【Pytorch相关】torch安装常见的问题和使用技巧
博主原文链接:https://www.yourmetaverse.cn/nlp/297/

torch安装常见的问题和使用技巧
1. torch的安装
1.1 虚拟环境创建
这个是为了避免不同的环境之间软件包的依赖版本差异所导致的安装问题,建议采用conda管理不同的虚拟环境,具体有关conda的操作可以参考博文anaconda介绍、安装及conda命令详解,如果有一些anaconda基础知识,可以直接跳到使用conda进行python环境管理或者conda常用命令介绍。本文以创建一个环境名为pytorch的python版本号为3.8为例,创建命令如下:
conda create --name pytorch python=3.8
然后使用conda激活环境:
conda activate pytorch
1.2 pytorch版本的选择
pytorch版本的选择需要依据系统安装的cuda版本和cudnn版本来选择,直接使用pip安装默认安装的cpu版本的最新版pytorch,大概率是要失败的。
(1)cuda版本查询
采用nvcc -V命令来查询cuda版本,例如:
用户名@主机名:~$ nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2020 NVIDIA Corporation
Built on Wed_Jul_22_19:09:09_PDT_2020
Cuda compilation tools, release 11.0, V11.0.221
Build cuda_11.0_bu.TC445_37.28845127_0
上面显示本系统的cuda版本是cuda11.0版本
或者使用以下命令也可以查询cuda版本:
cat /usr/local/cuda/version.txt
也可以使用nvidia-smi命令来查询,nvidia-smi命令的具体介绍可以参考nvidia-smi命令详解和一些高阶技巧介绍,如下:
用户名@主机名:~$ nvidia-smi
Tue Dec 6 11:01:19 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.172.01 Driver Version: 450.172.01 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 A100-SXM4-40GB On | 00000000:26:00.0 Off | 0 |
