动态网站爬取
在互联网散步的时候,无意发现了一个网站https://www.cosersets.com/
进去一看,是个图片网站


好家伙啊,居然是个妹子图片网站![]()
这么好的东西,不得保存下来,我把网页大概翻了一下,约摸者得有上万张图片,这要是手动保存,不得保存到猴年马月。
于是打算用python自动爬取下来,先Ctrl+U看看源码
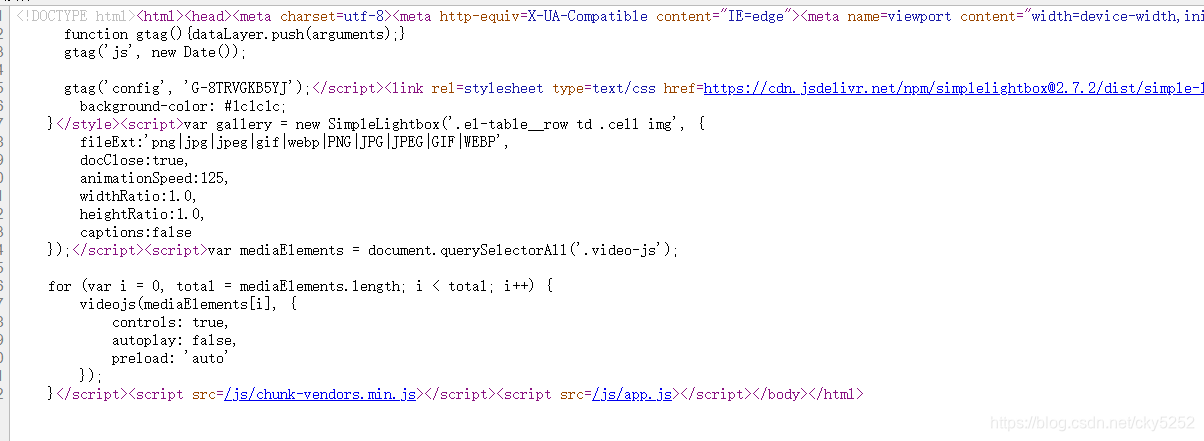
这源码,应该是一个动态网站。python单纯get请求只能返回来这份源码,js脚本应该无法正常解析。
看一下检查,元素里面的东西,这个是解析过js,最终网页呈现的效果

图片class里面src写了图片的源地址,尝试直接访问,发现可以访问到图片。
细细观察了一些,发现图片的排布是0001.webp、0002.webp、0003.webp......以此类推
我有了一个最基本的设想,通过访问文件系统的网站,来爬取图片
import urllib.request
import urllib
from bs4 import BeautifulSoupdef SelectUrl(url, a):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}ret = urllib.request.Request(url, headers=headers)page = urllib.request.urlopen(ret)logofile = page.read()with open(a + ".webp", "wb") as file:file.write(logofile)# print(ret)# page = urllib.request.urlopen(ret)# contents = page.read()# soup = BeautifulSoup(contents, "html.par")# print(soup)poet_name = "Imouto(妹妹)"url_code_name = urllib.parse.quote(poet_name)
for i in range(1, 99):a = str(i).zfill(4)print("正在爬取图片" + a)try:SelectUrl("https://zfile.cosersets.com/file/1/Azami/"+url_code_name+"/" + a + ".webp", a)except:break
发现效果可行,这个Azami-Imouto(妹妹)图集图片被直接下载到了脚本目录下。
切到下一个图集
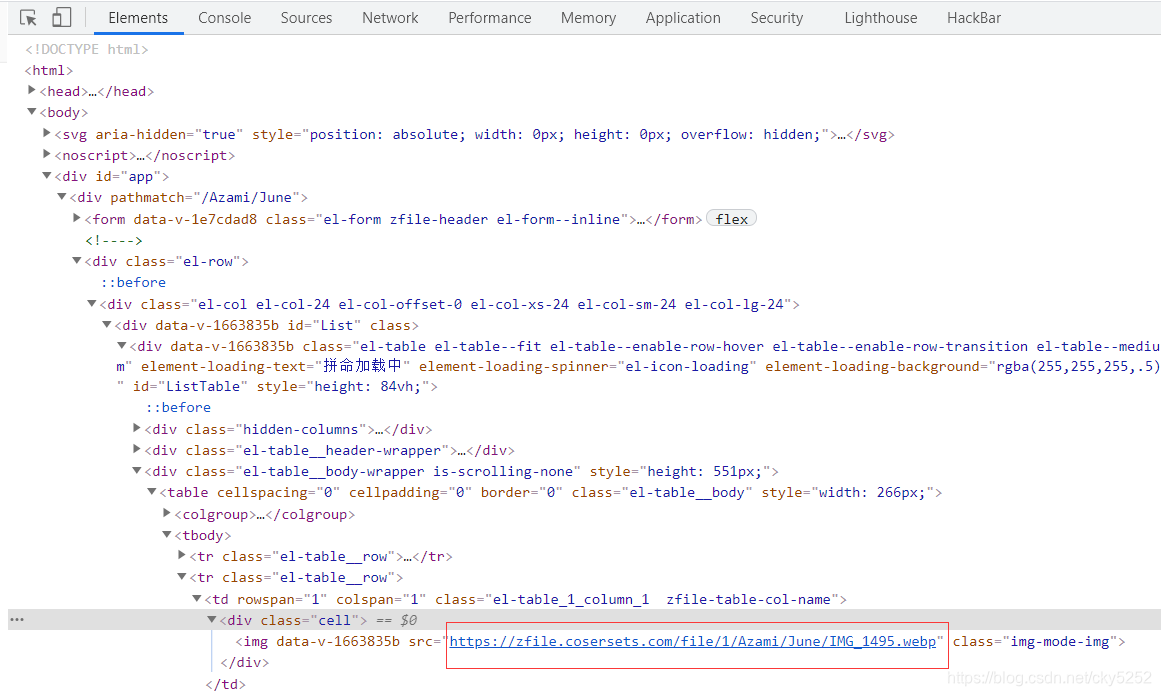
发现文件名变了,说明图片文件系统里面并没有把所有图片按规则排列。后面有些排列更乱

说明按规律下载不可行了,必须要读取动态网站的内容。
然而我并不会爬取动态网站。牛顿说过,我们是站在巨人的肩膀上,所以我百度到了这个
我又找到了两个网站,了解了selenium。
https://www.jianshu.com/p/87ab84828a5d
