Cross-modal Video Moment Retrieval(跨模态视频时刻检索综述)

这个方向的出的文章已经有很多了,但是似乎还没有一个统一一点的名字,叫 时域语言定位(Temporally Language Grounding),或者跨模态视频时刻检索/定位(Cross-modal Video Moment Retrieval/Localization)等等都有。
大概给一个定义就是:给定一句自然语言描述的查询语句query,在未剪裁的完整视频中确定该描述发生的时间片段(起始时间,终止时间),简单来讲如上图,就是用一段文字查询具体的视频片段。它与纯的动作定位任务不同之处在于多了跨模态(文本–视频)的信息。
从2017-目前的博主能找到的所有论文的目录在这里,并简要的给出了简评(持续更新):
- https://github.com/yawenzeng/Awesome-Cross-Modal-Video-Moment-Retrieval
主要方法分类
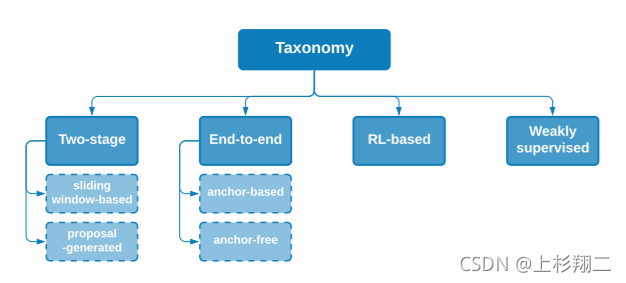
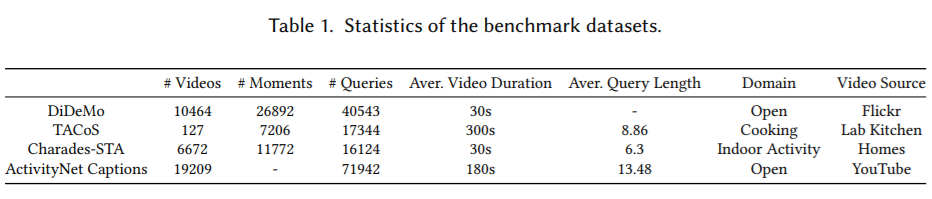
常用数据集
本文从中挑出一些比较重要的,几个角度归类了论文大致为:
- 这个子领域的开山工作:TALL,MCN
- 探索两种模态间,全局局部的各种交互与融合:ROLE,ACRN,ABLR,TGN,SLTA
- 基于强化学习定位边界:READ
- 在强化学习的思路上继续玩语义,局部等等的细化:SM-RL,STRONG
- 针对候选集的优化:MAN,2D-TAN,AVMR
- 内容理解:MMRG
- 弱监督方法
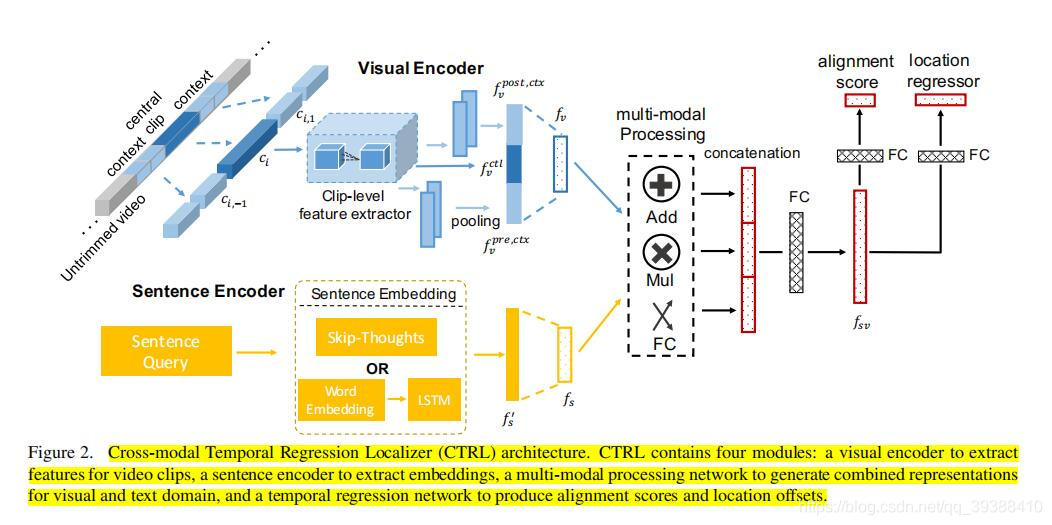
TALL
上图出自ICCV2017,TALL: Temporal Activity Localization via Language Query。是这个方向的开山之作之一,以后的一些工作都是在它的基础上做改进。首先针对这个任务,有两大挑战:
- 作为一个跨模态任务而不是普通的CV或者NLP任务。如何得到适当的文本和视频表示特征,以允许跨模态匹配操作和完成语言查询
- 理论上可以生成无限粒度的视频片段,然后逐一比较是否和查阅语句匹配,但时间消耗过大。那么如何能够从有限粒度的滑动窗口做到准确的具体帧定位
作者提出了跨模态时间回归定位器(CTRL)模型,模型图如上,操作思路为:
- 先对句子描述、候选视频片段及其时间上下文信息抽特征Encoder,分别用sentence2vec和C3D,变成了上面蓝色的视频特征(中心ctl,前一小视频段pre和后post的上下文视频信息)和下面的黄色文本特征。
- 多模态处理。相当于是对多模态进行模态融合,作者分别计算了模态间中不同维度元素的加法、乘法和全连接表示,最后拼接起来。 f s v = ( f s × f v ) ∣ ∣ ( f x + f v ) ∣ ∣ F C ( f s ∣ ∣ f v ) f_{sv}=(f_s \times f_v)||(f_x + f_v)||FC(f_s||f_v) fsv=(fs×fv)∣∣(fx+fv)∣∣FC(fs∣∣fv)
- 最后用FC完成两个任务,即对齐任务和回归任务。对齐任务 L a l n L_{aln} Laln是是句子和视频段的对齐分数,所以实际上会做一个负采样的操作。回归任务 L r e g L_{reg} Lreg是视频帧回归边界,用于对固定滑动窗口补充一个偏差offset提升定位的精度。 L a l n = 1 N ∑ i = 0 N [ α c l o g ( 1 + e x p ( − c s i , i ) ) + ∑ j = 0 , j ≠ i N α w l o g ( 1 + e x p ( c s i , j ) ) ] L_{aln}=\frac{1}{N} \sum^N_{i=0} [\alpha_c log(1+exp(-cs_{i,i}))+\sum^N_{j=0,j≠i} \alpha_w log(1+exp(cs_{i,j}))] Laln=N1i=0∑N[αclog(1+exp(−csi,i))+j=0,j=i∑Nαwlog(1+exp(csi,j))] L r e g = 1 N ∑ i = 0 N [ R ( t x , i ∗ − t x , i ) + R ( t y , i ∗ − t y , i ) ] L_{reg}=\frac{1}{N} \sum^N_{i=0} [R(t^*_{x,i}-t_{x,i})+R(t^*_{y,i}-t_{y,i})] Lreg=N1i=0∑N[R(tx,i∗−tx,i)+R(ty,i∗−ty,i)]
Trick:
- 生成固定大小的侯选了再预测offset。候选使用[64, 128, 256, 512] ,80% 的覆盖率的滑动窗口进行生成。
- 正样本条件:1 .重叠的部分大于0.5。 2 .不重叠的部分小于0.2。 3 .一个滑动窗口只能描述一个句子。
简单看一下开山paper的代码:
class TALL(nn.Module):def __init__(self):super(TALL, self).__init__()self.semantic_size = 1024 # 视觉和文本要投影的共同语义维度self.sentence_embedding_size = 4800 #sentence2vec得到的维度self.visual_feature_dim = 4096*3 #中心+上下文一共3个,每个由C3D得到是4096维self.v2s_lt = nn.Linear(self.visual_feature_dim, self.semantic_size) #投影视觉self.s2s_lt = nn.Linear(self.sentence_embedding_size, self.semantic_size) #投影文本self.fc1 = torch.nn.Conv2d(4096, 1000, kernel_size=1, stride=1)#2层FC得到预测结果self.fc2 = torch.nn.Conv2d(1000, 