序列预测
二、Prophet安装
第一步:安装PyStan
fbprophet依赖于PyStan,所以首先要安装PyStan库。我用的是Anaconda
pip install pystan
我没安装C++编译器,直接pip也可以success。
第二步:安装fbprophet
如果还像安装PyStan直接输入pip install fbprophet,会报错,即找不到DLL。
从官网上下载后,解压后,通过python setup.py install. 结果也是python运行也出错,报相同的错。
所以,按照网上的二部走失败了。
第三步:解决方案:
conda install -c conda-forge fbprophet
如果提醒我需要更新conda,就输入命令:
conda update -n base -c defaults conda
更新完conda后,再输入:
conda install -c conda-forge fbprophet
这样就安装成功。

三、Prophet的使用
1.使用的数据
我所使用的数据是世界从2020年1月28日到2020年12月3日的确诊人数数据【数据下载】(提取码:7anj ):
也可以访问我写的爬虫代码:python爬虫腾讯疫情
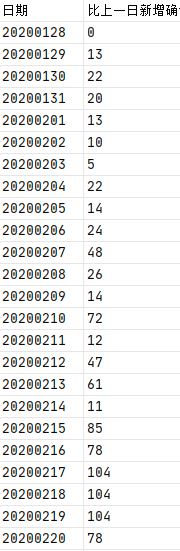
根据官网的描述,只要用 csv 文件存储两列就行,第一列的名字是 ‘ds’, 第二列的名称是 ‘y’。第一列表示时间序列的时间,第二列表示时间序列的取值。所以这里我们可以手动在文件中更改列名,也可以在程序中改。这里我们使用后者方法。
2.处理数据
import pandas as pd
import pystan
from fbprophet import Prophet
import matplotlib.pyplot as plt#数据导入
pdata = pd.read_csv("./预测数据源/FAutoGlobalDailyList预测国际新增确诊数据源.csv", encoding='gbk')
#只要最近50天的数据
pdata = pdata.iloc[-50:]
#把列名 日期 比上一日新增确诊人数 改成 ds y
pdata.rename(columns={'日期': 'ds', '比上一日新增确诊人数': 'y'}, inplace=True)
#把ds的str格式改成datetime格式
pdata['ds'] = pd.to_datetime(pdata['ds'], format='%Y%m%d')
我们将列名修改成了官方要求的’ds’和’y’,其次我们将’ds‘的格式修改成了datatime时间格式。
3.初步预测
#创建一个模型mode = Prophet()#传入模型需要预测的数据mode.fit(div_list)#创建一个包含预测时间的dataFrame,单位默认为天future = mode.make_future_dataframe(periods=5)#进行预测,返回预测值及其其他相关值,格式为dataframe.forecast = mode.predict(future)#画图mode.plot(forecast)#显示图片plt.show()#输出预测的5天的值test = forecast[['ds', 'yhat']].tail(5)print(test[-5:])print(test['ds'].astype(str).values.tolist())print(test['yhat'].astype(int).values.tolist())结果图:
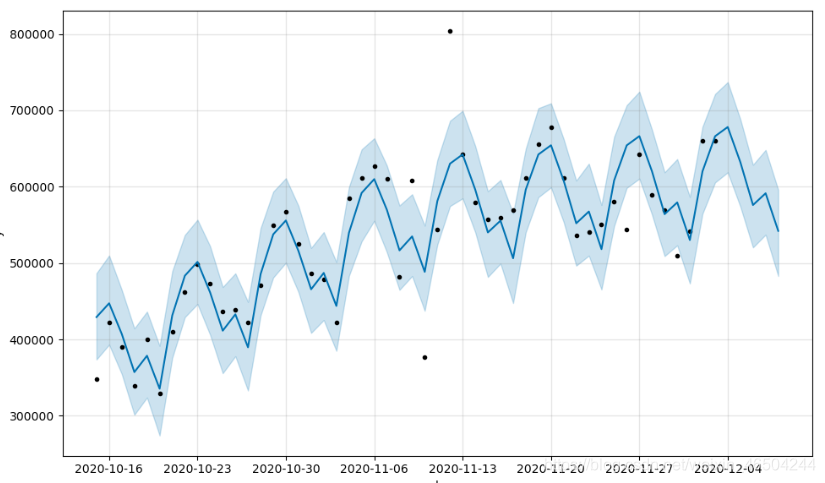
图中,黑色的点是我们文件中的数据,也就是确诊人数,中间深蓝色的线就是我们预测的曲线,曲线轮廓的上下边界有浅蓝色区域,它表示模型预测值的上、下边界。
这个结果肯定不能让我们满意,好了,我们来调整一下模型。
4.调整模型
模型可以调整的参数(prophet()中的参数):
prophet()有两种模式,第一种是线性’linear‘,第二种是逻辑回归(非线性)‘logistic’。默认是线性的。注意 若使用后者,需要添加cap 进行容量值设置。
changepoints( prophet()模型中的):改变点。使用者可以自主填写已知时刻的标示着增长率发生改变的”改变点。默认是0.05
changepoint_prior_scale( prophet()模型中的):增长趋势模型的灵活度。值越大,曲线拟合就越灵活,过大也会出现过拟合的情况