| N/A 26C P0 55W / 400W | 0MiB / 40537MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
上面CUDA Version后面跟着的就是cuda版本号。
(2)cudnn版本
cudnn里的include里只有cudnn.h的情况:
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
cudnn的include里有cudnn_version.h的情况:
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
(3)在pytorch官网找以前的版本
点击上面的链接进入pytorch官网后如下所示:
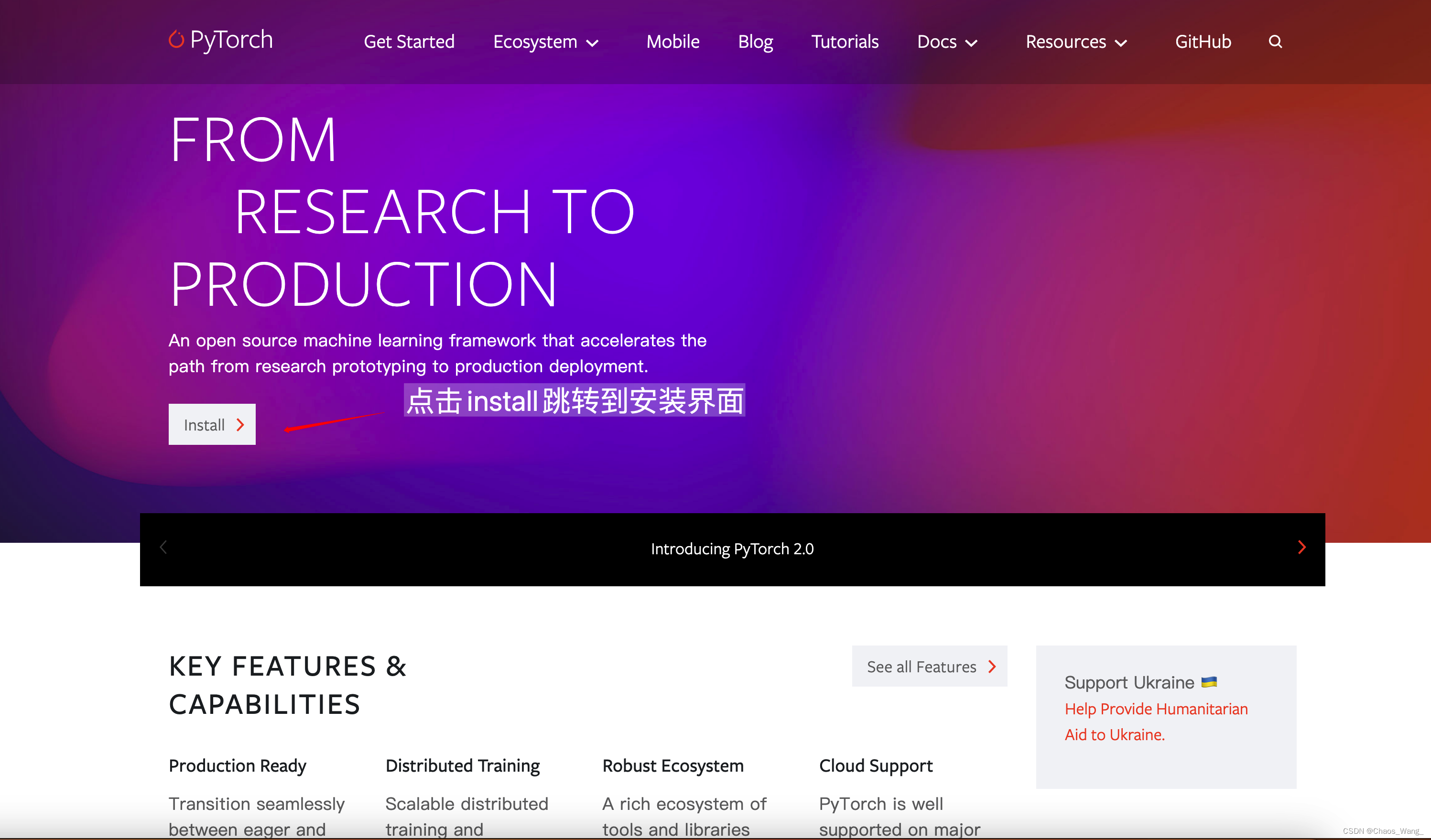
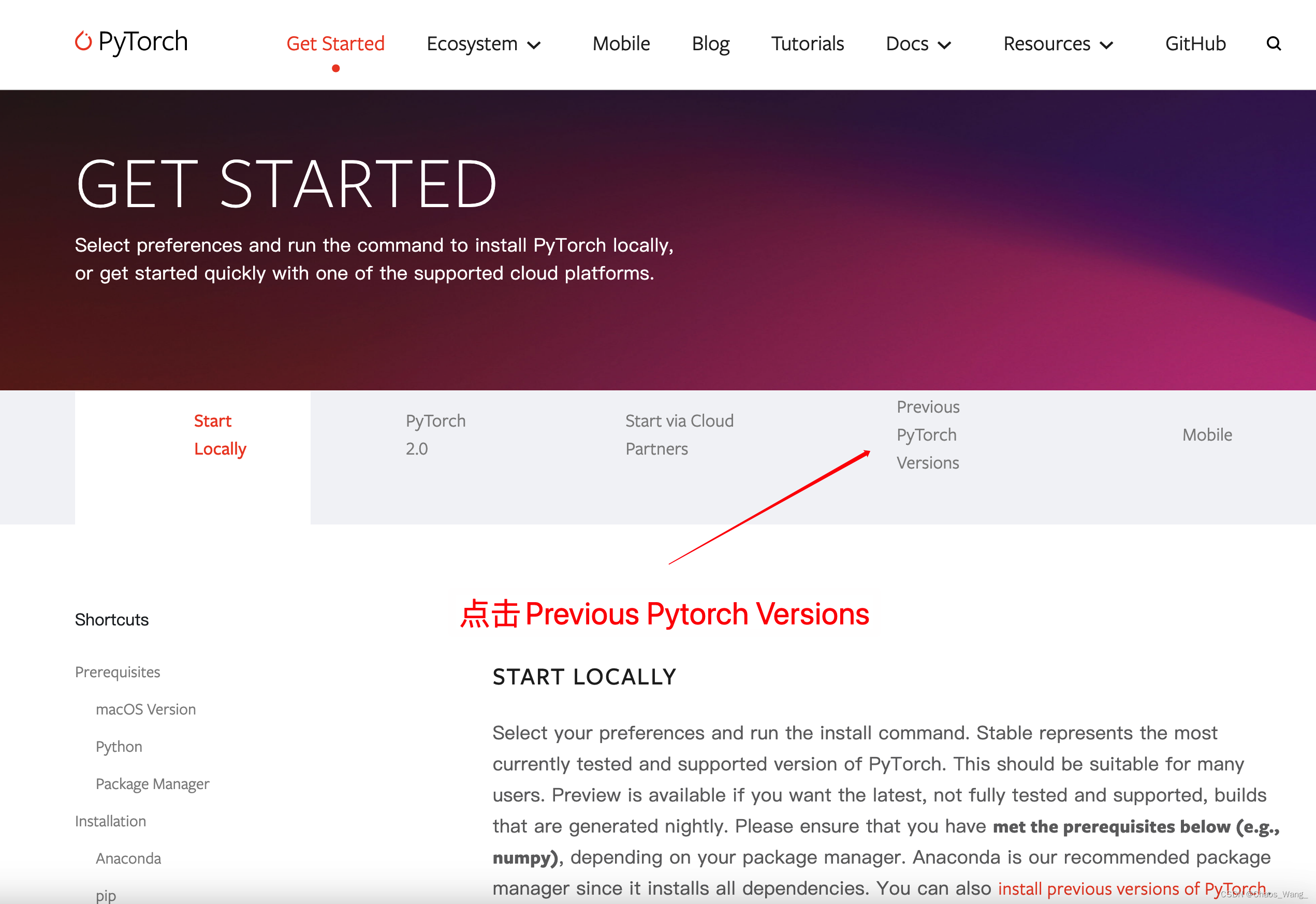
点击install跳转到安装界面,然后点击Previous pytorch versions。
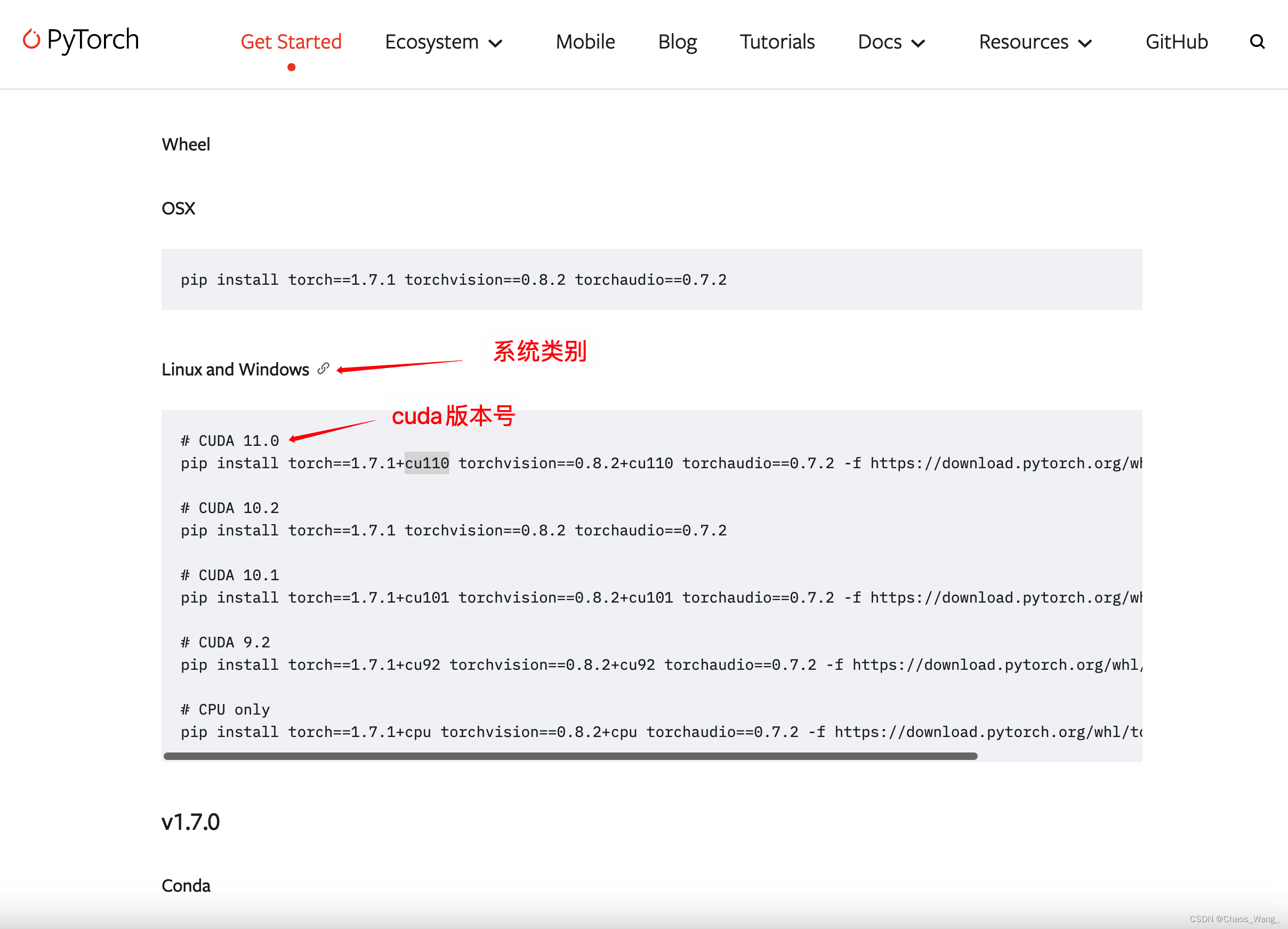
在下面的界面选择合适的pytorch版本复制安装命令安装即可,刚才查询到我的cuda版本是11.0,于是我选择了torch1.7.1版本进行安装。
1.3 pytorch安装常见的问题
-
安装依赖项失败:PyTorch有一些依赖项,如NumPy,CMake和Python,如果您的系统缺少这些依赖项,则可能导致安装失败。
-
CUDA驱动问题:如果您使用的是NVIDIA GPU来训练模型,则需要安装CUDA驱动程序。安装过程可能会因为版本不兼容等问题而失败。
-
安装版本不兼容:PyTorch的不同版本之间可能存在不兼容性,因此在安装PyTorch时,请确保您正在安装与您的系统和其他库兼容的版本。
-
安装包大小:PyTorch的安装包比较大,可能需要一定的时间才能下载和安装。在网络速度较慢或者磁盘空间不足的情况下,可能会出现安装失败或者安装过程中断的问题。
-
网络连接问题:在下载和安装PyTorch时,需要连接到网络。如果您的网络连接不稳定或者存在防火墙等限制,则可能导致安装失败。
