Pytorch从入门到放弃(6)——实现图像多标签的训练与分类
传统的用于执行分类任务的深度学习模型,往往是解决的单分类任务,即为一幅图像只预测一个标签,但现实世界中往往一幅图像中通常是含有多个标签的 。Pytorch中分类任务常用的损失函数CrossEntropyLoss也是处理单标签数据的,无法实现多标签数据端到端的训练。在工作或日常实验中,我们经常会遇到一幅图像中含有多个标签的问题,我们需要怎样来处理呢?下面给出两个解决方案:1、即一幅图像包含几个标签就使这幅图像在一个epoch训练中出现多少次,但每次参与训练时该图像对应的标签是不同的,这种方法是最简单的;2、使用Pytorch的BCELoss,该损失函数支持一幅图像对应多个标签的输入,输入的标签为一组0和1组成的向量。
许多小伙伴咨询如何计算模型的准确率,前段时间一直在忙别的项目,趁着五一假期,将计算模型准确率的方法补全了。补充了两种模型性能计算的方法:1、calculate_acuracy_mode_one(model_pred, labels)函数:需要人为的设定一个阈值,当模型的预测结果(经过sigmoid函数处理的模型输出结果可以视为预测结果为这一类的概率)大于这个阈值则视为图像中含有这一类物体;2、calculate_acuracy_mode_two(model_pred, labels)函数:需要人为的设定每幅图像中含有多少类物体(即:矬子里面拔大个,选择预测概率最大的预测结果作为预测结果),实验中大家可以根据自己的需求选取不同的模型性能计算方式。
首先需要为你的数据集生成一个txt文件,用来存储图像的名称与标签,图像中包含该标签则为1,否则为0。如下所示:
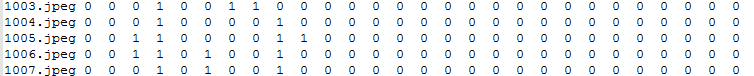
废话不多说,直接上代码:
from PIL import Image
from torch.utils.data import Dataset, DataLoader
import torch
import torch.nn as nn
from torch.optim import lr_scheduler
from torchvision import datasets, models, transforms
import time
import os# 是否使用gpu运算
use_gpu = torch.cuda.is_available()# 定义数据的处理方式
data_transforms = {'train': transforms.Compose([# 将图像进行缩放,缩放为256*256transforms.Resize(256),# 在256*256的图像上随机裁剪出227*227大小的图像用于训练transforms.RandomResizedCrop(227),# 图像用于翻转transforms.RandomHorizontalFlip(),# 转换成tensor向量transforms.ToTensor(),# 对图像进行归一化操作# [0.485, 0.456, 0.406],RGB通道的均值与标准差transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),# 测试集需要中心裁剪,甚至不裁剪,直接缩放为224*224for,不需要翻转'val': transforms.Compose([transforms.Resize(256),transforms.CenterCrop(227),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
}# 定义数据读入
def Load_Image_Information(path):# 图像存储路径image_Root_Dir = r'图像文件夹路径'# 获取图像的路径iamge_Dir = os.path.join(image_Root_Dir, path)# 以RGB格式打开图像# Pytorch DataLoader就是使用PIL所读取的图像格式# 建议就用这种方法读取图像,当读入灰度图像时convert('')return Image.open(iamge_Dir).convert('RGB')# 定义自己数据集的数据读入类
class my_Data_Set(nn.Module):def __init__(self, txt, transform=None, target_transform=None, loader=None):super(my_Data_Set, self).__init__()# 打开存储图像名与标签的txt文件fp = open(txt, 'r')images = []labels = []# 将图像名和图像标签对应存储起来for line in fp:line.strip('\n')line.rstrip()information = line.split()images.append(information[0])# 将标签信息由str类型转换为float类型labels.append([float(l) for l in information[1:len(information)]])self.images = imagesself.labels = labelsself.transform = transformself.target_transform = target_transformself.loader = loader# 重写这个函数用来进行图像数据的读取def __getitem__(self, item):# 获取图像名和标签imageName = self.images[item]label = self.labels[item]# 读入图像信息image = self.loader(imageName)# 处理图像数据if self.transform is not None:image = self.transform(image)# 需要将标签转换为float类型,BCELoss只接受float类型label = torch.FloatTensor(label)return image, label# 重写这个函数,来看数据集中含有多少数据def __len__(self):return len(self.images)# 生成Pytorch所需的DataLoader数据输入格式
train_Data = my_Data_Set(r'train.txt路径', transform=data_transforms['train'], loader=Load_Image_Information)
val_Data = my_Data_Set(r'val.txt路径', transform=data_transforms['val'], loader=Load_Image_Information)
train_DataLoader = DataLoader(train_Data, batch_size=10, shuffle=True)
val_DataLoader = DataLoader(val_Data, batch_size=10)
dataloaders = {'train':train_DataLoader, 'val':val_DataLoader}
# 读取数据集大小
dataset_sizes = {'train': train_Data.__len__(), 'val': val_Data.__len__()}# 训练与验证网络(所有层都参加训练)
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):Sigmoid_fun = nn.Sigmoid()since = time.time()for epoch in range(num_epochs):print('Epoch {}/{}'.format(epoch, num_epochs - 1))print('-' * 10)# 每训练一个epoch,验证一下网络模型for phase in ['train', 'val']:running_loss = 0.0running_precision = 0.0running_recall = 0.0batch_num = 0if phase == 'train':# 学习率更新方式scheduler.step()# 调用模型训练model.train()# 依次获取所有图像,参与模型训练或测试for data in dataloaders[phase]:# 获取输入inputs, labels = data# 判断是否使用gpuif use_gpu:inputs = inputs.cuda()labels = labels.cuda()# 梯度清零optimizer.zero_grad()# 网络前向运行outputs = model(inputs)# 