MIT-6874-Deep Learning in the Life Sciences Week2
MIT-6874-Deep Learning in the Life Sciences Week2
- What is Machine Learning
- Traditional Neural Networks
- How can we use gradients for optimization?
- How can we use gradients to train a deep neural network?
- What performance metrics should we use?
- Improving generalization
- 优化方案
- 控制模型能力方法
- a. 结构
- b. 提前结束网络
- c. 权重
- d. 噪声
- e. 先验分布:Prior distribution on params
- f. 残差分布
What is Machine Learning

什么是机器学习?
1997年 Mitchell给出的定义
if its performance at tasks in T, as measured by P, improves with experience E.
一段可以通过在T任务中的表现学习到经验E的计算机程序,其学习的准确性参照方法P可以提高.
(TOM M.Mitchell是卡内基梅隆大学的教授,讲授“机器(AAA)的主席:美国《Machine Leaming》杂志、国际机器学习年度会议(ICML)的创始人,其homepage)
使用术语对机器学习描述如下:
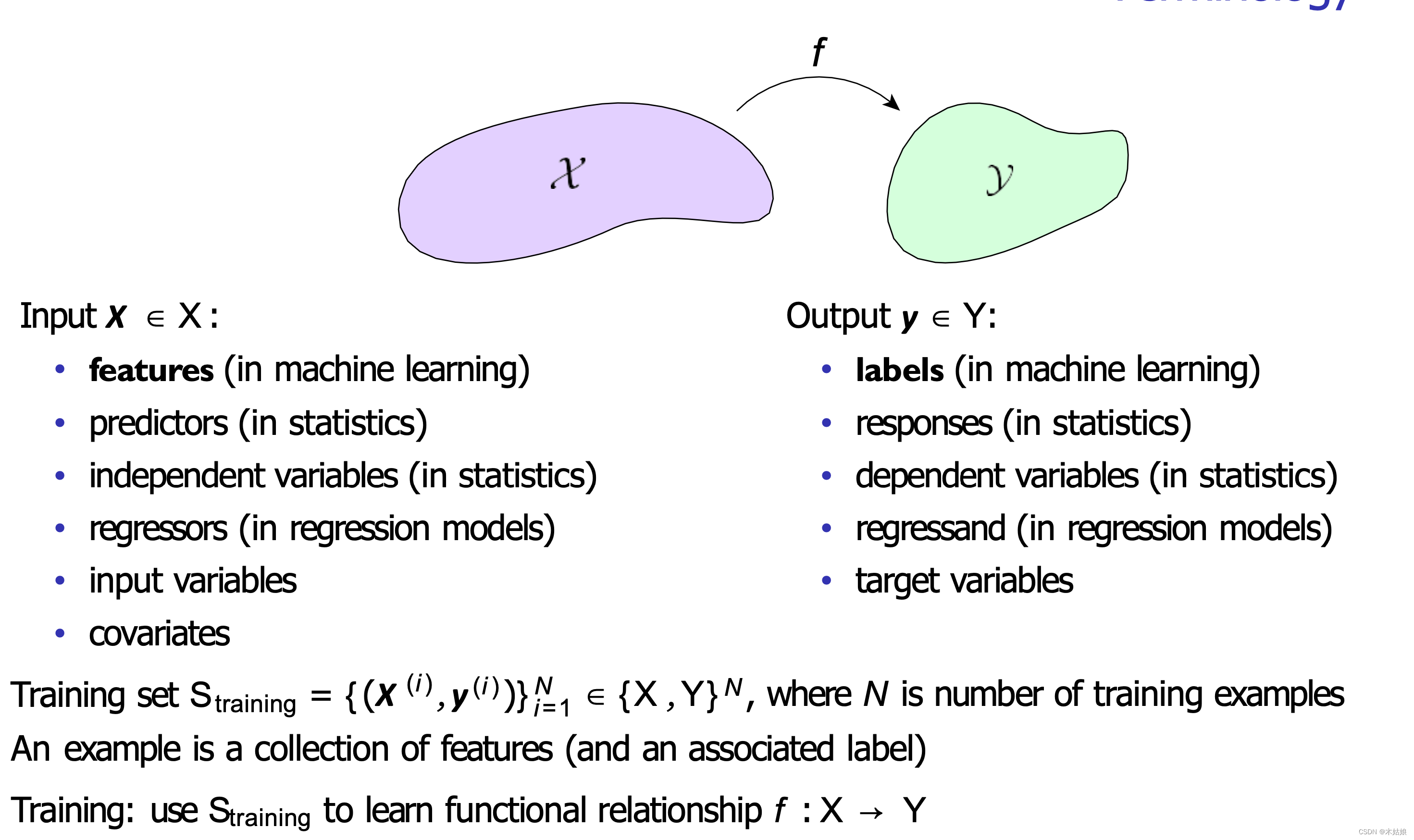
**目标函数J (Θ)是在训练机器学习模型时进行优化的函数。**它通常是(但不限于)下列一种或多种形式的组合:

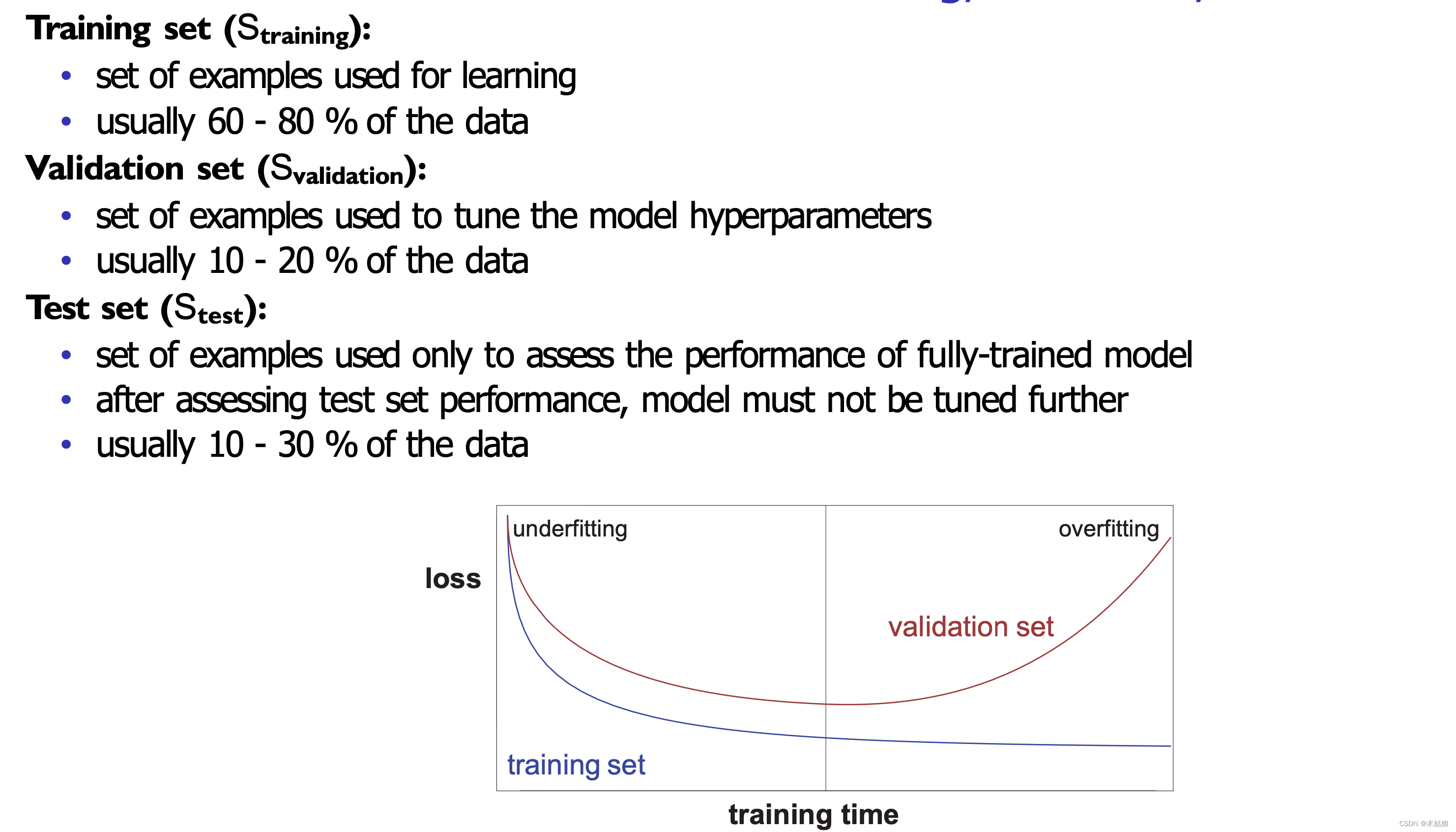
构造训练、验证、测试集的用途和常用的比例
机器学习的多重假设修正也很重要

Traditional Neural Networks
