一行字实现3D换脸!UC伯克利提出「Chat-NeRF」,大片级渲染
来源:新智元
由于神经3D重建技术的发展,捕获真实世界3D场景的特征表示从未如此简单。
然而,在此之上的3D场景编辑却一直未能有一个简单有效的方案。
最近,来自UC伯克利的研究人员基于此前的工作InstructPix2Pix,提出了一种使用文本指令编辑NeRF场景的方法——Instruct-NeRF2NeRF。

论文地址:https://arxiv.org/abs/2303.12789
利用Instruct-NeRF2NeRF,我们只需一句话,就能编辑大规模的现实世界场景,并且比以前的工作更真实、更有针对性。
比如,想要他有胡子,脸上就会出现一簇胡子!

或者直接换头,秒变成爱因斯坦。

此外,由于模型能不断地使用新的编辑过的图像更新数据集,所以场景的重建效果也会逐步得到改善。
NeRF + InstructPix2Pix = Instruct-NeRF2NeRF
具体来说,人类需要给定输入图像,以及告诉模型要做什么的书面指令,随后模型就会遵循这些指令来编辑图像。
实现步骤如下:
在训练视角下从场景中渲染出一张图像。
使用InstructPix2Pix模型根据全局文本指令对该图像进行编辑。
用编辑后的图像替换训练数据集中的原始图像。
NeRF模型按照往常继续进行训练。

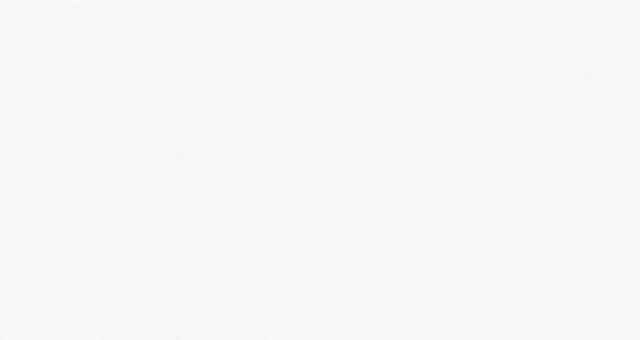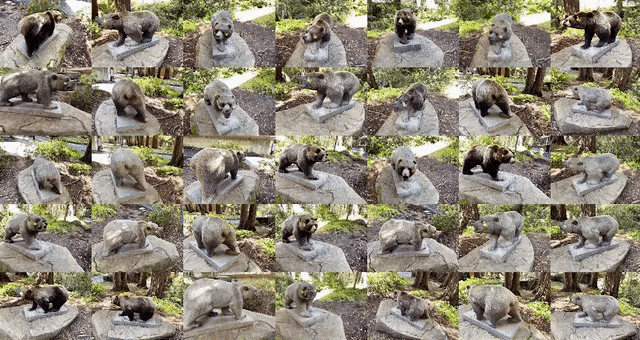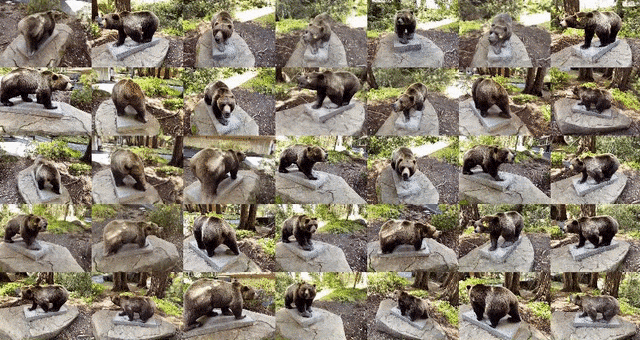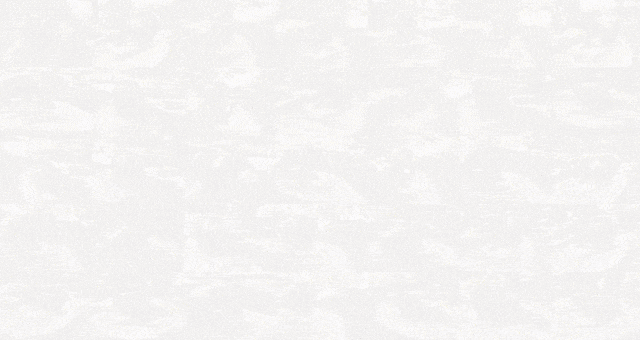
实现方法
相比于传统的三维编辑,NeRF2NeRF是一种新的三维场景编辑方法,其最大的亮点在于采用了「迭代数据集更新」技术。
虽然是在3D场景上进行编辑,但论文中使用2D而不是3D扩散模型来提取形式和外观先验,因为用于训练3D生成模型的数据非常有限。
这个2D扩散模型,就是该研究团队不久前开发的InstructPix2Pix——一款基于指令文本的2D图像编辑模型,输入图像和文本指令,它就能输出编辑后的图像。
然而,这种2D模型会导致场景不同角度的变化不均匀,因此,「迭代数据集更新」应运而生,该技术交替修改NeRF的「输入图片数据集」,并更新基础3D表征。
这意味着文本引导扩散模型(InstructPix2Pix)将根据指令生成新的图像变化,并将这些新图像用作NeRF模型训练的输入。因此,重建的三维场景将基于新的文本引导编辑。
在初始迭代中,InstructPix2Pix通常不能在不同视角下执行一致的编辑,然而,在NeRF重新渲染和更新的过程中,它们将会收敛于一个全局一致的场景。
总结而言,NeRF2NeRF方法通过迭代地更新图像内容,并将这些更新后的内容整合到三维场景中,从而提高了3D场景的编辑效率,还保持了场景的连贯性和真实感。