-
Python版本不兼容:PyTorch要求使用Python 3.6或更高版本,如果您使用的是Python 2.x版本,则无法安装PyTorch。
-
操作系统不兼容:PyTorch支持多种操作系统,包括Windows、Linux和macOS等。如果您的操作系统不兼容PyTorch,则无法安装和使用PyTorch。
以下是这些常见问题的解决建议:
-
安装依赖项失败:确保您的系统中已安装所有必需的依赖项,如果缺少依赖项,则需要先安装它们。
-
CUDA驱动问题:确保您的GPU与所需的CUDA驱动程序版本兼容。您可以在PyTorch官方文档中查找所需的CUDA驱动程序版本。
-
安装版本不兼容:确保您下载和安装的PyTorch版本与您的系统和其他库兼容。您可以在PyTorch官方文档中查找所需的PyTorch版本。
-
安装包大小:尝试在更快的网络连接下下载和安装PyTorch。您可以在PyTorch官方网站中找到更快的下载链接。
-
网络连接问题:确保您的网络连接稳定,并且您没有受到任何网络限制。您可以尝试使用代理服务器来解决这个问题。
-
Python版本不兼容:确保您使用的是Python 3.6或更高版本。如果您使用的是Python 2.x版本,则需要升级到Python 3.x版本。
-
操作系统不兼容:确保您的操作系统与所需的PyTorch版本兼容。如果您的操作系统不兼容,则需要升级操作系统或选择其他操作系统。
2. 测试torch是否可以调用GPU
测试torch是否可以调用GPU,可以采用进入python环境输入以下命令:
import torch
torch.cuda.is_available()
3. pytorch使用过程中的一些技巧
(1)查看设备支持的GPU个数:
torch.cuda.device_count()
(2)查看当前GPU ID:
torch.cuda.current_device()
(3)获取device(设备ID)的计算能力和name:
torch.cuda.get_device_capability(device)
torch.cuda.get_device_name(device)
(4)清空程序占用的GPU资源:
torch.cuda.empty_cache()
(5)设置随机种子:
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