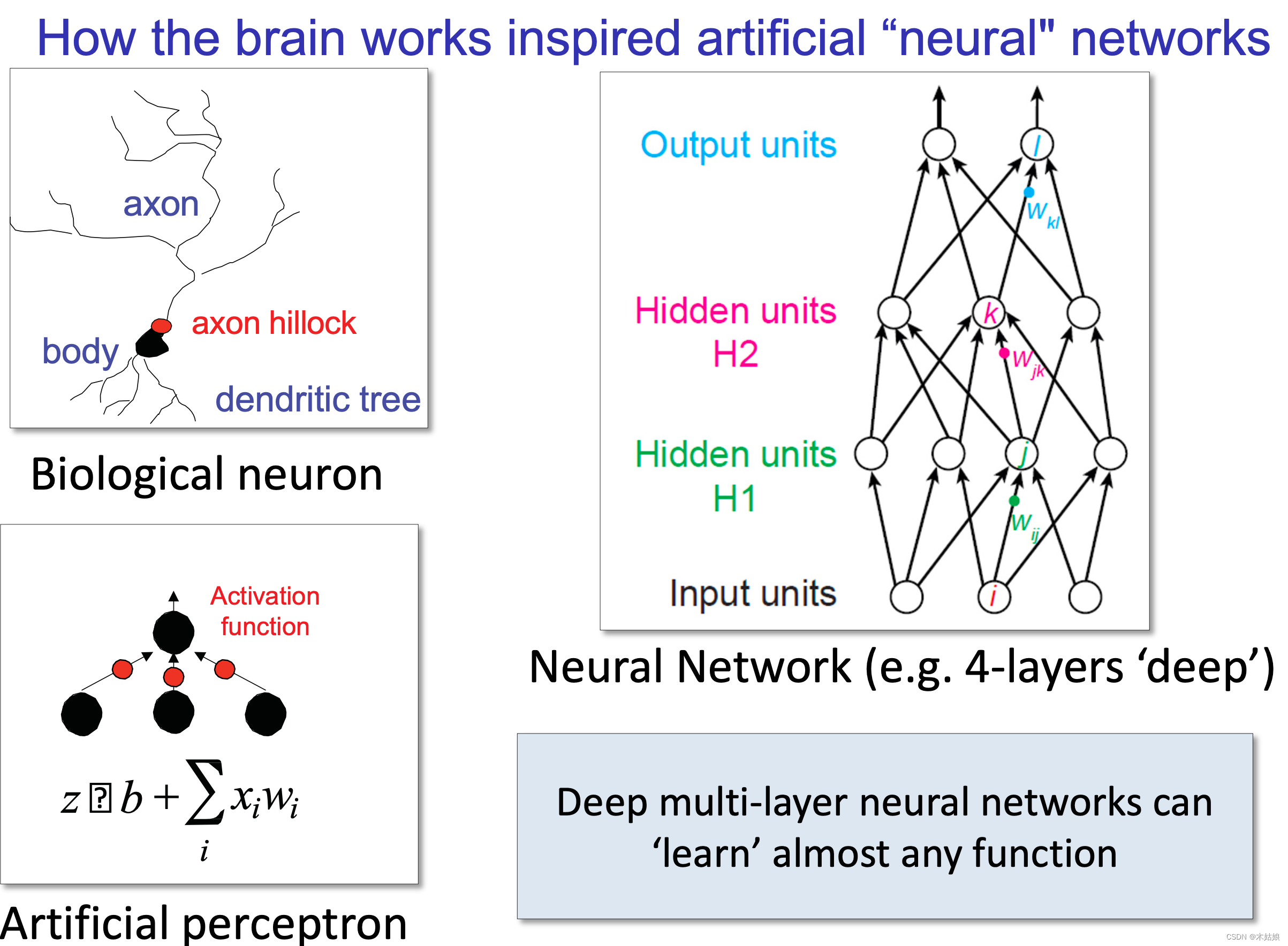
人类大脑工作方式是如何启发人工“神经”网络的
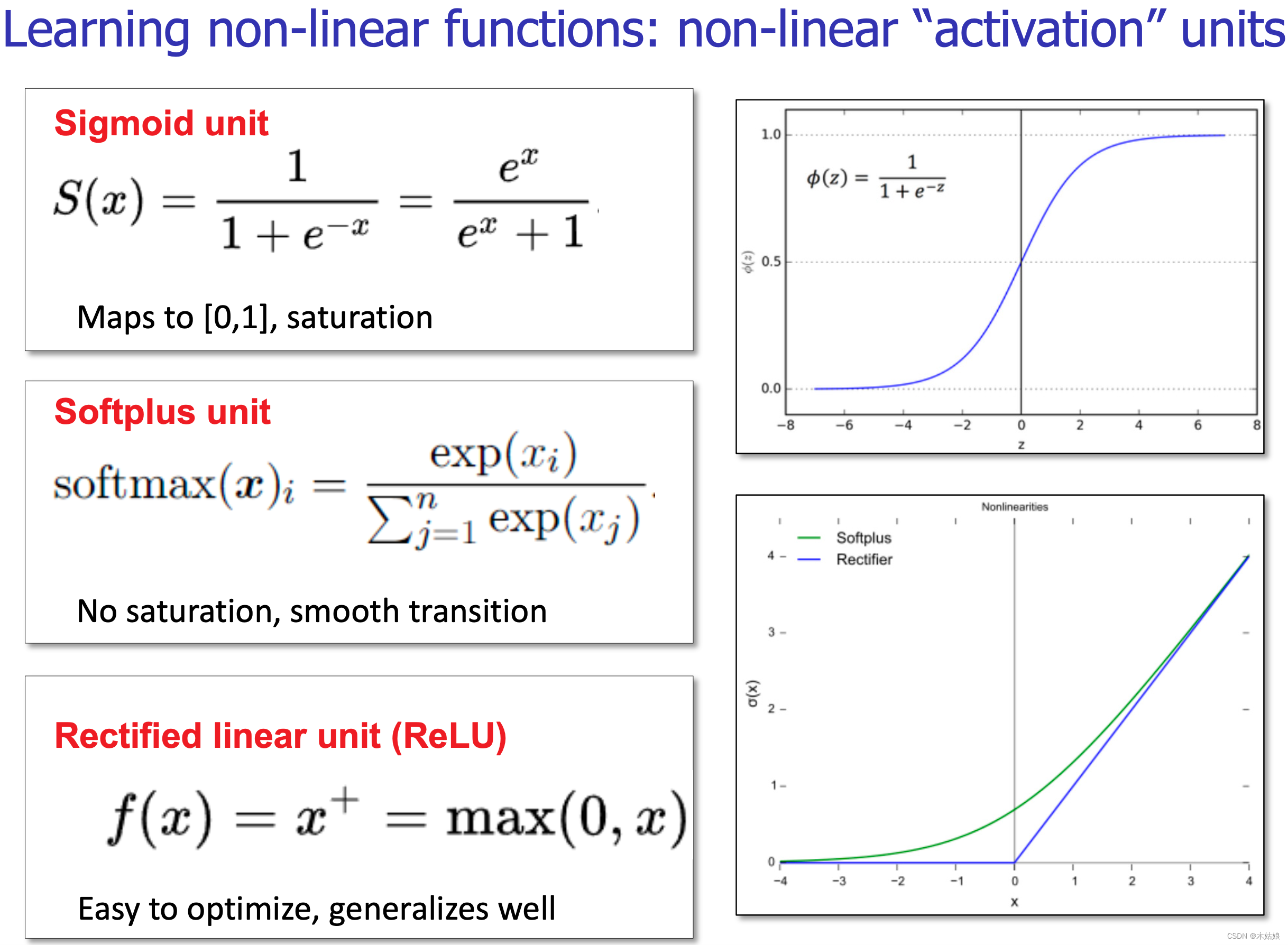
非线性层:激活函数
激活函数会作为每个隐藏层的输出
基于梯度的学习方式:使用导数更新权值

How can we use gradients for optimization?
一些常见的梯度优化方法

Gradient based optimization needs a loss function to minimize
How can we use gradients to train a deep neural network?