3, kernel_size=1, stride=1)# 初始化权重self.apply(weights_init)def cross_modal_comb(self, visual_feat, sentence_embed):#这是完成特征交叉的模块,会分别做加法、乘法和拼接batch_size = visual_feat.size(0)# shape_matrix = torch.zeros(batch_size,batch_size,self.semantic_size)#因为视频会有多个,而句子只有一个,所以要做一下维度变化vv_feature = visual_feat.expand([batch_size,batch_size,self.semantic_size])ss_feature = sentence_embed.repeat(1,1,batch_size).view(batch_size,batch_size,self.semantic_size)concat_feature = torch.cat([vv_feature, ss_feature], 2)#横向拼接(第0维度是batch)mul_feature = vv_feature * ss_feature # 56,56,1024,乘法add_feature = vv_feature + ss_feature # 56,56,1024,加法#将各个特征一起合并起来得到组合特征comb_feature = torch.cat([mul_feature, add_feature, concat_feature], 2)return comb_featuredef forward(self, visual_feature_train, sentence_embed_train):#对视觉特征投影到语义空间并normtransformed_clip_train = self.v2s_lt(visual_feature_train)transformed_clip_train_norm = F.normalize(transformed_clip_train, p=2, dim=1)#对本文特征投影到语义空间并normtransformed_sentence_train = self.s2s_lt(sentence_embed_train)transformed_sentence_train_norm = F.normalize(transformed_sentence_train, p=2, dim=1)#做特征交叉cross_modal_vec_train = self.cross_modal_comb(transformed_clip_train_norm, transformed_sentence_train_norm)cross_modal_vec_train = cross_modal_vec_train.unsqueeze(0).permute(0, 3, 1, 2)#2层FC得到预测结果mid_output = self.fc1(cross_modal_vec_train)mid_output = F.relu(mid_output)sim_score_mat_train = self.fc2(mid_output).squeeze(0)return sim_score_mat_train
完整的逐行中文注释在:https://github.com/nakaizura/Source-Code-Notebook/tree/master/CTRL
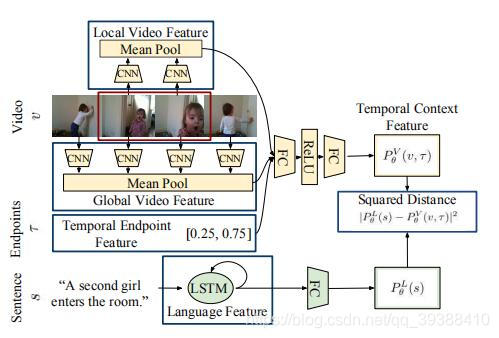
MCN
同样也是ICCV2017,MCN: Localizing Moments in Video with Natural Language,和上一份工作几乎同时提出,大体上的思路相同,不同的处理方法主要有:
- 使用度量函数来判断是否匹配(TALL是使用FC预测分数,MCN是均方差),同时使用了RGB(下式的V)和光流(下式的F)两种。 D θ ( s , v , τ ) = ∣ P θ V ( v , τ ) − P θ L ( s ) ∣ 2 + η ∣ P θ F ( f , τ ) − P θ L ( s ) ∣ 2 D_{\theta}(s,v,\tau)=|P^V_{\theta}(v,\tau)-P^L_{\theta}(s)|^2+\eta |P^F_{\theta}(f,\tau)-P^L_{\theta}(s)|^2 Dθ(s,v,τ)=∣PθV(v,τ)−PθL(s)∣2+η∣PθF(f,τ)−PθL(s)∣2
- LSTM处理文本,VGG处理视频。
- 视频段特征+全局特征提供片段上下文+时间间隔 τ \tau τ(片段占整个全局的位置信息如[0.25,0.75]),以全局的位置线索来加强模型。
此后一段时间内,大家开始在两种模态间探寻更好的交互和融合模式。
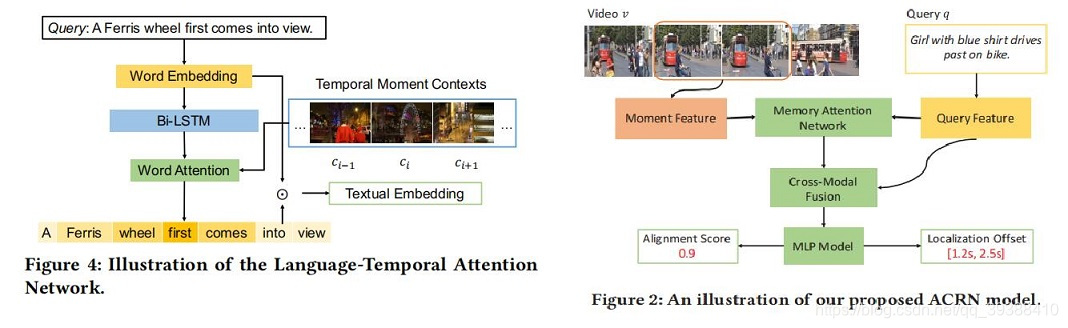
ROLE and ACRN
这两篇文章来自同一个团队,都是用Attention促进,加强模态融合的模型。一篇发自SIGIR2018:Attentive Moment Retrieval in Videos,一篇发自ACM MM2018:Cross-modal Moment Localization in Videos。
作者认为关于时间语态问题,即句子中的“先”“前”往往是被忽视的了,关于动态的视频的信息没有捕捉完全,所以他们尝试进一步联合上下文信息去改进这一点。
- ROLE:不把查询语句当单独的特征,通过结合上下文视频特征对句子加Attention后再embedding。然后将其与连续的帧进行级联以得到跨文本和视觉。最后和TALL一样用FC预测得分和偏移量。
- ACRN:不把视频当单独的特征,通过文本的信息对视频加Attention后再embedding。并且将上下文视觉特征和交叉模态特征表示整合到一个统一的模型中。其余的不变。
即这两篇文章一篇给文本加Attention,一篇给视频加Attention。所以很自然,加个co-Attention?