计算Loss值loss = criterion(Sigmoid_fun(outputs), labels)# 这里根据自己的需求选择模型预测结果准确率的函数precision, recall = calculate_acuracy_mode_one(Sigmoid_fun(outputs), labels)# precision, recall = calculate_acuracy_mode_two(Sigmoid_fun(outputs), labels)running_precision += precisionrunning_recall += recallbatch_num += 1# 反传梯度loss.backward()# 更新权重optimizer.step()# 计算一个epoch的loss值和准确率running_loss += loss.item() * inputs.size(0)else:# 取消验证阶段的梯度with torch.no_grad():# 调用模型测试model.eval()# 依次获取所有图像,参与模型训练或测试for data in dataloaders[phase]:# 获取输入inputs, labels = data# 判断是否使用gpuif use_gpu:inputs = inputs.cuda()labels = labels.cuda()# 网络前向运行outputs = model(inputs)# 计算Loss值# BCELoss的输入(1、网络模型的输出必须经过sigmoid;2、标签必须是float类型的tensor)loss = criterion(Sigmoid_fun(outputs), labels)# 计算一个epoch的loss值和准确率running_loss += loss.item() * inputs.size(0)# 这里根据自己的需求选择模型预测结果准确率的函数precision, recall = calculate_acuracy_mode_one(Sigmoid_fun(outputs), labels)# precision, recall = calculate_acuracy_mode_two(Sigmoid_fun(outputs), labels)running_precision += precisionrunning_recall += recallbatch_num += 1# 计算Loss和准确率的均值epoch_loss = running_loss / dataset_sizes[phase]print('{} Loss: {:.4f} '.format(phase, epoch_loss))epoch_precision = running_precision / batch_numprint('{} Precision: {:.4f} '.format(phase, epoch_precision))epoch_recall = running_recall / batch_numprint('{} Recall: {:.4f} '.format(phase, epoch_recall))torch.save(model.state_dict(),'The_'+ str(epoch) + '_epoch_model.pkl'"Themodel_AlexNet.pkl")time_elapsed = time.time() - sinceprint('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))# 计算准确率——方式1
# 设定一个阈值,当预测的概率值大于这个阈值,则认为这幅图像中含有这类标签
def calculate_acuracy_mode_one(model_pred, labels):# 注意这里的model_pred是经过sigmoid处理的,sigmoid处理后可以视为预测是这一类的概率# 预测结果,大于这个阈值则视为预测正确accuracy_th = 0.5pred_result = model_pred > accuracy_thpred_result = pred_result.float()pred_one_num = torch.sum(pred_result)if pred_one_num == 0:return 0, 0target_one_num = torch.sum(labels)true_predict_num = torch.sum(pred_result * labels)# 模型预测的结果中有多少个是正确的precision = true_predict_num / pred_one_num# 模型预测正确的结果中,占所有真实标签的数量recall = true_predict_num / target_one_numreturn precision.item(), recall.item()# 计算准确率——方式2
# 取预测概率最大的前top个标签,作为模型的预测结果
def calculate_acuracy_mode_two(model_pred, labels):# 取前top个预测结果作为模型的预测结果precision = 0recall = 0top = 5# 对预测结果进行按概率值进行降序排列,取概率最大的top个结果作为模型的预测结果pred_label_locate = torch.argsort(model_pred, descending=True)[:, 0:top]for i in range(model_pred.shape[0]):temp_label = torch.zeros(1, model_pred.shape[1])temp_label[0,pred_label_locate[i]] = 1target_one_num = torch.sum(labels[i])true_predict_num = torch.sum(temp_label * labels[i])# 对每一幅图像进行预测准确率的计算precision += true_predict_num / top# 对每一幅图像进行预测查全率的计算recall += true_predict_num / target_one_numreturn precision, recall
# 精调AlexNet
if __name__ == '__main__':# 导入Pytorch封装的AlexNet网络模型model = models.alexnet(pretrained=True)# 获取最后一个全连接层的输入通道数num_input = model.classifier[6].in_features# 获取全连接层的网络结构feature_model = list(model.classifier.children())# 去掉原来的最后一层feature_model.pop()# 添加上适用于自己数据集的全连接层# 260数据集的类别数feature_model.append(nn.Linear(num_input, 260))# 仿照这里的方法,可以修改网络的结构,不仅可以修改最后一个全连接层# 还可以为网络添加新的层# 重新生成网络的后半部分model.classifier = nn.Sequential(*feature_model)if use_gpu:model = model.cuda()# 定义损失函数criterion = nn.BCELoss()# 为不同层设定不同的学习率fc_params = list(map(id, model.classifier[6].parameters()))base_params = filter(lambda p: id(p) not in fc_params, model.parameters())params = [{"params": base_params, "lr":0.0001},{"params": model.classifier[6].parameters(), "lr":0.001},]optimizer_ft = torch.optim.SGD(params, momentum=0.9)# 定义学习率的更新方式,每5个epoch修改一次学习率exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=5, gamma=0.1)train_model(model, criterion, optimizer_ft, exp_lr_scheduler, num_epochs=10)代码地址:https://github.com/Sun-DongYang/Pytorch.git,自己学习的一个总结,如有错误,恳请诸位大神批评指正。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!