Deep neural networks are typically non-convex functions. We may not always find the best solution for non-convex functions
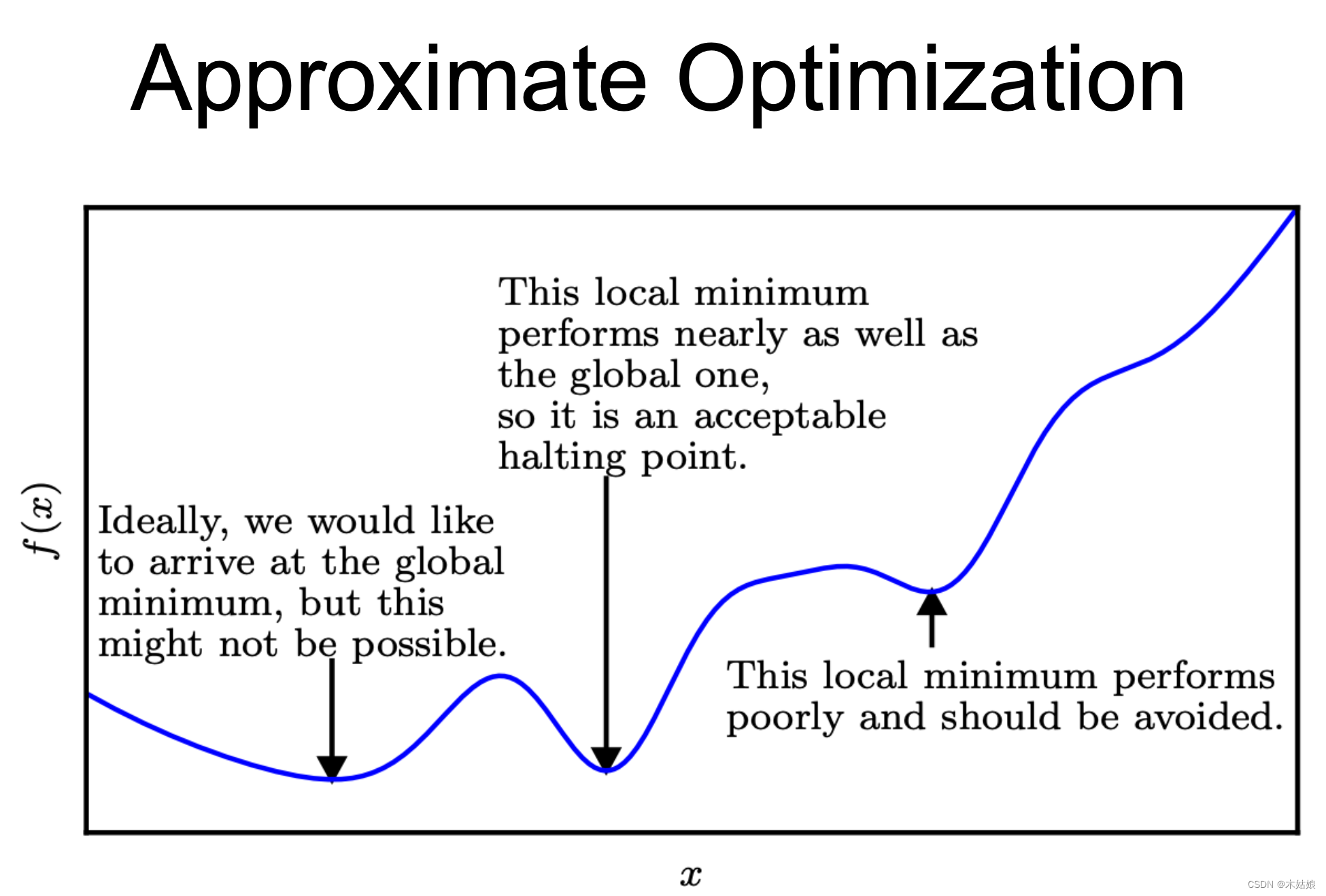
What performance metrics should we use?
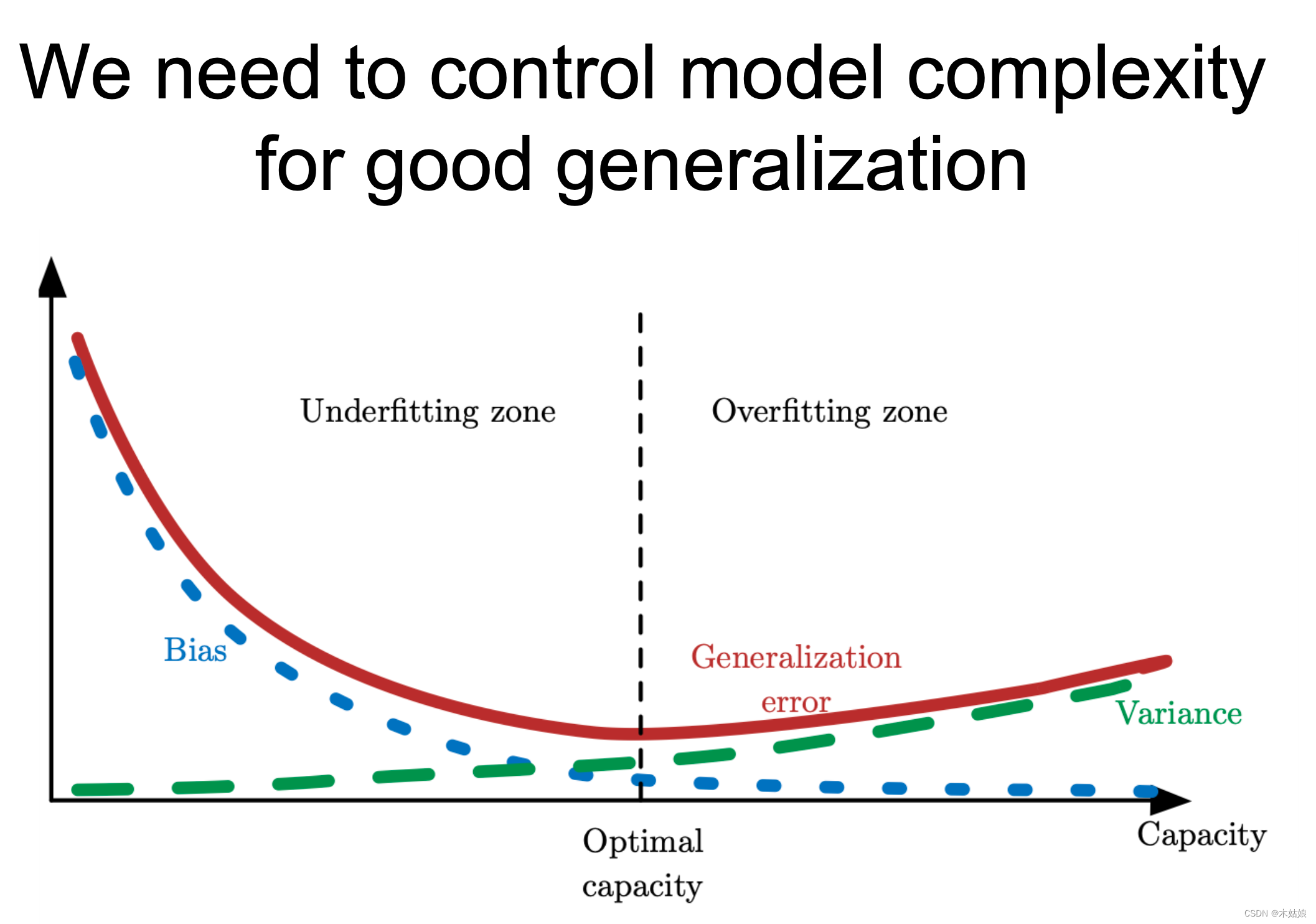
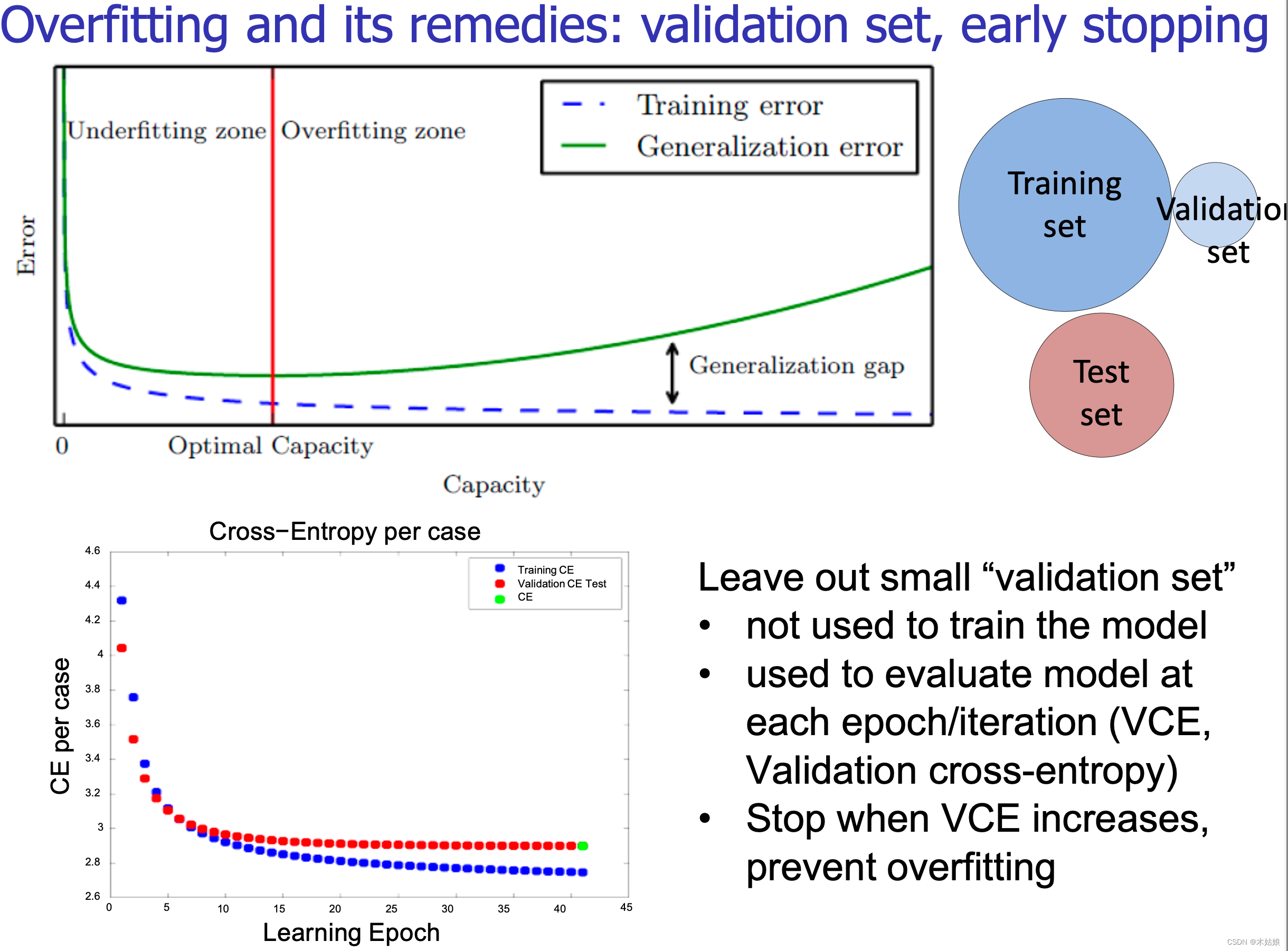