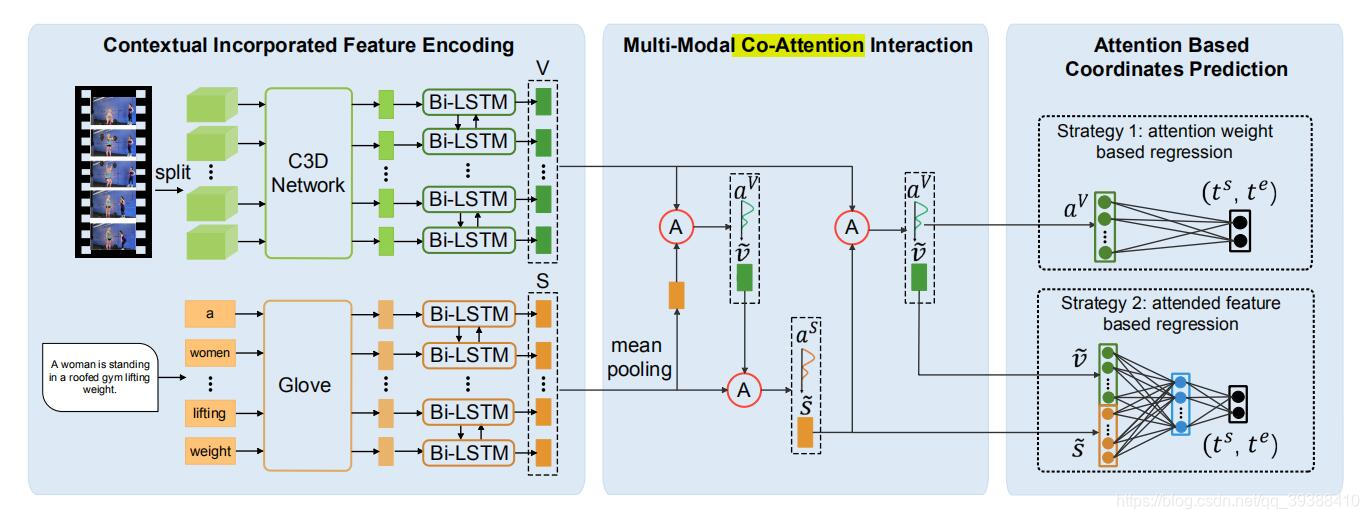
ABLR
来自AAAI2019,To Find Where You Talk: Temporal Sentence Localization in Video with Attention Based Location Regression。想法如上模型图。
- 用C3D+BiLSTM处理视频,用Glove+BiLSTM处理文本,再构建一个multi-modal co-Attention interaction模块,先文本给视频加Attention,再视频给文本加Attention。最后预测回归偏差有两种策略,一种是两种模态直接fusion之后预测,另一种是concat之后预测。
除了这种拿到特征后再fusion的晚融合方法,还有一些比较细致的工作。
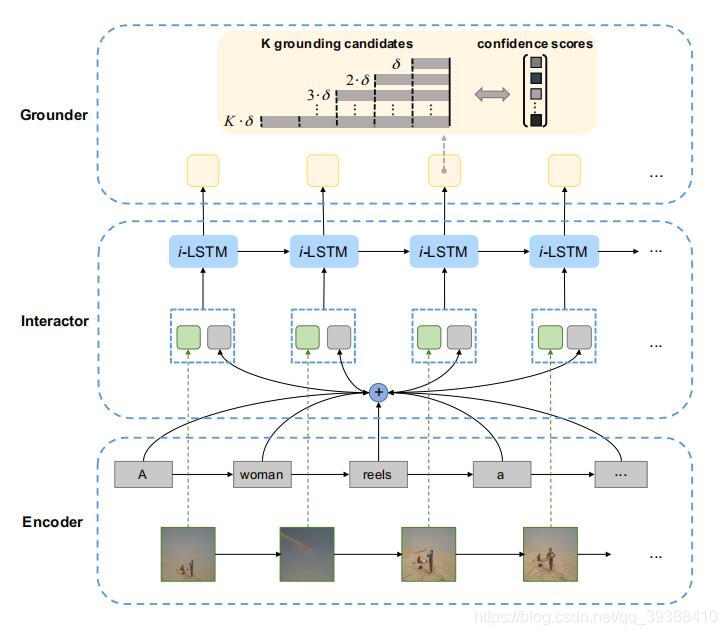
TGN
来自EMNLP2018,Temporally Grounding Natural Sentence in Video。作者尝试实时地捕捉视频和句子之间不断发展的细粒度的交互,所谓实时和发展…就是从每帧/逐词开始看,模型图如上。
- 在每个时刻,使用两组lstm处理每个时刻文本和视频的交互。并用两者的交互状态加文本的Attention,联合两者的向量后再用lstm算分数。
然后还可以进一步细化。。。
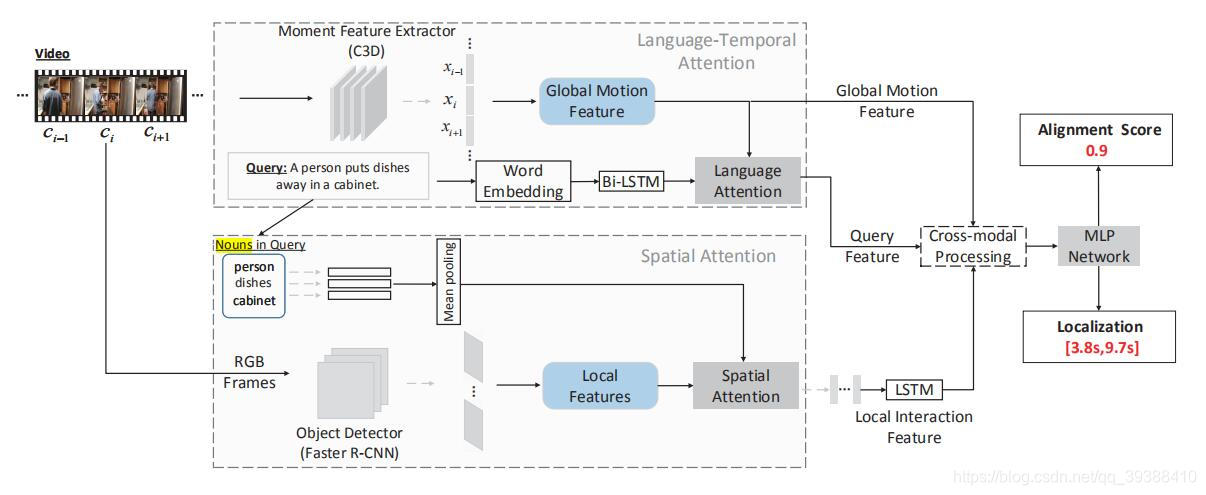
SLTA
出自ICMR2019,Cross-Modal Video Moment Retrieval with Spatial and Language-Temporal Attention。作者的动机是现有方法没有关注图片细节特征即空间信息,所以让我们继续细化,将视频的时空信息也结合起来!
