API接入项目:oppo、vivo广告数据接入一条龙服务
目录
- 项目背景
- 项目流程图
- 技术总结
- 实现过程及代码解读
- 准备工作
- 发送请求,通信成功
- 获取所有数据,处理数据
- 保存至数据库
项目背景
作为一名游戏公司数据分析师,日常的数据主要还是来自于内部数据埋点上报。但是,如果涉及到投放,一些广告数据就需要涉及到调用对方的api接口,获取数据。而我,第一次接手(之前主要是数据开发工程师完成),算是过五关斩六将了。
本文档主要为了记录一次独立完成的外部数据接入项目。
项目流程图
技术总结
1、python基础知识
2、requests库、pandas库基础知识
3、数据库基础知识
实现过程及代码解读
准备工作
相关部门找到我,说想获取当前游戏的花费数据以及广告展示-点击-转化的数据,并友善的甩了2个api接口文档。以下为部分截图,全文字版,没有案例!
vivo:
oppo:
没办法,硬着头皮上吧,以oppo的接口为例,因为他们提供测试地址,方便调试。
发送请求,通信成功
思路类似于爬虫,但是规矩贼多。
import datetime
import requests #用于请求
import hashlib #用于加密
import base64 #用户转码
import time
import pandas as pd
import math# # 测试账号
# owner_id = '此处为给的owner_id'
# api_id = '此处为给的api_id'
# api_key = '此处为给的api_key'
sign_str = (api_id + api_key + time_str).encode('utf-8')
# 进行sha1 加密
#获取签名和token
sign = hashlib.sha1(sign_str).hexdigest()
token_str = owner_id + ',' + api_id + ',' + time_str + ',' + sign
# 进行bs64编码
token = base64.b64encode(token_str.encode())
# 统一用的头
header = {'Content-Type': 'application/x-www-form-urlencoded','Authorization': 'Bearer ' + token.decode()}
# 请求参数 (按文档要求的来)
params = {"timeLevel": "DAY", # 时间粒度"pageCount": 400, # 每页大小"beginTime": '20201021', # 开始时间"endTime": '20201023', # 结束时间"page": 1, # 页码# 'showStatus':0, #展示投放状态 启动中"ownerId": owner_id, # 广告主 ID'deleteFlag': 0, # 删除标识 未删除'auditStatus': 1 # 广告审核状态 审核通过}
url= 'http://sapi-ads-test.wanyol.com/v2/data/Q/ad/list'
date = datetime.date.today()
# date_diff = 0
date_str = date.strftime('%Y-%m-%d')
resp = requests.post(url=url, params=params, headers=header)
res = resp.json()
print('----------------',res)
通过各种查资料,不断调试,终于通了。因为是测试环境,所以很多字段没有值,但是走出了这个项目的第一步,可喜可贺。

获取所有数据,处理数据
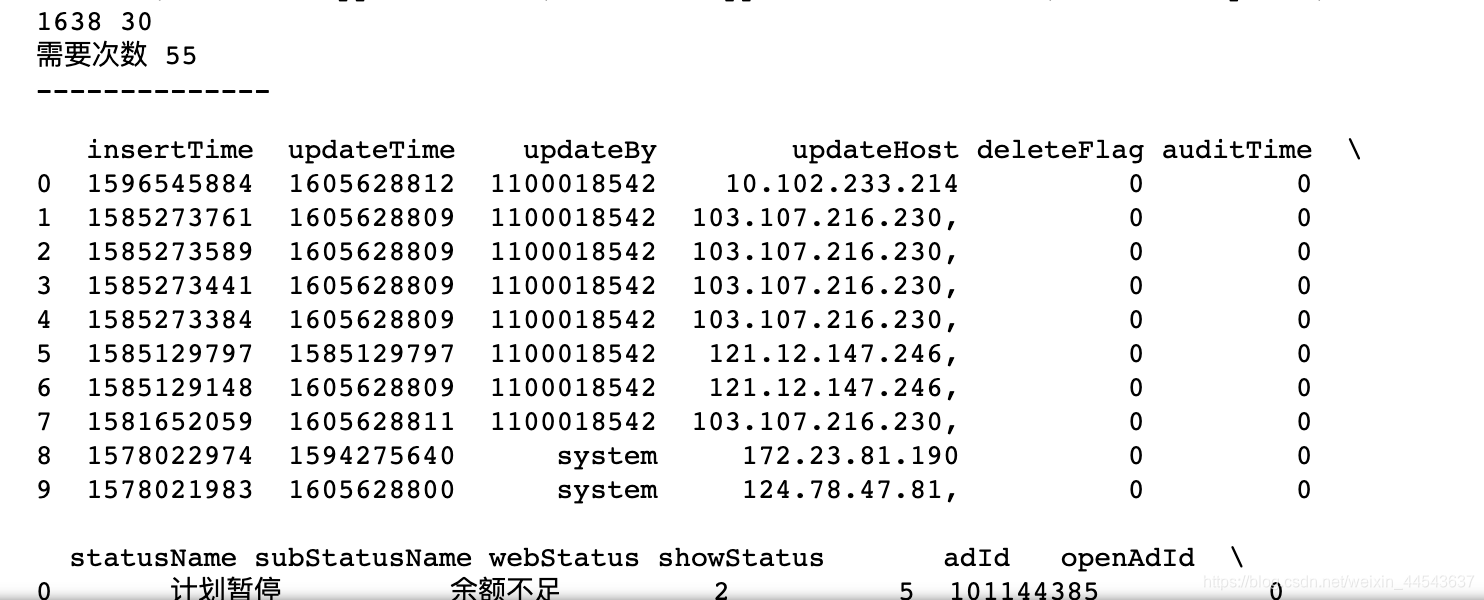