Improving generalization
一些会限制神经网络能力的问题

优化方案
控制模型能力方法
a. 结构


b. 提前结束网络

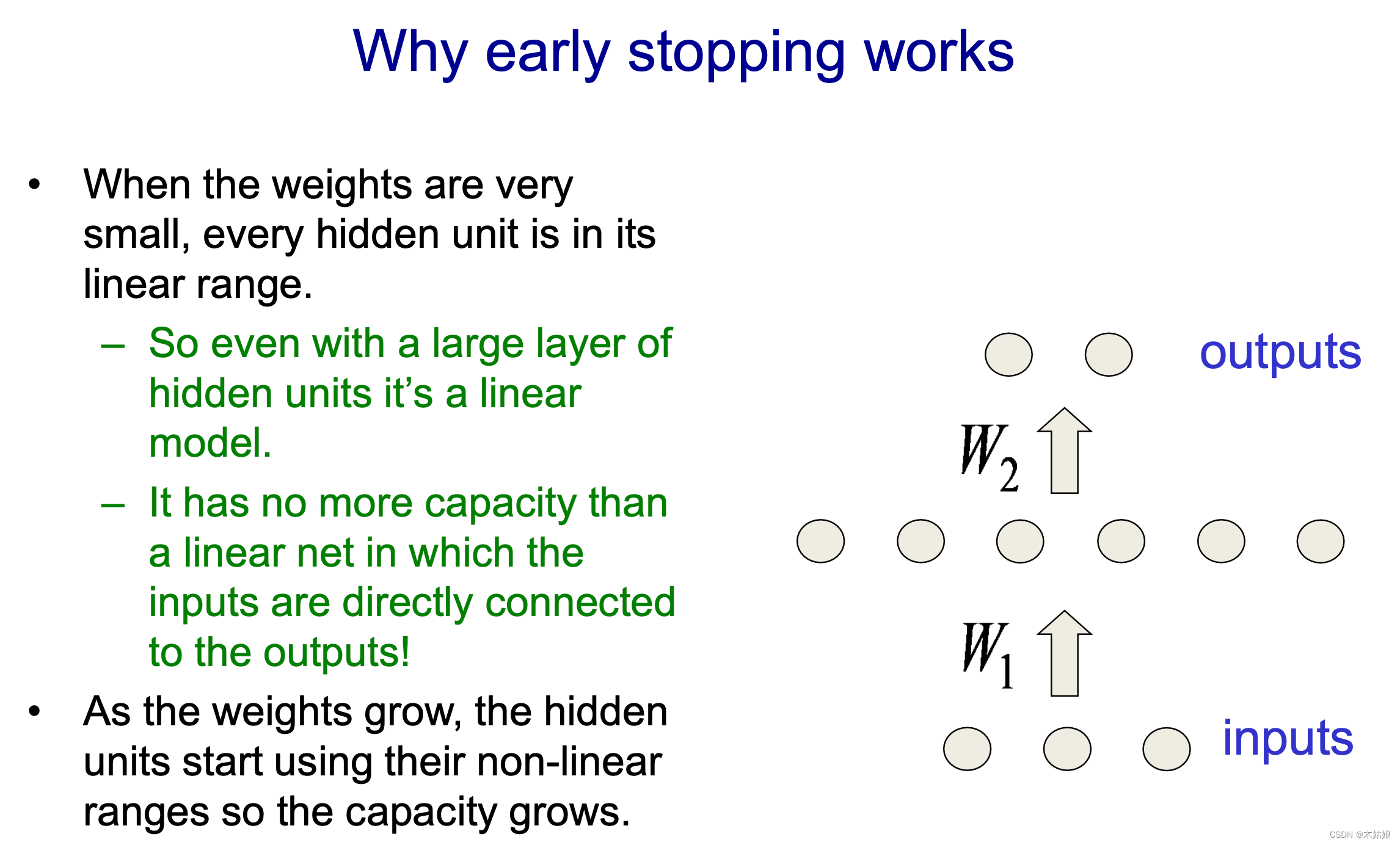
c. 权重

d. 噪声

