使用pyecharts对成都java岗位分布做可视化分析——接上篇
上一篇文章详细描写了从某个招聘网站爬取某个岗位的详细过程。这次,将使用python中的pyecharts库做一个入门级分析。获取原始数据。
pyecharts库中包含多种作图方式,这次先使用柱状图按城区分类统计招聘数量。
首先,导入需要使用的类,然后先查看一下前五条数据。
from pyecharts.charts import Bar
from pyecharts import options
import csvwith open('file/java招聘.csv')as f:reader = csv.reader(f)next(reader)for i in range(5):print(next(reader))
['四川格瑞特科技有限公司', 'Java高级开发工程师', '0.8-1.2万/月', "['成都-武侯区', '3-4年经验', '本科', '招若干人']", '2020-09-03 09:27:45', '50-150人']
['成都盛世普益科技有限公司', 'java开发工程师(偏数据方向),年薪7-15万', '6-8千/月', "['成都-青羊区', '2年经验', '本科', '招若干人']", '2020-09-03 09:27:15', '50-150人']
['上海梦创双杨数据科技股份有限公司', 'Java中高级开发工程师-成都', '1-3万/月', "['成都-锦江区', '3-4年经验', '本科', '招20人']", '2020-09-03 09:26:34', '1000-5000人']
['成都一诺非凡广告有限公司', 'Java开发实习生', '6-8千/月', "['成都-武侯区', '无需经验', '大专', '招1人']", '2020-09-03 09:25:07', '150-500人']
['成都爱易佰网络科技有限公司', 'Java架构师(社招)', '1-2.5万/月', "['成都-武侯区', '在校生/应届生', '本科', '招1人']", '2020-09-03 09:23:27', '50-150人']
可以看到,关于位置的信息在列表的第四列的第一个元素里,关于地区的信息在短横线的后面,这里需要做一下数据清洗。首先将没有给出明确地区的数据排除在外。这里需要用到字符串切割和字符串切片操作。
def prepare_data():with open('file/java招聘.csv')as f:reader = csv.reader(f)# 越过表头next(reader)for row in reader:try:new_row = row[3][1:-1].split(',')# print(new_row,type(new_row))# print(new_row[0][1:-1])if new_row[0][1:-1] == '成都' or new_row[0][1:-1] == '异地招聘':passelse:district = new_row[0].split('-')[1][:-1]print(district)except:continue
可以看见数据已经清洗成功了
武侯区
青羊区
锦江区
武侯区
武侯区
然后,创建一个字典来统计每个城区出现的次数,城区名字做键,次数为值。在上面的代码上做补充:
def prepare_data():with open('file/java招聘.csv')as f:reader = csv.reader(f)next(reader)all_district = {}for row in reader:try:new_row = row[3][1:-1].split(',')# print(new_row,type(new_row))# print(new_row[0][1:-1])if new_row[0][1:-1] == '成都' or new_row[0][1:-1] == '异地招聘':passelse:district = new_row[0].split('-')[1][:-1]job_num = all_district.get(district,1)job_num += 1all_district[district] = job_numexcept:continue# print(all_district)return all_district
到此,我们已经完成了数据准备的过程,接下来使用pyecharts作图就可以啦!
{'武侯区': 71, '青羊区': 28, '锦江区': 36, '高新区': 167, '温江区': 7, '双流区': 16, '郫都区': 13, '金牛区': 20, '龙泉驿区': 3, '天府新区': 6, '崇州市': 2, '成华区': 8, '新津县': 2}
由于返回的数据是字典类型,所以使用了列表生成式来将数据转换成列表类型。
def create_bar():# 创建柱状图对象bar = Bar()# 关联数据districts = [key for key in prepare_data().keys()]nums = [value for value in prepare_data().values()]bar.add_xaxis(districts)bar.add_yaxis('招聘量', nums)# 设置图表标题,隐藏图表图例bar.set_global_opts(title_opts=options.TitleOpts(title='成都java招聘城区分布',pos_left='300'),legend_opts=options.LegendOpts(is_show=False))# 制作图表bar.render('图表/成都java招聘分布.html')if __name__ == '__main__':create_bar()
最后,来看一下生成的图表吧!