这里的主要麻烦是要获取多页数据,以及统一数据格式。这里的思路是分2部分获取数据,第一页和非第一页,以及做了一个dataframe的拼接。
def get_oppo_data():# 第一次resp = requests.post(url=url, params=params, headers=header)if resp.status_code == 200:# 拿到对应的json结果resp = requests.post(url=url, params=params, headers=header)res = resp.json()print('----------------',res)# totalCount 满足条件的总个数 itemCount 当前页的数量print(res['data']['totalCount'], res['data']['itemCount'])print('需要次数', math.ceil(res['data']['totalCount'] / res['data']['itemCount'])) # 次数需要向上取整# 第一页获得的内容df = pd.DataFrame.from_dict(res['data']['items'])print('--------------')# 取出多页数据# 一次只能取一页的数据下来,思路是把每页的数据取出,存成dataframe 然后拼接# df = pd.DataFrame.from_dict(res['data']['items'])pages = math.ceil(res['data']['totalCount'] / res['data']['itemCount'])for page in range(2, pages + 1):params['page'] = pageresp = requests.post(url=url, params=params, headers=header)res = resp.json()# res = resp # 转为dfdf_more = pd.DataFrame.from_dict(res['data']['items'])# 拼接frames = [df, df_more]df = pd.concat(frames)# 修改类型 为string#所有的列名c_list = df.columns.values.tolist()df[c_list] = df[c_list].astype(str)values = dfprint(values[:10])
保存至数据库
至此,数据基本获取到了,而且也转换成了我想要的格式,最后一步就是存到数据库了。
def get_oppo_data():.....此处为上一个代码框的代码# 传dataframe 到数据库impala_host = "你的数据库地址"impala_port = 你的数据库接口这是内部以已经封装好的impala = ImpalaHook(impala_conn_id='用户名')#这一步很关键,将dataframe转化成tuple,就可以一条条传入数据库了records = df.to_records(index=False)result = tuple(list(records))print(result)insert_sql = f""" insert into `库名`.表名values{result};"""impala.execute(insert_sql)print('done!!!!!!!!!!!')return values
OK,数据上传完毕,验证无误,可以做接下来的处理,做一些可视化报表。如果需要定时访问,可以开一个airflow任务定时执行代码。展示的话,我主要是用tableau,兼顾交互性和美观度。
分享到此结束,世上无难事,只怕有心人。需要相关文档和想试一试的小伙伴可以私我。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!