- 全局信息还是用C3D和BiLSTM分别处理视频和文本。但是对nouns即文本里面的词用GloVe得到特征, 对应图片里面的目标用Faster R-CNN得到。
- 然后co-Attention。先全局运动特征给文本加Attention,再由查询文本名词给局部目标特征加Attention,最后再连续图片的lstm得到视频的特征。
- 最后然后加了Attention的文本特征、加了Attention的局部空间特征与全局运动特征的逐帧窗口级联,再FC求两个任务。
其实以上的模型玩到这里,还有点可以玩的。
- 比如句子的词的粒度还不够,那就再对切分的词再做一个语义树/图抽特征(Cross-Modal Interaction Networks for Query-Based Moment Retrieval in Videos),或者那就再融入语义信息(SAP:Semantic Proposal for Activity Localization in Videos via Sentence Query)。
- 比如产生的候选太多了,那么先融语义了以帮助消除不可能的候选(Multilevel Language and Vision Integration for Text-to-Clip Retrieval)。
- 比如两个模态的交互程度还不够,那么就在一层融合两层融合多层融(Interaction-Integrated Network)…
当然还可以继续玩融合方法也可以…有关更多的模态融合方法可以看看博主之前的文章:多模态融合。
下面介绍一些非-常规方法,首先是基于强化学习直接定位。
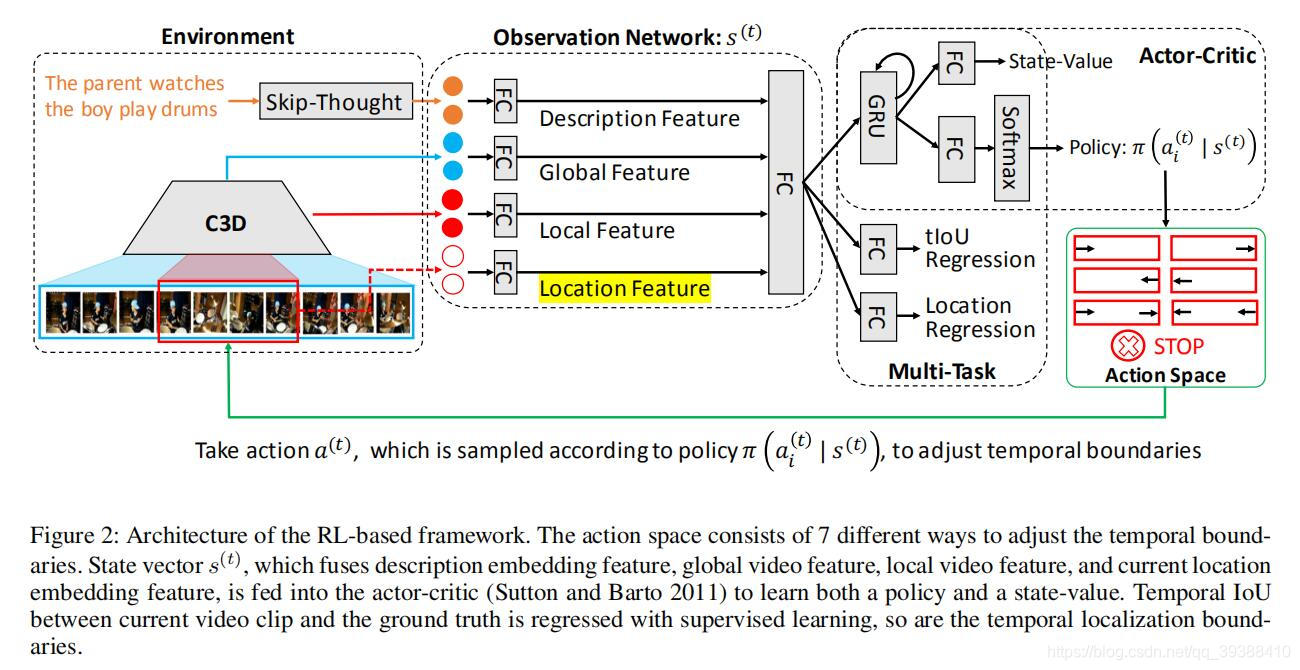
READ
出自AAAI2019,Read, Watch, and Move: Reinforcement Learning for Temporally Grounding Natural Language Descriptions in Videos,首次将强化学习引入到这个领域里面。大致的判断是,先基于一个初始的时间边界,接着对时间边界内的视频片段进行观察后决定边界应该如何移动(向左向右等),然后逐步迭代地调整时间边界,以找到最佳匹配的视频片段。这个过程可以被看做是时间边界逐步调整的序列决策过程。
- Environment。环境由skip-thought即sentence2vec得到特征,C3D得到视频的特征,同时结合全局的和局部的,再多一个location feature即位置信息来监督(这都有前面一些论文的影子)。
- Observation。把这些特征用FC抽象当作state特征。
- Actor-Critic。用AC算法来建模得到动作,这里不再细讲AC博主也曾整理过了。值得注意的是这里的Actor space由7种不同的方式来调整时间边界:分别是 起始点/终止点/起始点与终止点 左移;起始点/终止点/起始点与终止点 右移和停止动作(如图红色部分很明了)。然后reward是由移动得到的边界与真实边界算一个IoU来给出。