https://segmentfault.com/a/1190000015750160
OK,首先需要安装插件和驱动
pip install selenium
https://npm.taobao.org/mirrors/chromedriver/ chrome驱动
下面测试python驱动
driver = webdriver.Chrome()
driver.get(url)测试没问题,正常弹出浏览器。

不过selenium模块如何定位和读取呢
这里我用的是class名称定位的方法

存图片的class都叫 img-mode-img,
picture = driver.find_elements_by_class_name("img-mode-img")这样就定位到了图片class,读取这里我又卡住了,一开始我用以前写脚本用的读内容的.text,发现什么也读不到。但是,我翻到了这篇问答
 看到这我就明白了,写代码
看到这我就明白了,写代码
picture = driver.find_elements_by_class_name("img-mode-img")
for i in range(0, len(picture)):print(picture[i].get_attribute("src"))r = picture[i].get_attribute("src")SelectUrl(r)#函数参考前面图片直接存在和脚本一个目录总是没有那么优雅,所以我们需要让python创建一个目录
参考了这篇博客,得到了一个创建文件函数
https://www.cnblogs.com/monsteryang/p/6574550.html
上完整的代码
import time
import urllib
import urllib.request
import urllib.parse
import osfrom selenium import webdriverdef SelectUrl(purl):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}ret = urllib.request.Request(purl, headers=headers)page = urllib.request.urlopen(ret)fileName = page.info()['Content-Disposition'].split('filename=')[1]fileName = fileName.replace('"', '').replace("'", "")logofile = page.read()print(fileName)fileName="D:\\AllProject\\Python\\cosersets\\"+poet_name+"\\"+fileNameprint(fileName)with open(fileName, "wb") as file:file.write(logofile)def mkdir(path):# 去除首位空格path = path.strip()# 去除尾部 \ 符号path = path.rstrip("\\")# 