[State of GPT] OpenAI讲座随笔记
原版:State of GPT
B站翻译版:【精校版】Andrej Karpathy微软Build大会精彩演讲: GPT状态和原理 - 解密OpenAI模型训练
1 GPT Training Pipeline图解
记录一下对这个图的理解:

大模型训练的四个阶段:
- Pretraining 阶段,数据:低质量的大量文本,模型任务:Predict Next Token任务;这个阶段的模型更多是模型补全,不等于问答;最漫长的训练步骤,需要个把月,底层模型的选择与训练代价非常大了
- SFT监督学习 ,Prompt问答对的数据,训练集采集的难度较大
- Reward Modeling反馈式模型,判别式模型
- RL learning 强化学习,在RM基础上继续强化
2 阶段一:Pretraining 阶段
预训练阶段的模型目标是预测下一步,
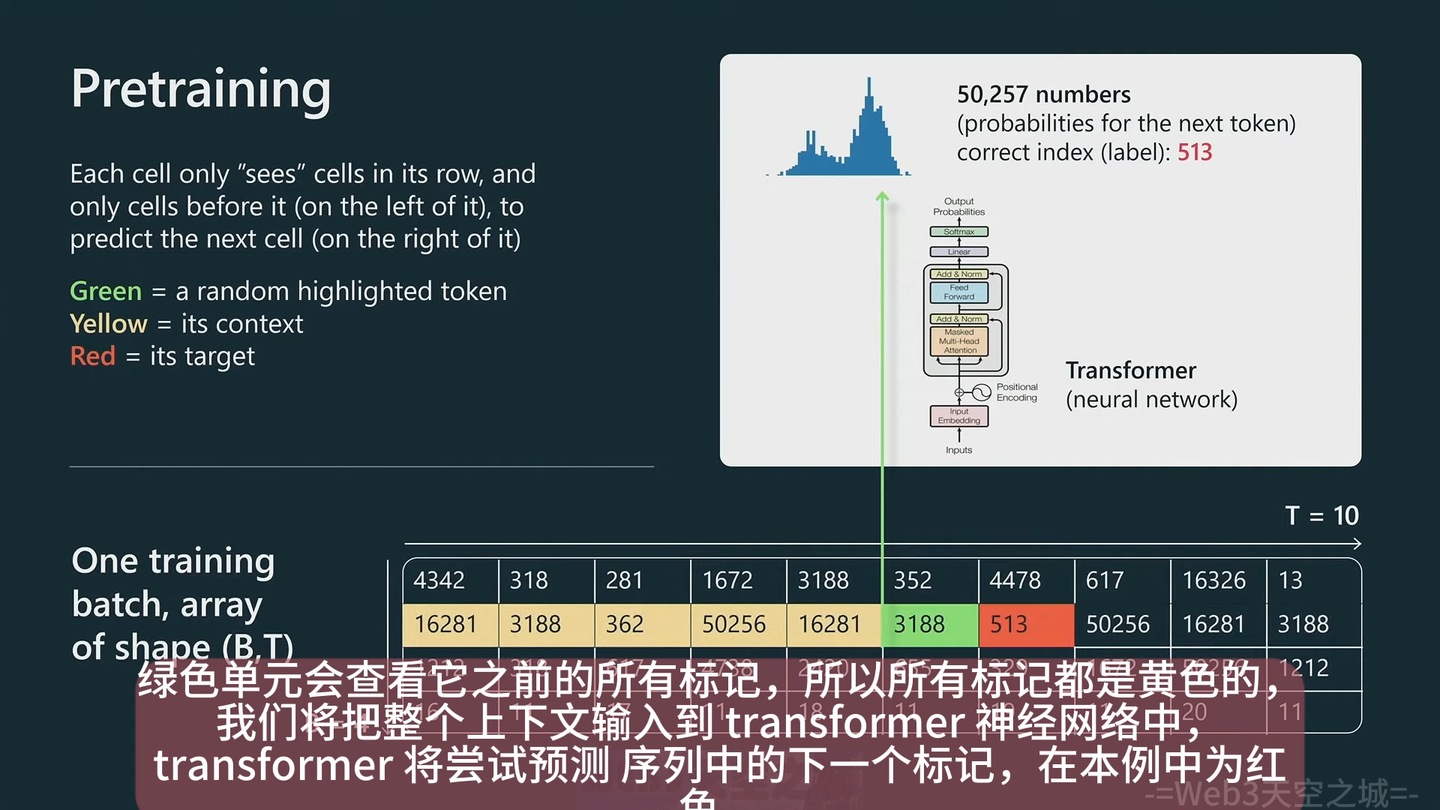
虽然不能跟问答一样,当然可以给一些提示,达到类似回答的效果:

3 阶段二:SFT监督学习
supervised finetuning

prompt 是人类指令,response 是标注员写得针对人类指令的示例回复;
高质量问答:

这个数据集整理难度蛮高,对于标注员来说需要高质量的回答
4 阶段三:Reward Modeling反馈式模型

模型采用的是分类判别式模型,
写一个判断字符串是否是回文字符串的 python 程序,
基于 SFT 模型生成多个回复,比如下面生成了三个回复后让标注员来对生成结果进行排名(排名难度较大,一个 prompt 的答案甚至可能需要几个小时来标注)

5:阶段四: RL learning 强化学习
基于上一步的 RM 模型进行强化学习训练,对于prompt之后补齐的文章进行给分,不太好的就负分,好的给高分
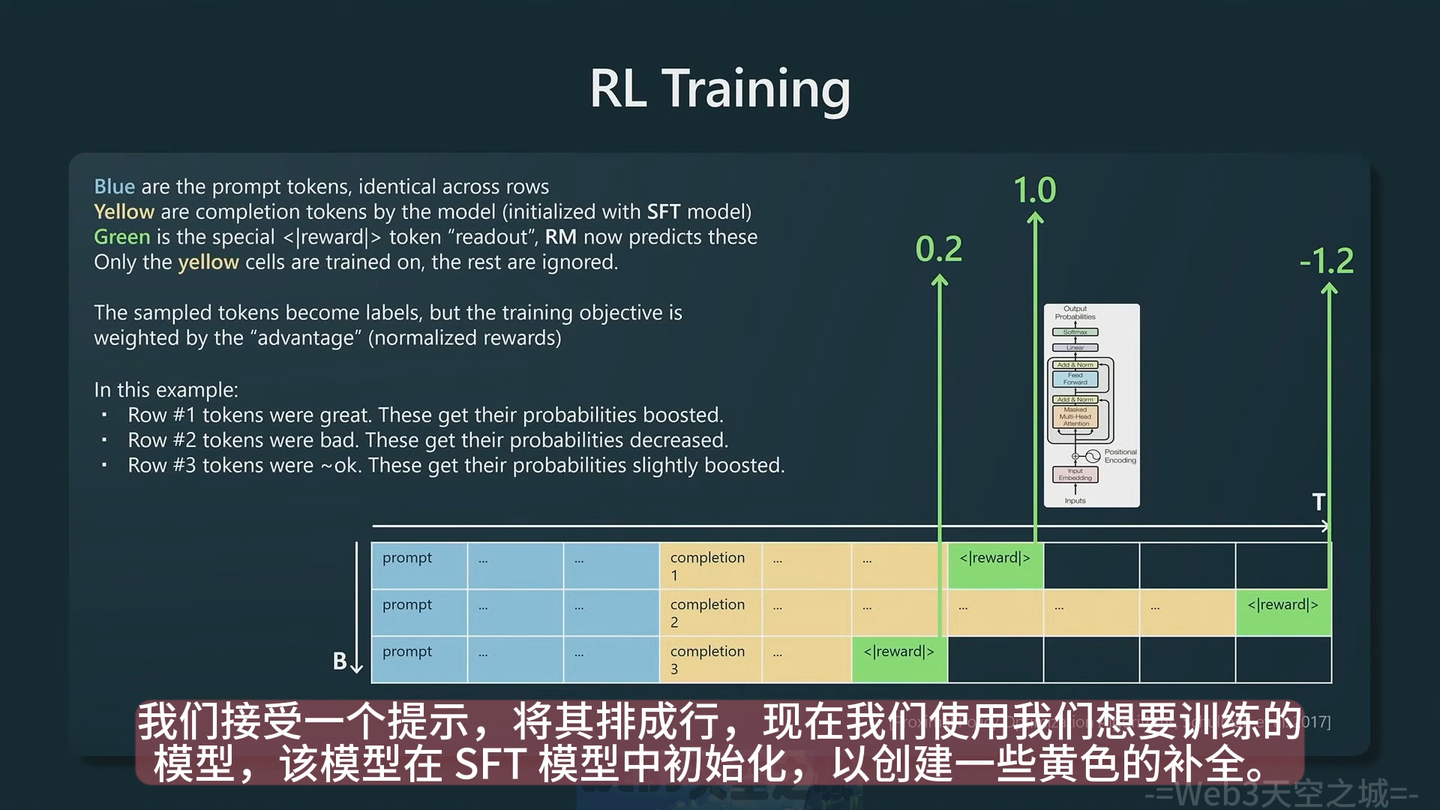
6 一些结论
RLHF强化学习 相关:
- 【阶段三 RM】 与 【阶段四 RL】 都是对结果进行特定的“强化”,不过RLHF 模型效果比较好,所以需要加上
- karpathy 认为 RLHF 有用的原因是判别比生成更容易,让标注员去写一些 SFT 的 QA 数据对是比较难的,如果有一个 SFT 模型生成一些数据让标注员判断哪个更好就简单很多
- RLHF 模型降低了熵,对输出文本的确定性更强,SFT 模型更善于给出有区分度的回答