- 最后还是做两个多任务。这是为了学习更有代表性的状态向量,所以作者建议将强化学习和监督学习结合到一个多任务学习框架中。监督损失学习预测当前状态与地面真相的匹配程度以及时间边界应该在哪里,而RL使它能够逐步接近地面真相。
Trick:
- 初始位置在[0.25,0.75]开始
- agent每步的步长为视频的长度除10,以保证在10步是能够遍历整个视频的
其他的优化方法如attention等机制这篇文章都暂时没有用,但是…总会有人迅速占坑的。
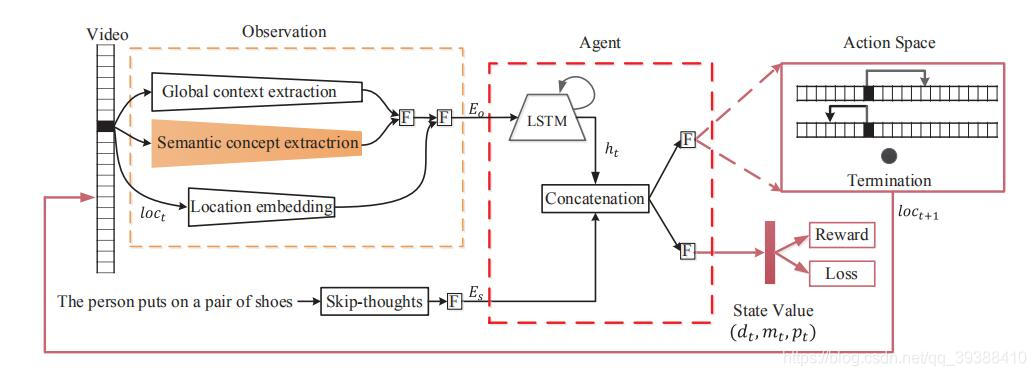
SM-RL
来自CVPR2019,Language-driven Temporal Activity Localization: A Semantic Matching Reinforcement Learning Model。
- 基本上的思路与AAAI一致,不同的地方就是图上的红色部分,融入了–语义信息,即用Faster R-CNN得到有关视频区域的语义概念。
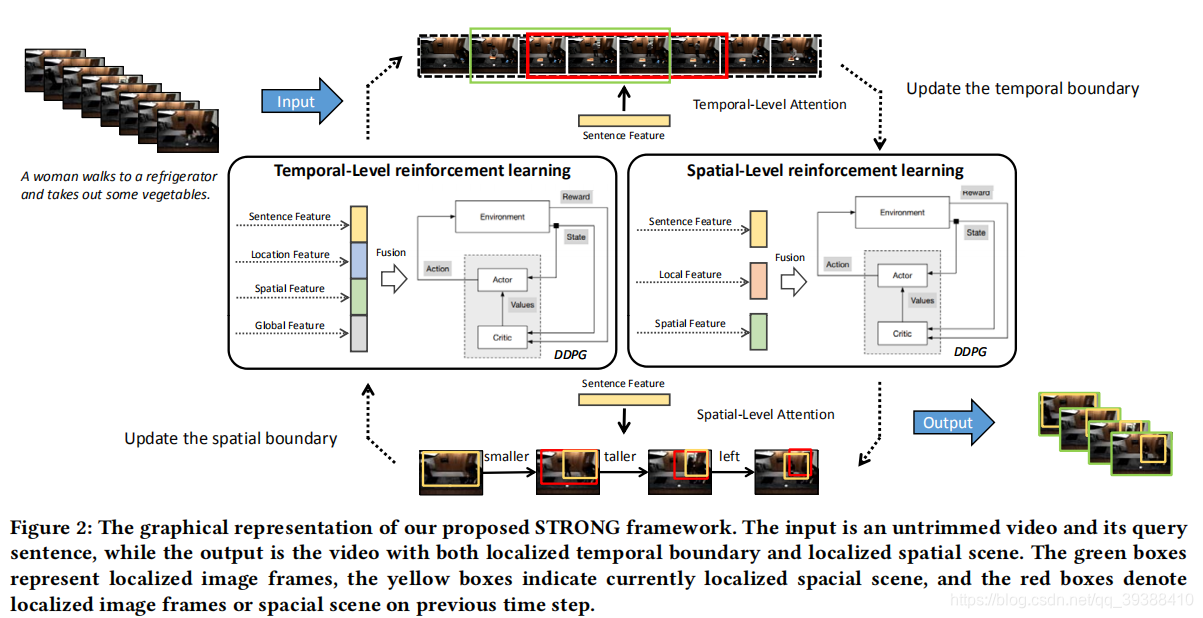
STRONG
出自ACM MM 2020,STRONG: Spatio-Temporal Reinforcement Learning for Cross-Modal Video Moment Localization。上一篇文章用了语义的概念,这篇文章也开始基于RL的方法做的更加的细致,即除了在时间上使用强化学习,在空间上也可以用强化学习来定位,以达到追踪场景目标的目的。
- 基本的用强化学习来解决问题的思路是不变的,在此之上作者又加入了对空间场景的追踪。对于空间上的强化学习移动如上图的下半部分,也和时序上的RL一致,从帧的局部定义追踪框的动作如变窄变宽左右移动等等共9个动作,值得注意的一点是,作者提到“此时的局部环境是变化的而不是静止的,因为随着帧的变化而图像环境也在发生变化。但在短时间内,变化相对较小所以在逐帧的情况下可以认为是稳定的”。
paper:https://dl.acm.org/doi/10.1145/3394171.3413840
除了RL方法某种程度上可以直接做到定位,但大多数方法还是基于候选集。但是生成的候选集又太多了,所以也有几篇在候选集身上打主意的方法。
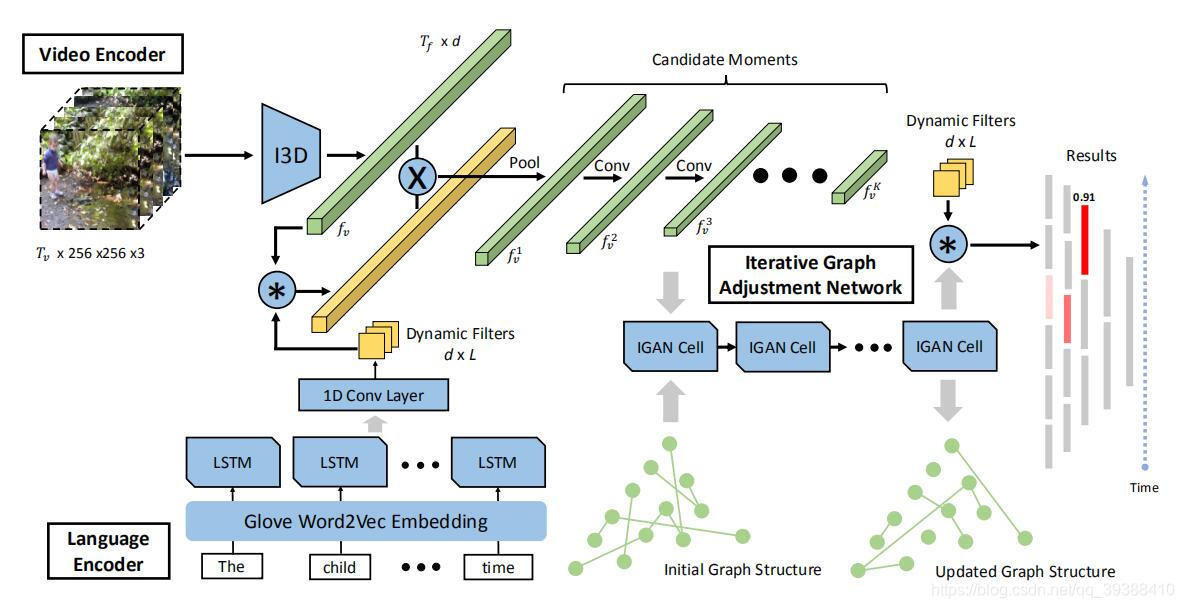
MAN
出自CVPR2019,MAN: Moment Alignment Network for Natural Language Moment Retrieval via Iterative Graph Adjustment。抽特征什么的很常规,创新点主要是在Iterative graph adjustment network,即尝试对所生成的各个候选片段构图!并设计一个迭代图调整网络来共同学习。
