Python3简单爬虫实战:爬取赶集网招聘岗位信息
爬取赶集网软件工程师岗位的招聘信息
-
爬取目的:
利用Python3爬虫来爬取赶集网的部分职业招聘信息并保存到CSV
Python的第三方库有很多,一般的爬虫学习中需要用到什么库再去学习所需库的语法,这样才记得牢固而且效率高,不会浪费时间在用不上的库的学习上
-
本次需要用到的库:
requests库:http://docs.python-requests.org/zh_CN/latest/
traceback库:https://yq.aliyun.com/ziliao/202818
beautifulsoup库:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
-
爬取网址:
http://gz.ganji.com/zpruanjiangongchengshi/zhaopin/o0/

-
爬取步骤分析:
第一步:
建议用谷歌浏览器打开网址,打开F12查看源代码,找到需要数据的源代码位置
tip:使用谷歌浏览器的好处在于便于复制需要数据所在的class类
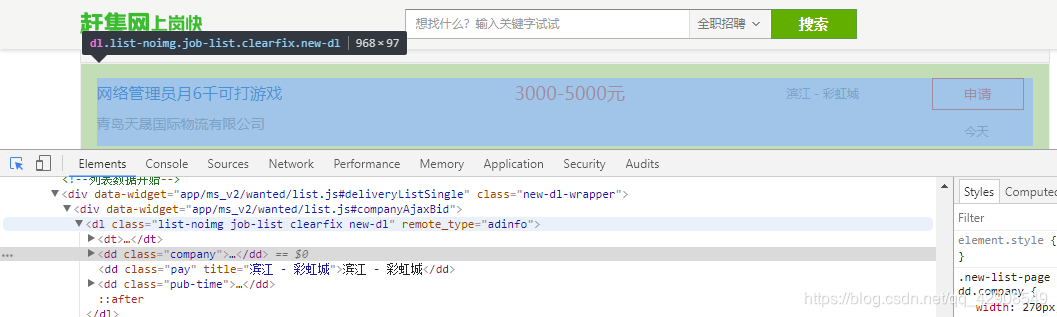 第二步:
找到所需数据所在的class类,用beautifulsoup库的函数提取里面的数据
因为这个网站没有反爬措施,所需数据都在网页源码中,并且没有使用ajax异步加载数据,所以爬取难度不大,下面附上代码:
-
爬取过程所有代码:
import requests
import csv
import traceback
from bs4 import BeautifulSoup as bs# 第一步先获取网页
def get_page():try:url = 'http://gz.ganji.com/zpruanjiangongchengshi/zhaopin/o0/'# 访问请求头headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}r = requests.get(url, headers=headers)r.encoding = r.apparent_encodingreturn r.textexcept:traceback.print_exc()return "爬取失败"# 第二步开始解析网页并找到所需信息
def get_page_parse(html):# 打开文件设置好格式csv_file = open('D:\\data.csv', 'wt', newline='')writer = csv.writer(csv_file)writer.writerow(['url', '公司', '地点', '时间', '福利', '职位', '薪水'])content = []# 开始解析网页源码,获取数据soup = bs(html, 'html.parser')for dl in soup.find_all('dl', class_='list-noimg job-list clearfix new-dl'):link1 = dl.find('a').get('post_url') # 爬取网页地址div = dl.find('div', class_="new-dl-company").find('a') # 爬取公司名称adress = soup.find('dd', class_='pay') # 爬取地址time = dl.find('dd', class_='pub-time').find('span') # 爬取发布时间for info in dl.find('div', class_="new-dl-tags").find_all('i'): # 爬取公司福利content.append(info.text)job = dl.find('a', class_='list_title gj_tongji') # 爬取职位salary = dl.find('div', class_='new-dl-salary') # 爬取提供的薪水writer.writerow([link1, div.text, adress.text, time.text, content, job.text, salary.text])csv_file.close()print('所有数据成功放入CSV中')# 主函数:
if __name__ == '__main__':html = get_page()get_page_parse(html)-
保存到CSV结果:

大致的步骤就是这样啦,本次爬取代码较简单,如有错误,欢迎指正!
嘻嘻,谢谢大家!!!
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!