有趣且强大的随机森林
随机森林
- 集成算法
- 结合策略
- 投票法(随机森林分类)
- 平均法(随机森林回归)
- 简单平均法
- 加权平均法
- sklearn中的随机森林建模流程
- 随机森林重要参数
- 随机森林的重要属性
- 随机森林的重要接口
- 随机森林要点掌握
- 实例
- 导入数据
- 数据分布
- 建立随机森林分类模型
- 随机森林和决策树的对比
- 混淆矩阵
- 代码整合
- 总结
集成算法
集成算法通过构建多个弱学习器并结合来完成学习任务,那么就用随机森林来举例子,随机森林是由很多个决策树来形成的,这些决策树都是弱学习器,在二分类中弱学习器就是精确度比50%大一点点的分类器。
一般的随机森林中决策树一般是100棵。
结合策略
投票法(随机森林分类)
假如现在有一个二分类的问题,有100棵决策树,那么假如70棵决策树认为这个样本属于A类,30棵决策树认为这个样本属于B类,那么该随机森林的输出就会认为这个样本属于A类,这就是投票法的少数服从多数。
平均法(随机森林回归)
假如现在有一个回归类问题,那么100棵决策树就会有100个输出,但是随机森林最后的输出只能是一个,因此我们可以采取平均的办法。
简单平均法
就是简单地把每个决策树的结果加起来除以决策树的数量。
y = ∑ i = 1 n y i n y = \frac{\sum_{i=1}^ny_i}{n} y=n∑i=1nyi
加权平均法
通过对每个决策树赋予权重,然后让每个决策树的输出乘以权重再相加就能够得到随机森林的输出了。
y = ∑ i = 1 n w i y i y = \sum_{i=1}^nw_iy_i y=i=1∑nwiyi
通常要求 w i ≥ 0 w_i\geq0 wi≥0, ∑ i = 1 n w i = 1 \sum_{i=1}^nw_i=1 ∑i=1nwi=1;
sklearn中的随机森林建模流程
from sklearn.ensemble import RandomForestClassifier #导入随机森林模块clf = RandomForestClassifier() #实例化一个模型
model = clf.fit(x,y) #训练实例化的这个模型
print(clf.score(xtest,ytest)) #使用.score接口输出测试集得分
随机森林重要参数
| 参数 | 含义 |
|---|---|
| n_estimators | 随机森林中树的数量 |
| criterion | 不纯度衡量指标:‘gini’:基尼系数 ,‘entropy’:信息熵 |
| max_depth | 限制树的最大深度(防止过拟合重要参数) |
| min_samples_leaf | 一个节点分支后的每个子节点至少包含多少个训练样本,否则不会发生分支 |
| min_samples_split | 一个节点包含至少多少个训练样本,这个节点才会被允许分支 |
| max_features | 分支时考虑的特征个数 |
| min_impurity_decrease | 每一个分支需要提高的信息增益的大小是多少 |
| bootstrap | 默认:‘True’,代表采用有放回的抽样技术。一般不选择’False’ |
| oob_score | 因为随机森林是一种袋装法的集成算法,如果希望用袋外数据来测试随机森林的结果,则需要在实例化的时候将此参数设置为True,训练完毕后,我们可以用随机森林的一个重要属性:oob_score_来查看我们的袋外数据的测试结果 |
随机森林的重要属性
| 属性 | 含义 |
|---|---|
| .estimators_ | 查看随机森林中所有树的样子 |
| .oob_score_ | 查看袋外数据的得分 |
| .feature_importances_ | 查看各个特征对模型的重要性 |
随机森林的重要接口
| 接口 | 含义 |
|---|---|
| .apply | 返回每个测试样本所在的叶子节点的索引 |
| .score | 返回模型的得分(默认返回的是 R 2 R^2 R2) |
| .fit | 训练 |
| .predict | 预测 |
| .predict_proba | 返回每个测试样本对应被分到每一类标签的概率,标签有几个就会返回几个概率 |
随机森林要点掌握
- 每个弱学习器必须是相互独立的
- 每个弱学习器的判断准确率必须超过50%
实例
导入数据
from sklearn.datasets import load_wine #导入sklearn自带红酒数据集
wine = load_wine() #实例化红酒数据集
#因为数据是用字典保存的因此可以采用.键的模式取出数据
x = wine.data #特征矩阵
y = wine.target #标签(三分类)
数据分布
from sklearn.datasets import load_wine #导入sklearn自带红酒数据集
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
wine = load_wine() #实例化红酒数据集
#因为数据是用字典保存的因此可以采用.键的模式取出数据
x = wine.data #特征矩阵
y = wine.target #标签(三分类)pca = PCA(n_components=2) #主成分分析将特征矩阵降成二维
x_dr = pca.fit_transform(x) #导出降维后的矩阵
print(pca.explained_variance_ratio_.sum()) #导出可解释性方差plt.figure()
plt.scatter(x_dr[y==0,0],x_dr[y==0,1],label=wine.target_names[0])
plt.scatter(x_dr[y==1,0],x_dr[y==1,1],label=wine.target_names[1])
plt.scatter(x_dr[y==2,0],x_dr[y==2,1],label=wine.target_names[2])
plt.legend()
plt.show()
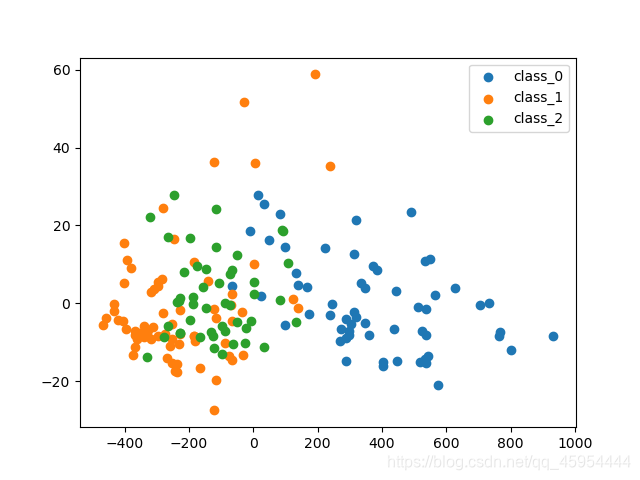
然后我们发现第0类跟1、2重叠的区域比较少容易分开,但是1类和2类混杂的地方比较多不容易分开,下面将介绍随机森林分类模型的建立。
建立随机森林分类模型
from sklearn.datasets import load_wine #导入sklearn自带红酒数据集
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
wine = load_wine() #实例化红酒数据集
#因为数据是用字典保存的因此可以采用.键的模式取出数据
x = wine.data #特征矩阵
y = wine.target #标签(三分类)
#建立随机森林分类模型
#将数据集分成训练集70%,测试集30%
xtrain,xtest,ytrain,ytest = train_test_split(x,y,test_size=0.3)rfc = RandomForestClassifier() #实例化随机森林分类模型
model = rfc.fit(xtrain,ytrain) #训练随机森林分类模型
print('训练集得分:',rfc.score(xtrain,ytrain))
print('测试集得分:',rfc.score(xtest,ytest))
结果:

可以看出来结果比较好,虽然第1类和第2类有这么多重叠的地方随机森林也有这么好的效果,可以发现随机森林是一个非常强大的算法。
随机森林和决策树的对比
from sklearn.datasets import load_wine #导入sklearn自带红酒数据集
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
wine = load_wine() #实例化红酒数据集
#因为数据是用字典保存的因此可以采用.键的模式取出数据
x = wine.data #特征矩阵
y = wine.target #标签(三分类)
#建立随机森林分类模型
#将数据集分成训练集70%,测试集30%
xtrain,xtest,ytrain,ytest = train_test_split(x,y,test_size=0.3)rfc = RandomForestClassifier() #实例化随机森林分类模型
model = rfc.fit(xtrain,ytrain) #训练随机森林分类模型
print('训练集得分:',rfc.score(xtrain,ytrain))
print('测试集得分:',rfc.score(xtest,ytest))#建立决策树模型
clf = DecisionTreeClassifier() #实例化决策树模型
clf1 = clf.fit(xtrain,ytrain) #训练数据
print('训练集得分:',clf.score(xtrain,ytrain))
print('测试集得分:',clf.score(xtest,ytest))
结果:
我们不给决策树模型和随机森林模型设置参数,可以看出随机森林的测试集得分比决策树测试集得分高了0.13,因此可以看出来随机森林和单棵决策树的差距。
混淆矩阵
from sklearn.metrics import confusion_matrix #导入混淆矩阵
print('决策树模型测试集的混淆矩阵:',confusion_matrix(ytest,clf.predict(xtest)))
print('随机森林模型测试集的混淆矩阵:',confusion_matrix(ytest,rfc.predict(xtest)))
混淆矩阵:

这是一个二分类的混淆矩阵,混淆矩阵的对角线就是分类正确的样本,FP就是本来就反例的样本被分为了正例,FN就是本来是正例被分为了反例。(混淆矩阵以后会详细讲一章,这儿不细讲)
决策树分类的混淆矩阵:
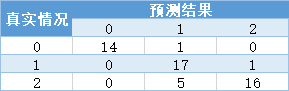
随机森林分类的混淆矩阵:

从混淆矩阵也可以明显看出随机森林模型的分类能力强于决策树的分类能力。
代码整合
from sklearn.datasets import load_wine #导入sklearn自带红酒数据集
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.decomposition import PCA
from sklearn.metrics import confusion_matrix #导入混淆矩阵
import matplotlib.pyplot as plt
import pandas as pd
import numpy as npwine = load_wine() #实例化红酒数据集
#因为数据是用字典保存的因此可以采用.键的模式取出数据
x = wine.data #特征矩阵
y = wine.target #标签(三分类)#建立随机森林分类模型
#将数据集分成训练集70%,测试集30%
xtrain,xtest,ytrain,ytest = train_test_split(x,y,test_size=0.3)rfc = RandomForestClassifier() #实例化随机森林分类模型
model = rfc.fit(xtrain,ytrain) #训练随机森林分类模型
print('训练集得分:',rfc.score(xtrain,ytrain))
print('测试集得分:',rfc.score(xtest,ytest))#建立决策树模型
clf = DecisionTreeClassifier() #实例化决策树模型
clf1 = clf.fit(xtrain,ytrain) #训练数据
print('训练集得分:',clf.score(xtrain,ytrain))
print('测试集得分:',clf.score(xtest,ytest))pca = PCA(n_components=2) #主成分分析将特征矩阵降成二维
x_dr = pca.fit_transform(x) #导出降维后的矩阵
print(pca.explained_variance_ratio_.sum()) #导出可解释性方差#创建混淆矩阵
print('决策树模型测试集的混淆矩阵:',confusion_matrix(ytest,clf.predict(xtest)))
print('随机森林模型测试集的混淆矩阵:',confusion_matrix(ytest,rfc.predict(xtest)))plt.figure()
plt.scatter(x_dr[y==0,0],x_dr[y==0,1],label=wine.target_names[0])
plt.scatter(x_dr[y==1,0],x_dr[y==1,1],label=wine.target_names[1])
plt.scatter(x_dr[y==2,0],x_dr[y==2,1],label=wine.target_names[2])
plt.legend()
plt.show()
总结
欢迎大家指出其中的问题,能够让我更好的去完善。
请大家尊重劳动结果,本博客不允许转载!!!
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!