判断路径是否存在# 存在 True# 不存在 FalseisExists = os.path.exists(path)# 判断结果if not isExists:# 如果不存在则创建目录# 创建目录操作函数os.makedirs(path)print(path + ' 创建成功')return Trueelse:# 如果目录存在则不创建,并提示目录已存在print(path + ' 目录已存在')return Falsepoet_name = "2B Shinobi"mkdir("D:\\AllProject\\Python\\cosersets\\"+poet_name)url_code_name = urllib.parse.quote(poet_name)
url = "https://www.cosersets.com/1/main/Azami/"+url_code_namedriver = webdriver.Chrome()
driver.get(url)
driver.implicitly_wait(30)
#time.sleep(5)
html = driver.page_source
picture = driver.find_elements_by_class_name("img-mode-img")
for i in range(0, len(picture)):print(picture[i].get_attribute("src"))r = picture[i].get_attribute("src")SelectUrl(r)
driver.quit()
测试没有问题,会自动创建一个文件夹,把图片放进去。
但是呢,一次只能下载一个图集,确实还不够自动,要是能让脚本自动跑完整个网站,那就完美了。
所以我们先读网页目录,先看如何定位
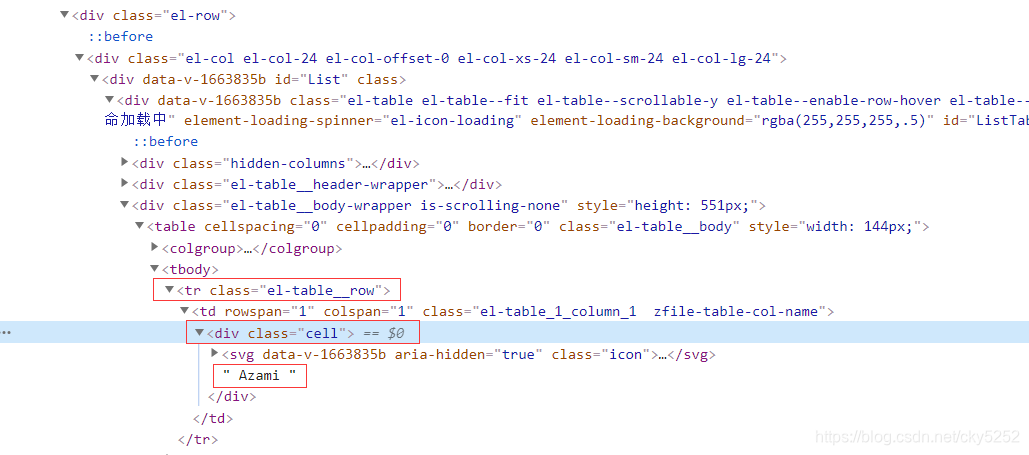
我最先想的是定位class="cell",但是测试后发现,class="cell"还有其他地方,如下图
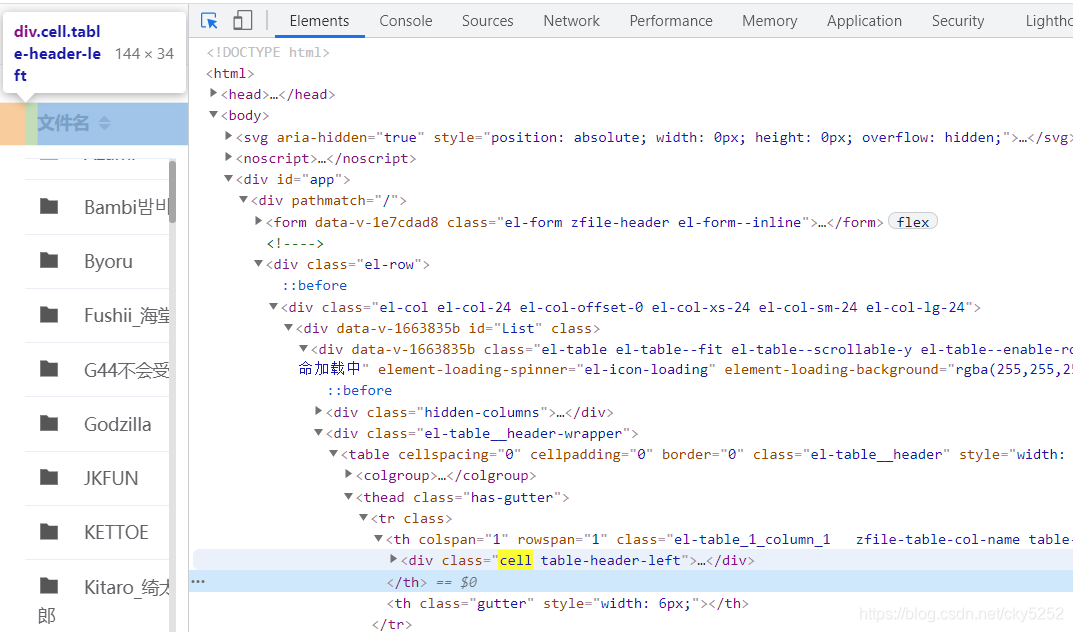
所以无法精准定位,我决定先定位大的,再定位小的
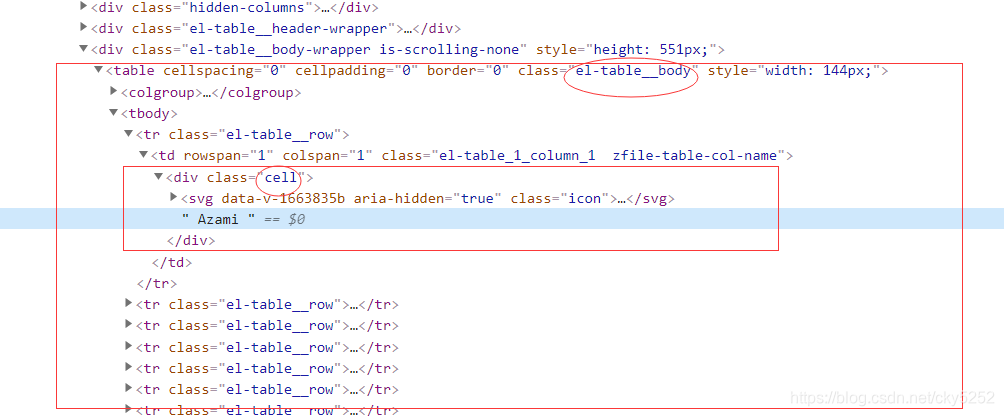
下一级目录以此类推,写出脚本
import timefrom selenium import webdriverurl = "https://www.cosersets.com/1/main"driver = webdriver.Chrome()
driver.get(url)
driver.implicitly_wait(30)
#time.sleep(5)
picture = driver.find_elements_by_class_name("el-table__row")