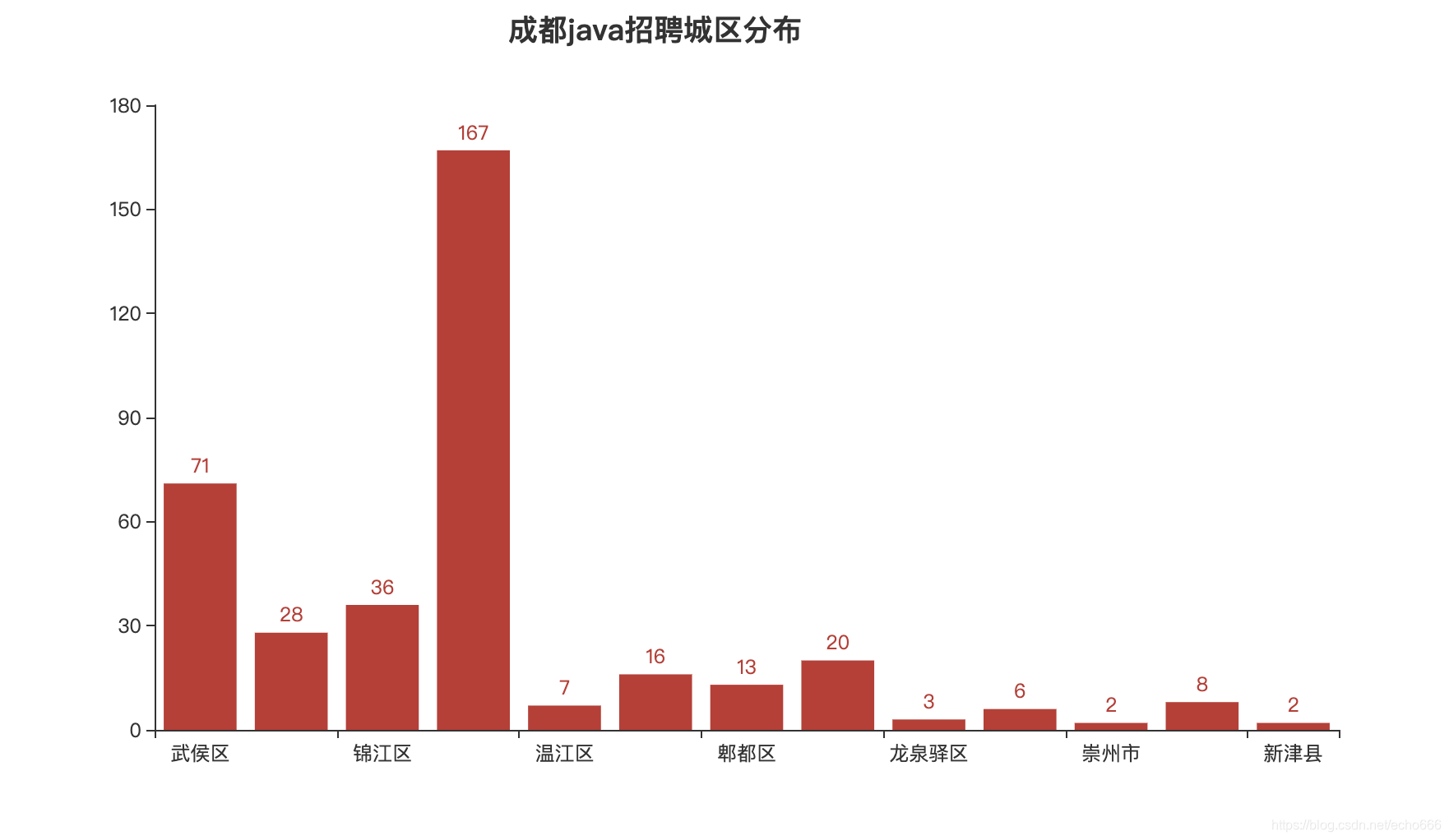
虽然只爬取了前十页数据,排除了无具体位置信息的数据和异地招聘的数据,肉眼可见,高新区一骑绝尘!其次是地理位置紧挨着高新区的武侯区,租房要住在这两个区,上班才方便哦!
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!