可以说,UC伯克利研究团队的此项工作是此前InstructPix2Pix的延伸版,通过将NeRF与InstructPix2Pix结合,再配合「迭代数据集更新」,一键编辑照样玩转3D场景!
仍有局限,但瑕不掩瑜
不过,由于Instruct-NeRF2NeRF是基于此前的InstructPix2Pix,因此继承了后者的诸多局限,例如无法进行大规模空间操作。
此外,与DreamFusion一样,Instruct-NeRF2NeRF一次只能在一个视图上使用扩散模型,所以也可能会遇到类似的伪影问题。
下图展示了两种类型的失败案例:
(1)Pix2Pix无法在2D中执行编辑,因此NeRF2NeRF在3D中也失败了;
(2)Pix2Pix在2D中可以完成编辑,但在3D中存在很大的不一致性,因此NeRF2NeRF也没能成功。

再比如下面这只「熊猫」,不仅看起来非常凶悍(作为原型的雕像就很凶),而且毛色多少也有些诡异,眼睛在画面移动时也有明显的「穿模」。

自从ChatGPT,Diffusion, NeRFs被拉进聚光灯之下,这篇文章可谓充分发挥了三者的优势,从「AI一句话作图」进阶到了「AI一句话编辑3D场景」。
尽管方法存在一些局限性,但仍瑕不掩瑜,为三维特征编辑给出了一个简单可行的方案,有望成为NeRF发展的里程碑之作。
一句话编辑3D场景
最后,再看一波作者放出的效果。
不难看出,这款一键PS的3D场景编辑神器,不论是指令理解能力,还是图像真实程度,都比较符合预期,未来也许会成为学术界和网友们把玩的「新宠」,继ChatGPT后打造出一个Chat-NeRFs。


即便是随意改变图像的环境背景、四季特点、天气,给出的新图像也完全符合现实逻辑。
原图:

秋天:

雪天:

沙漠:

暴风雨:

参考资料:
https://instruct-nerf2nerf.github.io
推荐阅读
西电IEEE Fellow团队出品!最新《Transformer视觉表征学习全面综述》
润了!大龄码农从北京到荷兰的躺平生活(文末有福利哟!)
如何做好科研?这份《科研阅读、写作与报告》PPT,手把手教你做科研
奖金675万!3位科学家,斩获“中国诺贝尔奖”!
又一名视觉大牛从大厂离开!阿里达摩院 XR 实验室负责人谭平离职
最新 2022「深度学习视觉注意力 」研究概述,包括50种注意力机制和方法!
【重磅】斯坦福李飞飞《注意力与Transformer》总结,84页ppt开放下载!
2021李宏毅老师最新40节机器学习课程!附课件+视频资料
欢迎大家加入DLer-计算机视觉技术交流群!
大家好,群里会第一时间发布计算机视觉方向的前沿论文解读和交流分享,主要方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如图像分类+上交+小明)

👆 长按识别,邀请您进群!

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!