for i in range(0, len(picture)):picture = driver.find_elements_by_class_name("el-table__row")s = picture[i].find_element_by_class_name("cell")a=s.text#print(s.text)driver.get(url+a)picture2 = driver.find_elements_by_class_name("el-table__row")for i in range(0, len(picture2)):s2 = picture2[i].find_element_by_class_name("cell")print(s2.text)driver.back()driver.implicitly_wait(30)time.sleep(1)
测试后正常读出
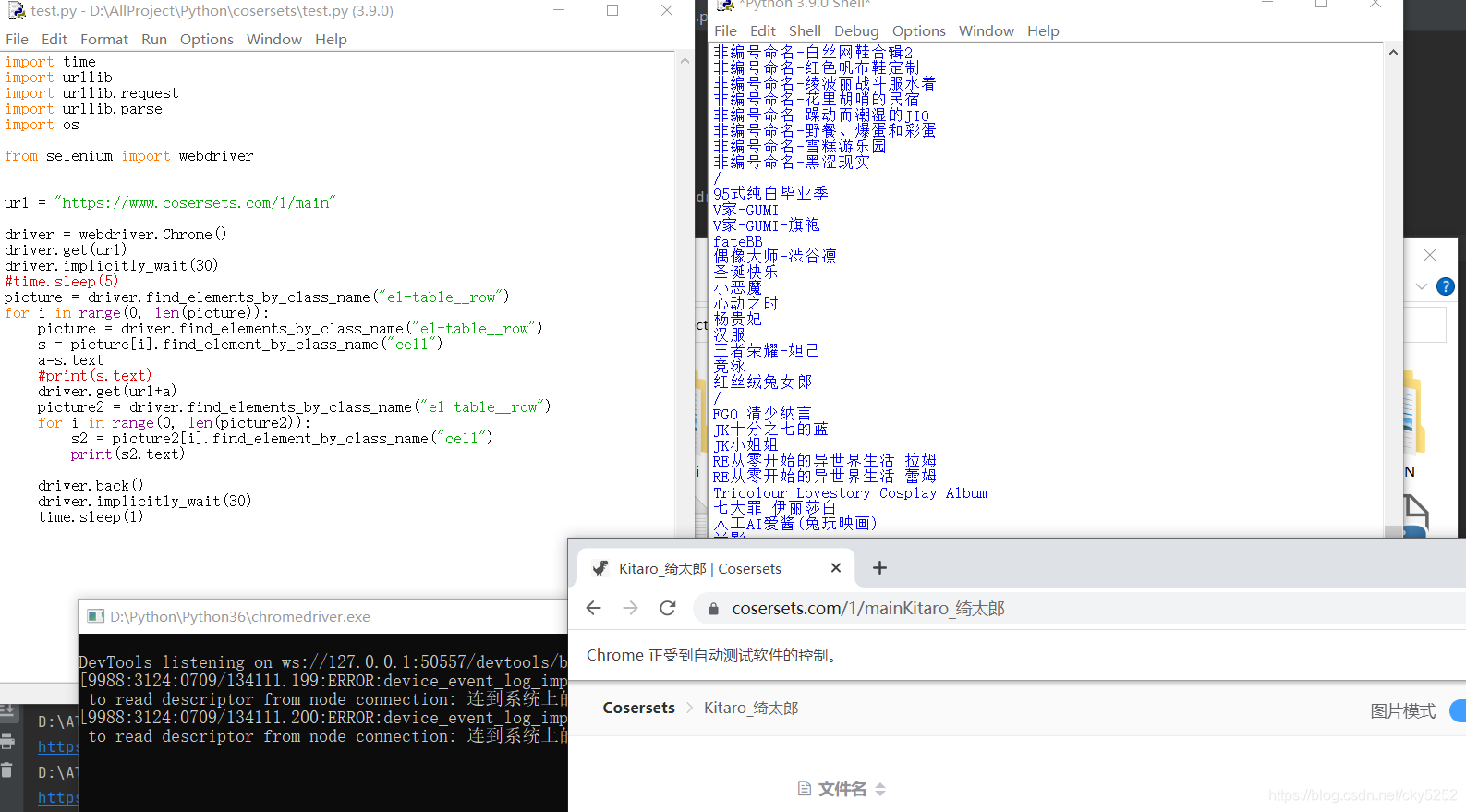
后门的任务就是写出遍历的逻辑,以及合适的延时把遍历出的目录和前面的下载相结合
这里我的逻辑是先到第一级目录读一遍,选一个然后通过get请求到下一级,再读一遍第二级目录,选一个进入图片界面,开始下载图片操作。
下载完成后,通过get请求到第二级,再另选一个图片界面进去,第二级全部完成后,再通过get请求到第一级目录。
完整代码
import time
import urllib
import urllib.request
import urllib.parse
import osfrom selenium import webdriverdef SelectUrl(purl):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}ret = urllib.request.Request(purl, headers=headers)page = urllib.request.urlopen(ret)fileName = page.info()['Content-Disposition'].split('filename=')[1]fileName = fileName.replace('"', '').replace("'", "")logofile = page.read()fileName = "D:\\AllProject\\Python\\cosersets\\" + name + "\\" + work+ "\\" + fileNameprint(fileName)with open(fileName, "wb") as file:file.write(logofile)def mkdir(path):# 去除首位空格path = path.strip()# 去除尾部 \ 符号path = path.rstrip("\\")# 判断路径是否存在# 存在 True# 不存在 FalseisExists = os.path.exists(path)# 判断结果if not isExists:# 如果不存在则创建目录# 创建目录操作函数os.makedirs(path)print(path + ' 创建成功')return Trueelse:# 如果目录存在则不创建,并提示目录已存在print(path + ' 目录已存在')return Falseurl = "https://www.cosersets.com/1/main"