- 定义一层图卷积: H = R e L U ( G X W ) H=ReLU(GXW) H=ReLU(GXW)G是邻接矩阵,X是特征,W是权重。
- 迭代图。R是残差分量,会加到邻接矩阵中。X0是初始的特征向量,按下面的公式不断的更新图结构。 R t = n o r m ( X t − 1 W t r X t − 1 T ) R_t=norm(X_{t-1}W^r_tX^T_{t-1}) Rt=norm(Xt−1WtrXt−1T) G t = t a n h ( G t − 1 + R t ) G_t=tanh(G_{t-1}+R_t) Gt=tanh(Gt−1+Rt) X t = R e L U ( G t X 0 W t o ) X_t=ReLU(G_tX_0W^o_t) Xt=ReLU(GtX0Wto)
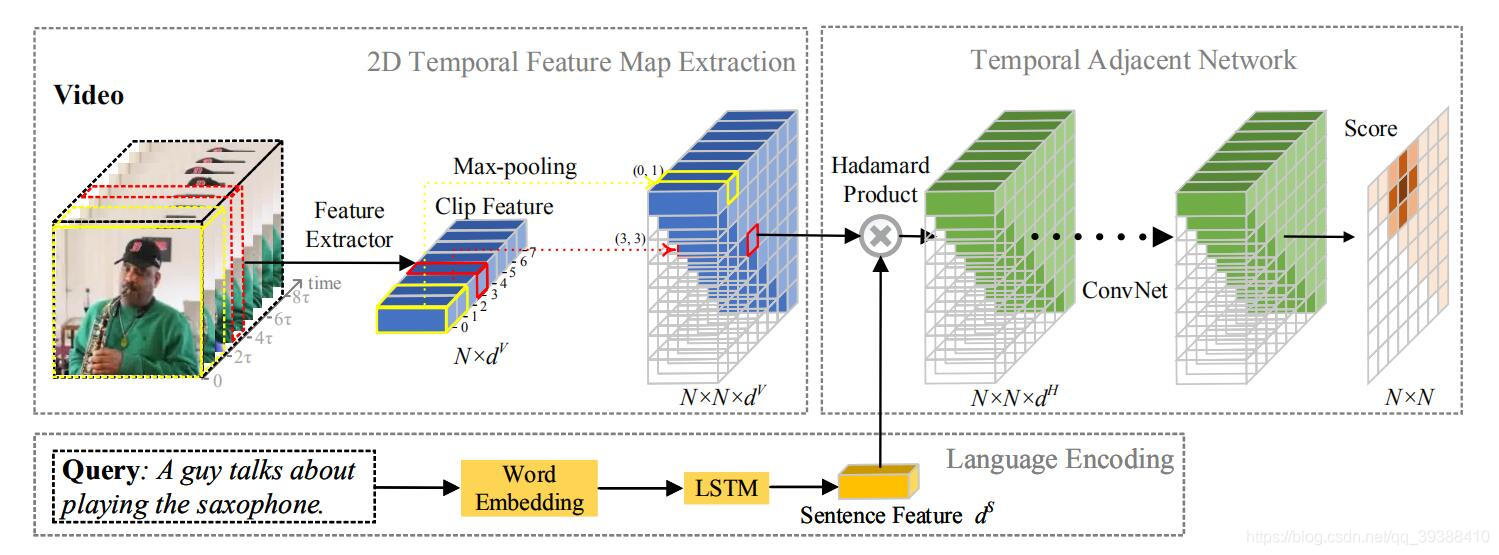
2D-TAN
出自AAAI2020,Learning 2D Temporal Adjacent Networks for Moment Localization with Natural Language,2019 ICCV HACS动作定位挑战赛冠军方案。
- Motivation:以往模型一般单独考虑时间,忽视了时间的依赖性。(不能在当前时刻对其他时刻进行预测)
- Method:将定位起始解耦,时间从一维变为二维,即变成二维矩阵,预测每一个位置的score。这样做的好处是特征图中每个位置的视频特征都与文本特征融合,得到相似度特征图(图像中左侧的绿色立方体),而这个矩阵的大小可以直接通过切分视频的细粒度做到,然后将融合后的相似性特征映射通过一系列卷积层,并逐层建立各段与其周围段之间的关系,最后将考虑邻域关系的相似度特征输入到完全连通层中,得到最终的得分。
paper:https://ojs.aaai.org//index.php/AAAI/article/view/6984
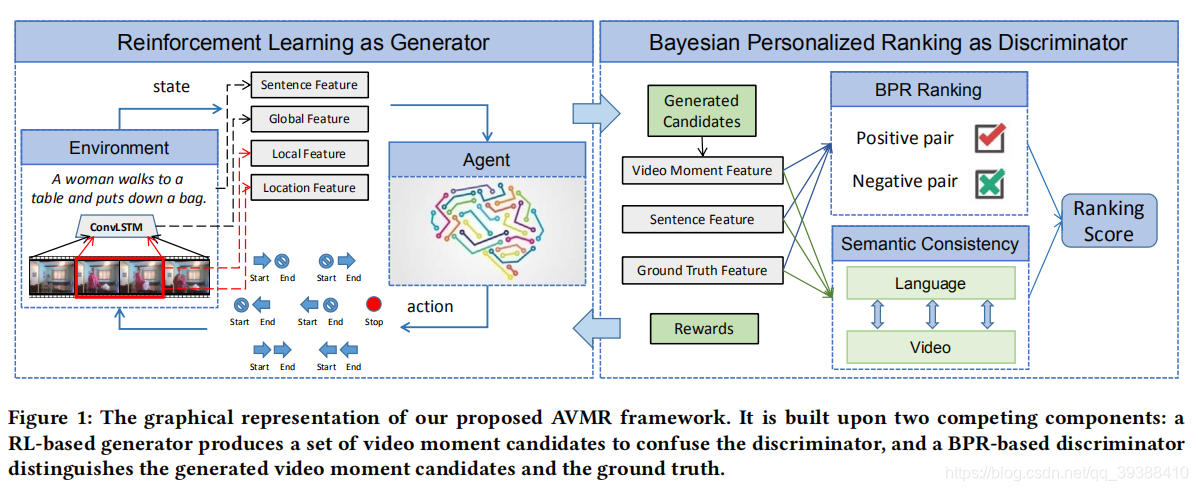
AVMR
同样出自ACM MM 2020,Adversarial Video Moment Retrieval by Jointly Modeling Ranking and Localization。这篇文章做的很巧妙,用对抗的思想结合了RL-based定位方法和Candidate-based检索方法。
- Motivation:基于先预先切分候选再玩各种语义融合的方法,只有在生成比较多候选的情况下效果较好。同时,基于强化学习直接去定位的方法,对于仅仅用IoU提供Reward来说又是不太稳定的,那么有没有方法能够结合这两点呢??