holidays 节假日定义,holidays_prior_scale节假日对模型的影响,值越大,影响程度越大,默认值是10。holidays格式第一个参数是节假日名字,这个一般都自己写; 第二个是你指定哪些日子为假期;第三个lower_window 是前面你设定的节假期前几天;第四个upper_window是节假日后几天。
seasonality_prior_scale 调节季节的影响程度默认值是10
第一步:首先将模式改为逻辑回归(非线性),注意容量值的设置。
#创建一个模型mode = Prophet(growth='logistic')#容器值得设置div_list['cap'] = 600000#传入模型需要预测的数据mode.fit(div_list)#创建一个包含预测时间的dataFrame,单位默认为天future = mode.make_future_dataframe(periods=5)#容器值得设置future['cap'] = 600000第二步:再修改一下增长趋势拟合度,这个值默认是0.05,咱们修改为2
mode = Prophet(growth='logistic',changepoint_prior_scale=2)
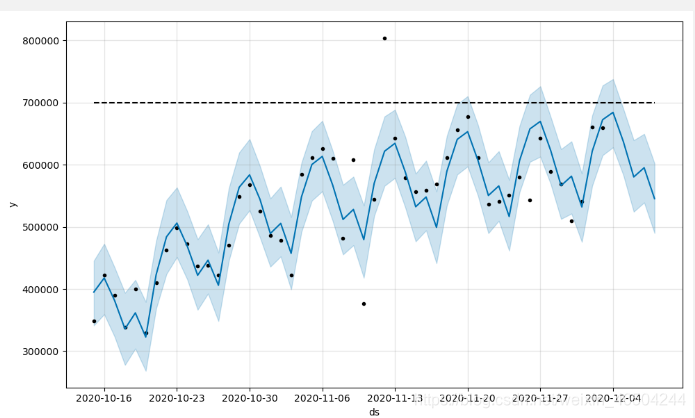
第三步:设置固定得改变点,使得图片拟合没有发生什么变化,试一试
mode = Prophet(growth='logistic',changepoint_prior_scale=2,changepoints['2020-10-31'])
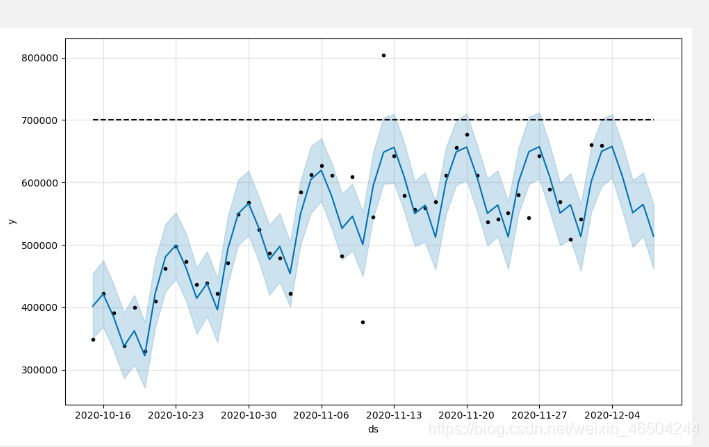
这里需要注意,changepoint_prior_scale值过大会出现过拟合的情况,所以需要你多去尝试,寻找合适的值。
5.结果:
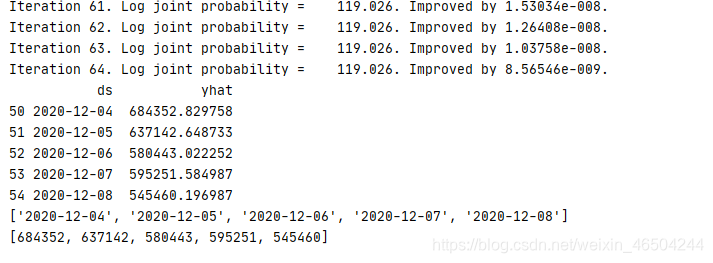
四、源码:
#数据导入div_list = pd.read_csv("./预测数据源/FAutoGlobalDailyList预测国际新增确诊数据源.csv", encoding='gbk')#只要最近50天的数据div_list = div_list.iloc[-50:]# print(pdata)#把列名 日期 比上一日新增确诊人数 改成 ds ydiv_list.rename(columns={'日期': 'ds', '比上一日新增确诊人数': 'y'}, inplace=True)#把ds的str格式改成datetime格式div_list['ds'] = pd.to_datetime(div_list['ds'], format='%Y%m%d')#创建一个模型mode = Prophet(growth='logistic',changepoint_prior_scale=2,changepoints=['2020-10-31'])#容器值得设置div_list['cap'] = 700000#传入模型需要预测的数据mode.fit(div_list)#创建一个包含预测时间的dataFrame,单位默认为天future = mode.make_future_dataframe(periods=5)#容器值得设置future['cap'] = 700000#进行预测,返回预测值及其其他相关值,格式为dataframe.forecast = mode.predict(future)#画图mode.plot(forecast)#显示图片plt.show()#输出预测的5天的值test = forecast[['ds', 'yhat']].tail(5)print(test[-5:])print(test['ds'].astype(str).values.tolist())print(test['yhat'].astype(int).values.tolist())五、总结
- 新型冠状病毒传染模型比较复杂,涉及到多种模型,这里只是使用这个模型做一下简单的预测。目的是学习此模型。
- 上文我只是添加了一个改变点,大家在地下尝试的时候可以添加假期和假期影响程度。
- 以后有机会学习到传染病传播相关模型,再来对这模型进行结合。
参考文章:
Facebook 时间序列预测算法 Prophet的研究
腾讯技术工程 | 基于Prophet的时间序列预测
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!