其他还有: - SFT 相对容易;RLHF 很难,非常不稳定,很难训练,对初学者不友好,而且可能变化快,不推荐一般人来做
7 一些使用建议
讲座还说了一些写prompt的技巧
推理任务的Prompt方式:Chain of thought
两种方式:
- few-shot CoT
就是根据QA给出一些推理逻辑,然后再问下一个问题,相当于有一个例子可以学习一下 - zero-shot-CoT
最简单就是Prompt最后加一句话 【 Let’s think step by step】

答案不满意,多生成几次
如果对答案不满意,可以多生成几次
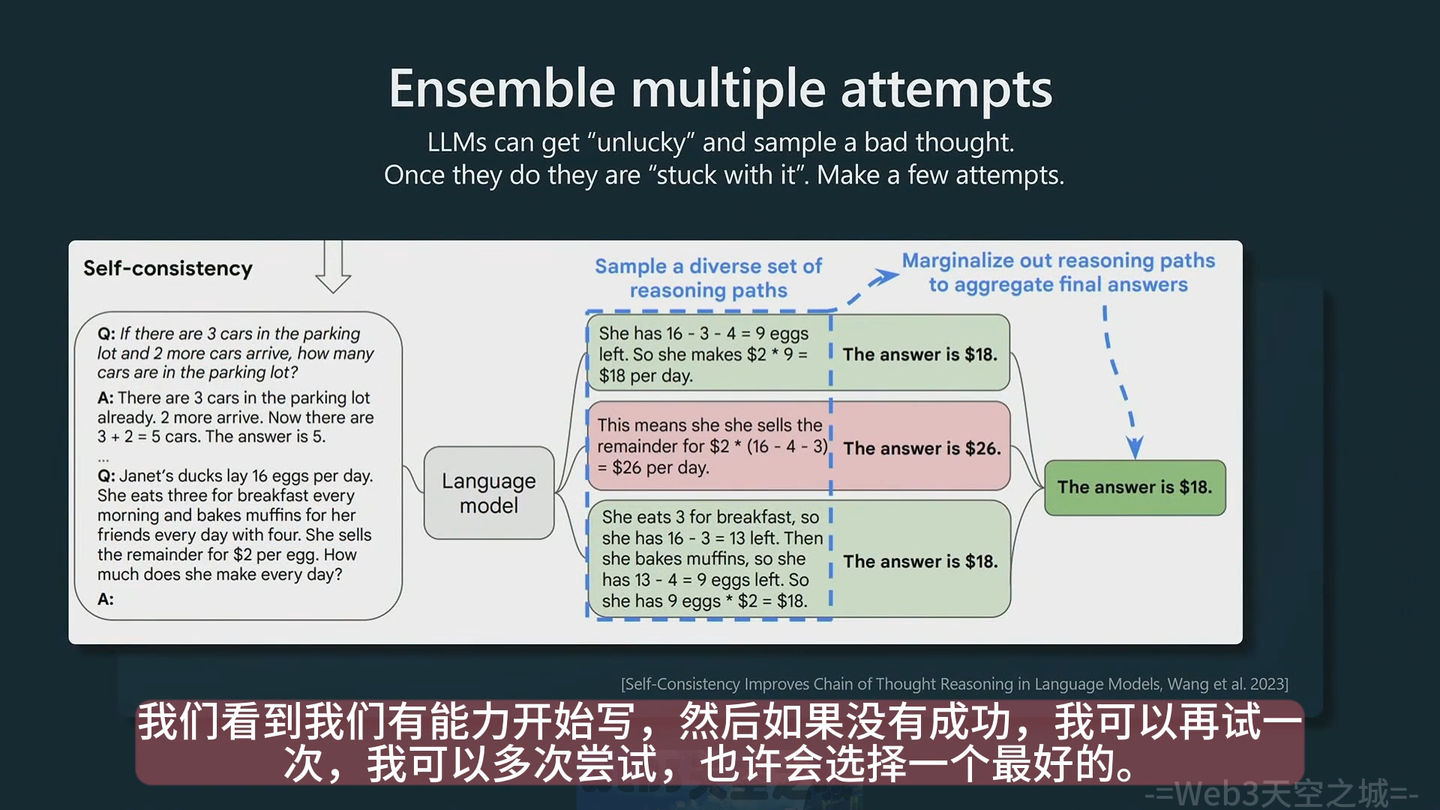
反思答案,模型其实并不管生成的内容是否正确,所以你可以反问他,或者prompt的时候多加一句,让他自己检查


Constrained prompting,按规则模型输入、输出

参考材料:
- State of GPT (OpenAI Karpathy 介绍 ChatGPT 原理及现状)
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!