编译原理课内实验报告(词法分析、简单赋值语句的语法分析)
这是笔者在whut选修的编译原理课程的课内实验(含实验报告)
实验内容包含:
(1)词法分析
(2)简单赋值语句的语法分析
温馨提示:本篇博客中的语法Syntax错误拼写成了Synax,请见谅!!
本次博客目录
- 一、实验要求
- 二、运行截图展示
- 三、代码说明
- 四、词法分析源程序
- 五、语法分析源程序
- 六、实验报告免费下载
- 七、Last but not least
一、实验要求
(1) 完成对C++语言的各类单词的词法分析程序设计。
实际实验时完成了对以下几种单词的分析:
1) 标识符(以字母或下划线开头的连续字符序列)
2)无符号数(包含小数)
3)关键字(如int ,include等)
4)界符(如 ; , 等)
5)运算符(包含复合运算符++,+=等)
(2)对于常用高级语言(如Java、C++语言)的赋值语句用所学过的语法分析方法进行语法分析。
本次实验简化了赋值语句的文法,简化后的文法如下:
文法:
1)<赋值语句>∷= 〈标识符〉 = 〈表达式〉
2) <表达式> ::= <项> <运算符> <项> | <项>
3) <项>::=<因子> <运算符> <因子> |<因子>
4)〈因子〉∷= 〈标志符〉|〈无符号整数〉|(〈表达式〉)
5)〈无符号整数〉∷= 〈数字〉|〈无符号整数〉〈数字〉
6)〈标识符〉∷= 〈字母〉|〈标识符〉〈字母〉|〈标识符〉〈数字〉
7)〈加法运算符〉∷= +|-
8)〈乘法运算符〉∷= *|/
二、运行截图展示
1.词法分析
本次实验从文件input_CStytle.txt文件中读取源程序,经过词法分析后的得到的结果以二元式的形式 <单词类型,单词值>。
其中单词类型包括:关键字keyword,界符boundary,运算符operator,数字digit,标识符token;单词值特殊说明:空格space,水平制表符tab,换行enter。


(2)语法分析
1)识别的赋值语句正确:variable_name+=str+cha4;
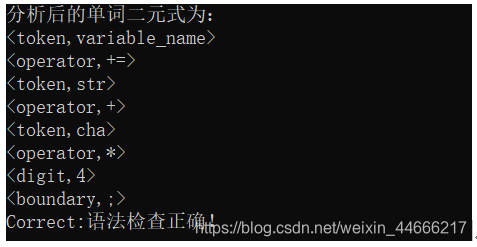
2)没有赋值符号的情况:variable_name+str+cha4;

三、代码说明
1.项目结构
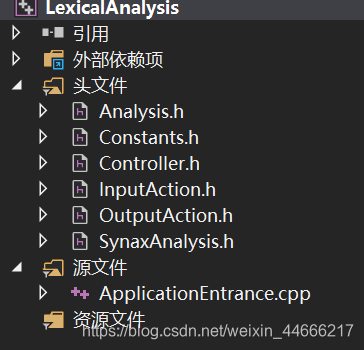
2.文件说明
ApplicationEntrance:程序入口
Controller:词法分析总控程序
Analysis:词法分析子程序
SynaxAnalysis:语法分析子程序(递归下降法)
OutputAction:输出相关操作
InputAction:输入相关操作
Constants:常量文件
3.输入文件等
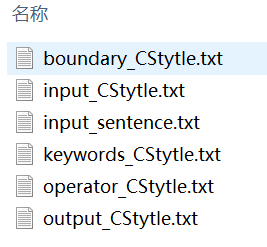
boundary_CStytle:界符文件
keywords_CStytle:关键字文件
operator_CStytle:操作符文件
input_CStytle:源程序输入文件
output_CStytle:输出文件
input_sentence:语法分析的赋值语句文件
上述文本文件可以根据自身需求自行定义
四、词法分析源程序
ApplicationEntrance:
/*
* @author W-nut
* FileInfo:应用程序入口
*/#include Controller:
/** @authot W-nut* FileInfo:词法分析总控程序*/#include Analysis:
/** @authot W-nut* FileInfo:分析子程序*/#pragma once
#include InputAction:
/** @authot W-nut* FileInfo:输入相关操作*/#pragma once#include OutputAction:
/** @authot W-nut* FileInfo:输出相关操作*/#pragma once
#include Constants:
/** @authot W-nut* FileInfo:全局变量、常量文件*/#pragma once#include 五、语法分析源程序
说明:语法分析与词法分析在同一项目中
SynaxAnalysis:
/** @authot W-nut* FileInfo:语法分析*/#pragma once
#include 六、实验报告免费下载
文件资源已上传,戳我直达,biubiubiu~

七、Last but not least
传说五大秘术:点赞、评论、分享、收藏、打赏!
mua~~
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!