- Method:作者的解决方案就是利用对抗训练的策略来结合这两点。即先用强化学习通过左右移动“生成”一些候选,这样可以在一定有限的数量中得到多粒度的候选集,然后用一个判别器(BPR)来对这些候选集进行排序以得到最后的结果,同时判别器的排序结果会提供给强化学习以Reward以帮助强化学习生成器的收敛。
paper:https://dl.acm.org/doi/10.1145/3394171.3413841
同时该作者的扩展论文也整理了一些相关RL-based定位方法和Candidate-based检索方法的表格:
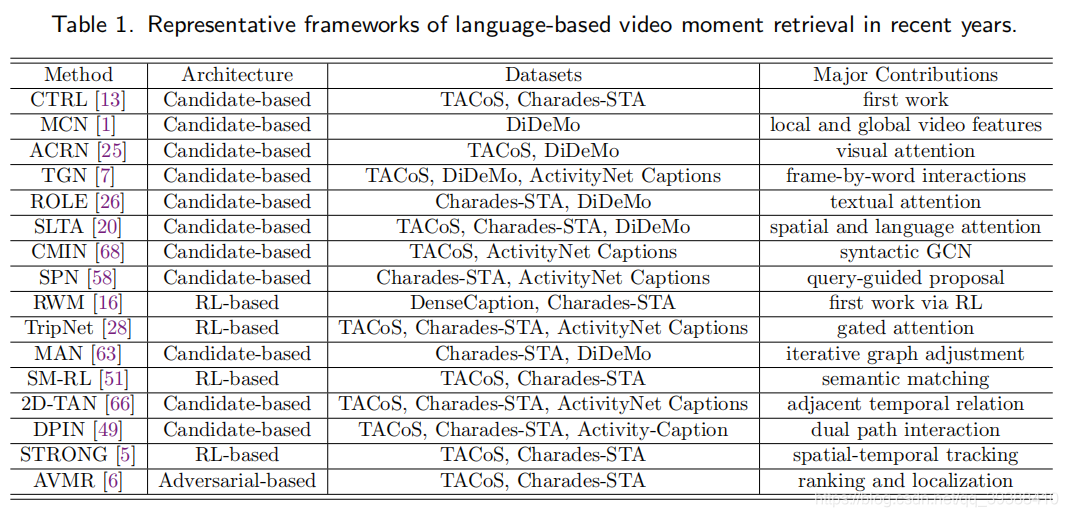
上图自:[TOMM2021] Moment is Important: Language-Based Video Moment Retrieval via Adversarial Learning
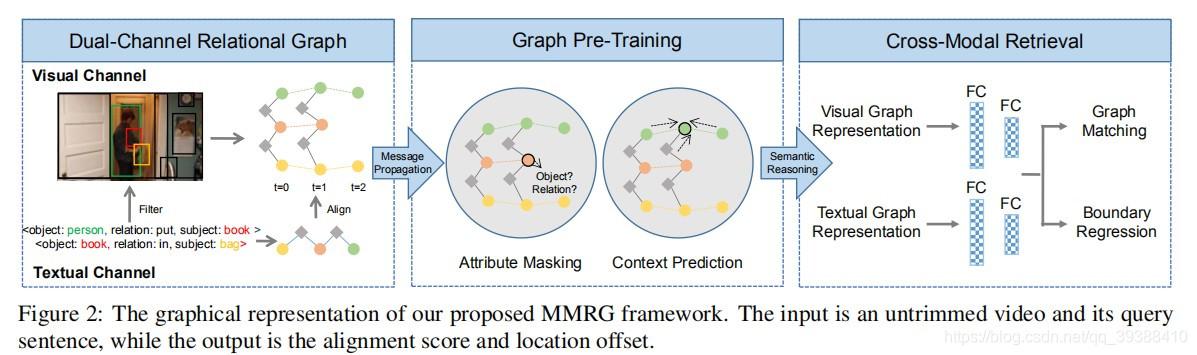
MMRG
补来自最近的CVPR2021的文章,Multi-Modal Relational Graph for Cross-Modal Video Moment Retrieval。这篇文章的动机是以往基于候选的方法会导致候选之间非常相似难以区别,那么直接理解内容(局部目标)的细微变化会是更好的选择。比如“一个人把书放入袋子”这个query,如果能准确的捕捉到“人”把“书”放到“”袋子“”里面这一动作的瞬间,那么定位moment将会变的非常简单。
所以作者提出提出多模态关系图模型来捕捉视频中的局部目标之间的时空关系,并且在图预训练的框架下优化特征表达。模型架构如上图分为三个部分:
- 多通道关系图。首先对图片和句子都抽取对应的目标object,然后根据关系构建Graph,其中视频的graph是显式化关系表达的时空图(即动作“拿”也会被当作是一个node)。值得注意的是,这里为了保证不同模态的object的一致性,作者会用文本端的object对图像端的object进行过滤(即只保留对应的人,书,袋子)。然后对两个模态的图进行类似GAT的特征优化。
- 图预训练。作者对多通道关系图做GAT发现效果一般,考虑是两个问题:1 显式化关系后的Graph是异构的(节点有多种);2 visual和textual之间也是异构的(模态有多种)。即当前Graph中存在多类异构的数据,这样直接GAT会造成特征混淆,所以作者尝试Graph Pretraning来优化这两点,即在Node级别和Graph级别做两个预训练任务(其实就是BERT预训练所用的两类方法),一是attribute mask,这里可以解决显式关系与名词的异构,二是context prediction,这里可以促进模态间的语义理解。从而可以使Graph学习好的特征。
- 跨模态检索。这里做两个下游任务:图匹配,即判断文本和视频的语义是否匹配;边界回归,这个和上面其他的工作一样,用于优化边界预测。
paper:cvpr_online

A Closer Look at Temporal Sentence Grounding in Videos_ Datasets and Metrics
继续补文章,一篇详细讨论了现有数据集的偏差问题(即可能模型不需要学什么内容,直接学数据偏差就有不错的结果)。如上图,bais-based是直接统计frequency statistics的模型,而predictALL则是直接预测整个视频的时间,结果对比可以看到,和其他的模型结果相差不大!!这种结果或许说明,现有模型几乎都是在学习数据集的分数,而它们是否学习到多模态特征并不确定。
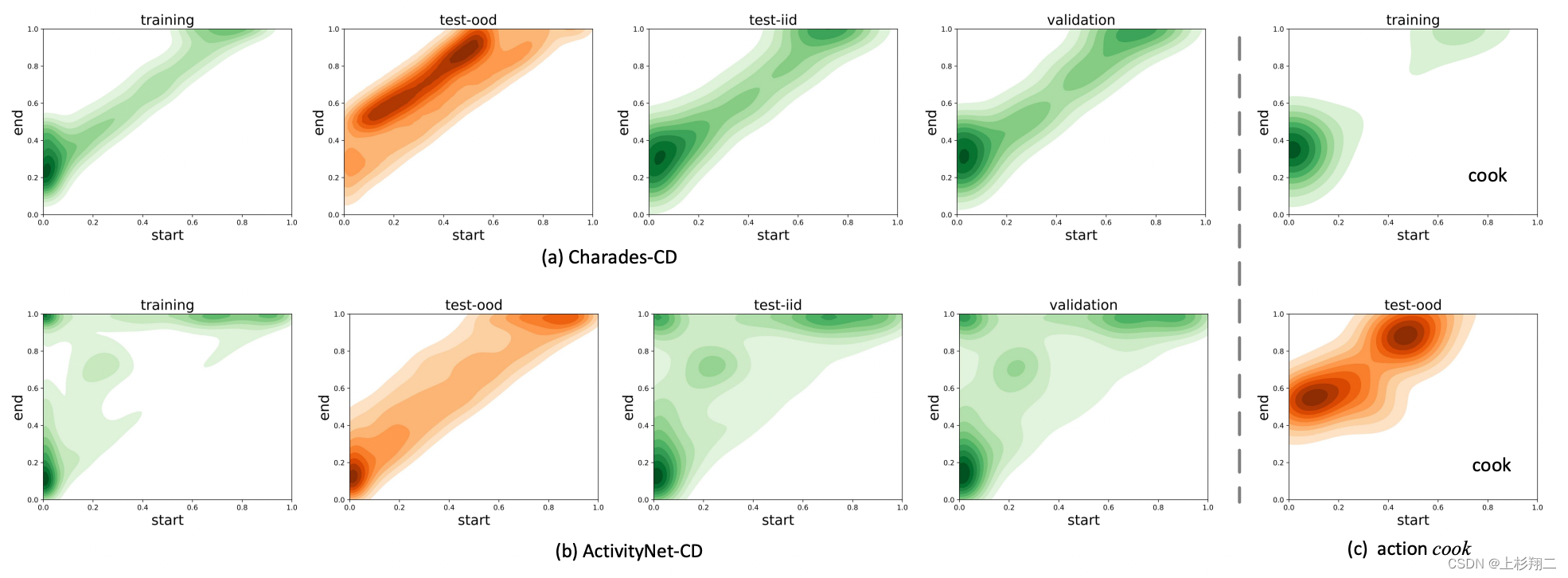