(6)固定训练的随机数种子:
def seed_everything(seed):random.seed(seed)os.environ['PYTHONHASHSEED'] = str(seed)np.random.seed(seed)torch.manual_seed(seed)torch.cuda.manual_seed(seed)torch.cuda.manual_seed_all(seed)torch.backends.cudnn.deterministic = Truetorch.backends.cudnn.benchmark = False
(7)其他常见问题和解决方法:
-
内存不足:如果您的模型或数据集较大,可能会导致内存不足。在这种情况下,可以使用PyTorch的数据加载器来批量加载数据,并使用GPU进行计算以减少内存使用。
-
梯度消失或爆炸:在训练神经网络时,可能会出现梯度消失或爆炸的问题,这可能会导致模型无法训练或者收敛速度很慢。这个问题可以通过使用不同的优化器、调整学习率或者使用梯度剪裁等方法来解决。
-
过拟合或欠拟合:在训练神经网络时,可能会出现过拟合或欠拟合的问题。这个问题可以通过使用更多的数据进行训练、增加正则化项、调整模型架构等方法来解决。
-
GPU资源不足:如果您的GPU资源不足,可能无法训练大型模型或批量处理大量数据。在这种情况下,您可以尝试使用分布式训练技术、使用更高效的算法或者选择更适合GPU的模型。
-
数据预处理错误:在训练神经网络之前,需要对数据进行预处理。如果数据预处理错误,可能会导致模型无法收敛或者产生错误的预测结果。在这种情况下,您可以检查数据预处理代码并进行调整。
-
模型保存和加载问题:在训练模型后,需要将模型保存到磁盘上以便以后使用。如果保存或加载模型时出现问题,则可能无法正确加载模型或者产生错误的预测结果。在这种情况下,您可以检查保存和加载代码并进行调整。
参考文献
[1] 查看cudnn版本号 https://blog.csdn.net/crazty/article/details/127762463
[2] torch.cuda命令查询 https://cloud.tencent.com/developer/article/1790469
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!