e. 先验分布:Prior distribution on params
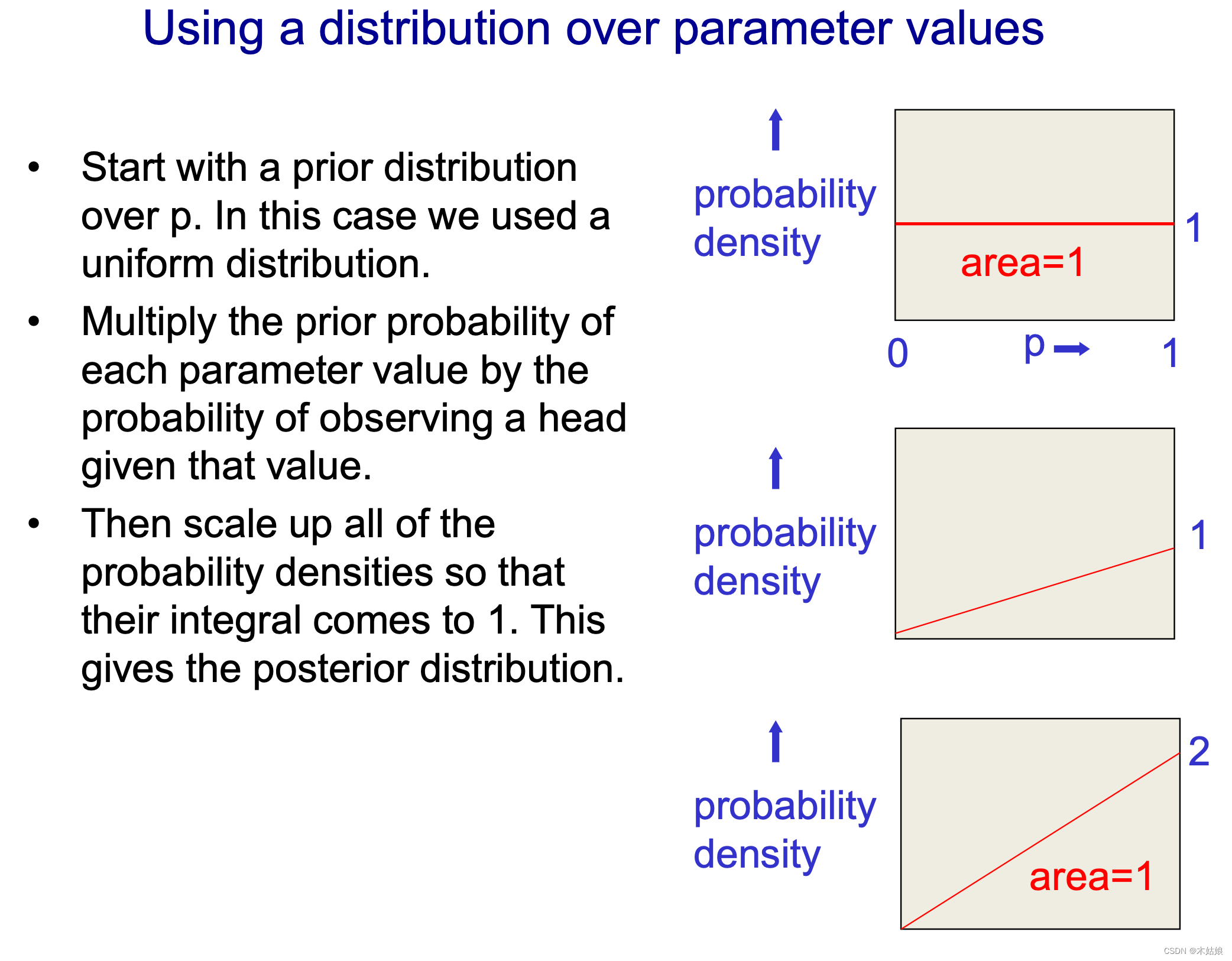
f. 残差分布

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!