因此作者在这篇文章中提供了新的去偏datasets和新的metrics。如上图所示,数据集分布会更均匀一些。

Video Corpus Moment Retrieval with Contrastive Learning
补SIGIR2021的文章,利用对比学习统一片段检索和视频检索,即Video Corpus Moment Retrieval的全库检索。如上图所示,模型可以同时完成Video Retrieval 和 Moment Localization。motivation来自于,现有方法一般使用的跨模态交互学习,但高效率和高质量检索之间很难同时保持。
所以作者们直接引入对比学习来改进视频编码器和文本编码器。其中视频对比学习旨在最大程度地提高查询和候选视频之间的相互信息。帧对比学习的目的是突出视频中帧级查询对应的片段。
模型结构如下图所示,模型的前半段是一堆较为复杂的Transformer,包括提取自身特征的Transformer和捕捉跨模态关系的co- attention Transformer,最后进行预测。
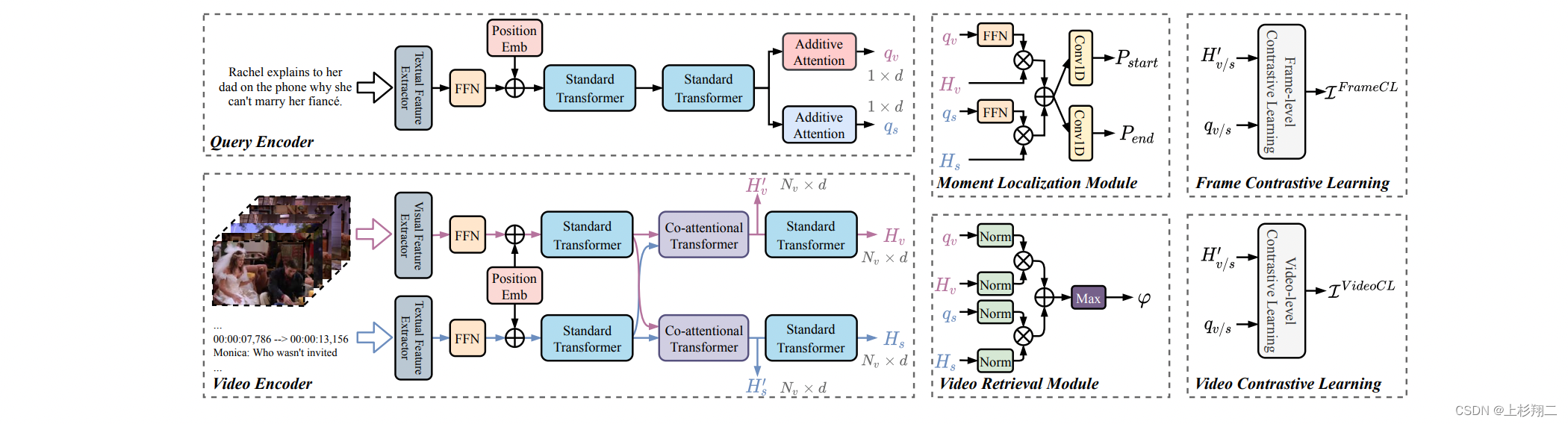
比较重要的部分就是最后的两个对比学习组件,Frame Contrastive Learning 和Video Contrastive Learning,即视频对比学习旨在最大程度地提高查询和候选视频之间的相互信息。帧对比学习的目的是突出视频中帧级查询对应的片段。
- paper:https://arxiv.org/pdf/2105.06247.pdf
- code:https://github.com/IsaacChanghau/ReLoCLNet

Point Prompt Tuning for Temporally Language Grounding
继续补新出的SIGIR2022的文章,这篇文章比较有意思的是应用了最新的prompt learning来做视频片段检索。作者的motivation在于,现有的方法虽然用了一堆Transformer或者对比学习等等,但其实没有把目前多模态预训练技术的优势发挥到最大,而prompt技术十分合适这一点(博主其他文章有介绍过基础,不再赘述)。直接来看作者提出的prompt-based新方式。
模型结构图如上图,输入是整个文章的核心,即prompt input和video input:
- prompt input:[CLS] the text of [Q], starts at frame [S] and ends at frame [E]
- video input:整个视频的采样帧。
然后通过预训练的GPT-2抽取文本特征,ViT抽取视觉特征,然后输入后面的交互Transformer中学习多模态交互信息,最后直接tuning得到起始帧和结束帧位置。更多训练细节大家可以参看原文,比如作者在训练时会frozen下面的模块,采样的转换规则等等。
- paper:https://dl.acm.org/doi/10.1145/3477495.3531795
目前这个领域还有一些基于弱监督的方法,即不用IoU来做监督学习,用query做弱监督就行了。或者结合因果推理等等方法出现…
更多更详细的论文整理请见github(一般放github简评比放博文会快一点点,持续更新):
- https://github.com/yawenzeng/Awesome-Cross-Modal-Video-Moment-Retrieval
另外如果您有一些我没有整理过的,且motivation较好的(即不incremental的文章),欢迎随时留言!
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!