driver = webdriver.Chrome()
driver.get(url)
driver.implicitly_wait(30)
time.sleep(0.5)name = ""
work = ""
NAME = driver.find_elements_by_class_name("el-table__row")
for i in range(0, len(NAME)):NAME = driver.find_elements_by_class_name("el-table__row")s = NAME[i].find_element_by_class_name("cell")name = s.text# print(s.text)driver.get(url + "/" + name)driver.implicitly_wait(30)time.sleep(3)WORK = driver.find_elements_by_class_name("el-table__row")for k in range(0, len(WORK)):WORK = driver.find_elements_by_class_name("el-table__row")s2 = WORK[k].find_element_by_class_name("cell")# print(s2.text)work = s2.textprint(name + " | " + work)if work == "/":continueelse:mkdir("D:\\AllProject\\Python\\cosersets\\" + name + "\\" + work)driver.get(url + "/" + name + "/" + work)driver.implicitly_wait(30)picture = driver.find_elements_by_class_name("img-mode-img")for j in range(0, len(picture)):print(picture[j].get_attribute("src"))r = picture[j].get_attribute("src")SelectUrl(r)#time.sleep(0.25)driver.get(url+ "/" + name)#driver.back()driver.implicitly_wait(30)time.sleep(3)driver.get(url)# driver.back()driver.implicitly_wait(30)time.sleep(3)driver.quit()
部分运行结果

美中不足的地方:
没有处理异常(主要是不知道如何处理异常又能不少图片,正常处理异常跳过就会少图片)
个别图集还有第三级目录,脚本无法正常识别,就会跳过
网站访问速度不是很快,不知道是我的网的问题还是服务器问题,下载图片的速度大约再1秒多一张。而且多线程优化似乎没有用,一个在下载,另一个就会卡。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!