设计基础决定上层建筑之go函数语法糖
文章目录
- 函数
- 方法
- 闭包
- defer
- panic
- recover
以下截图均来自幼麟实验室,总结的比较形象,直接爱了
函数
- 只读代码段
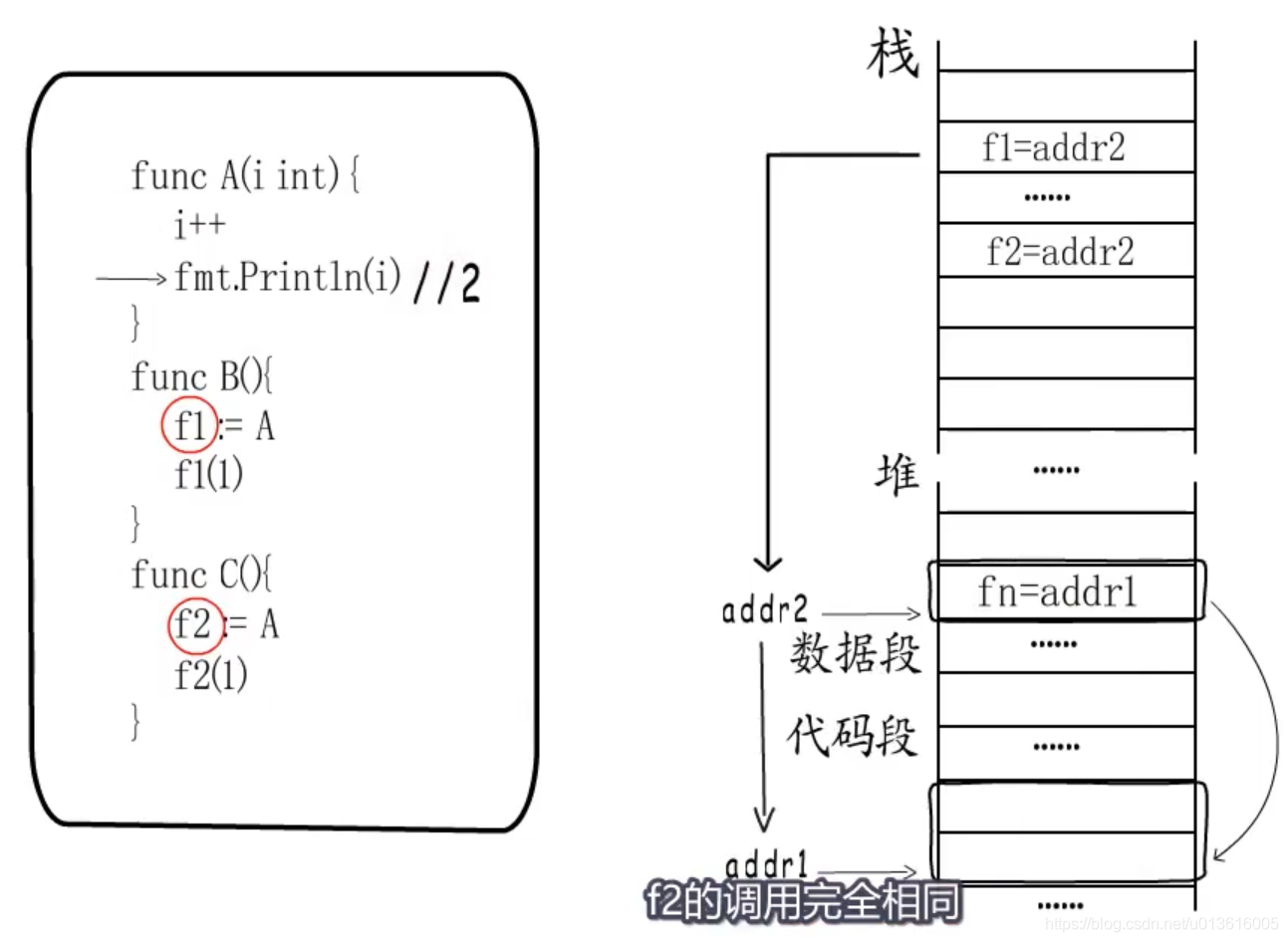
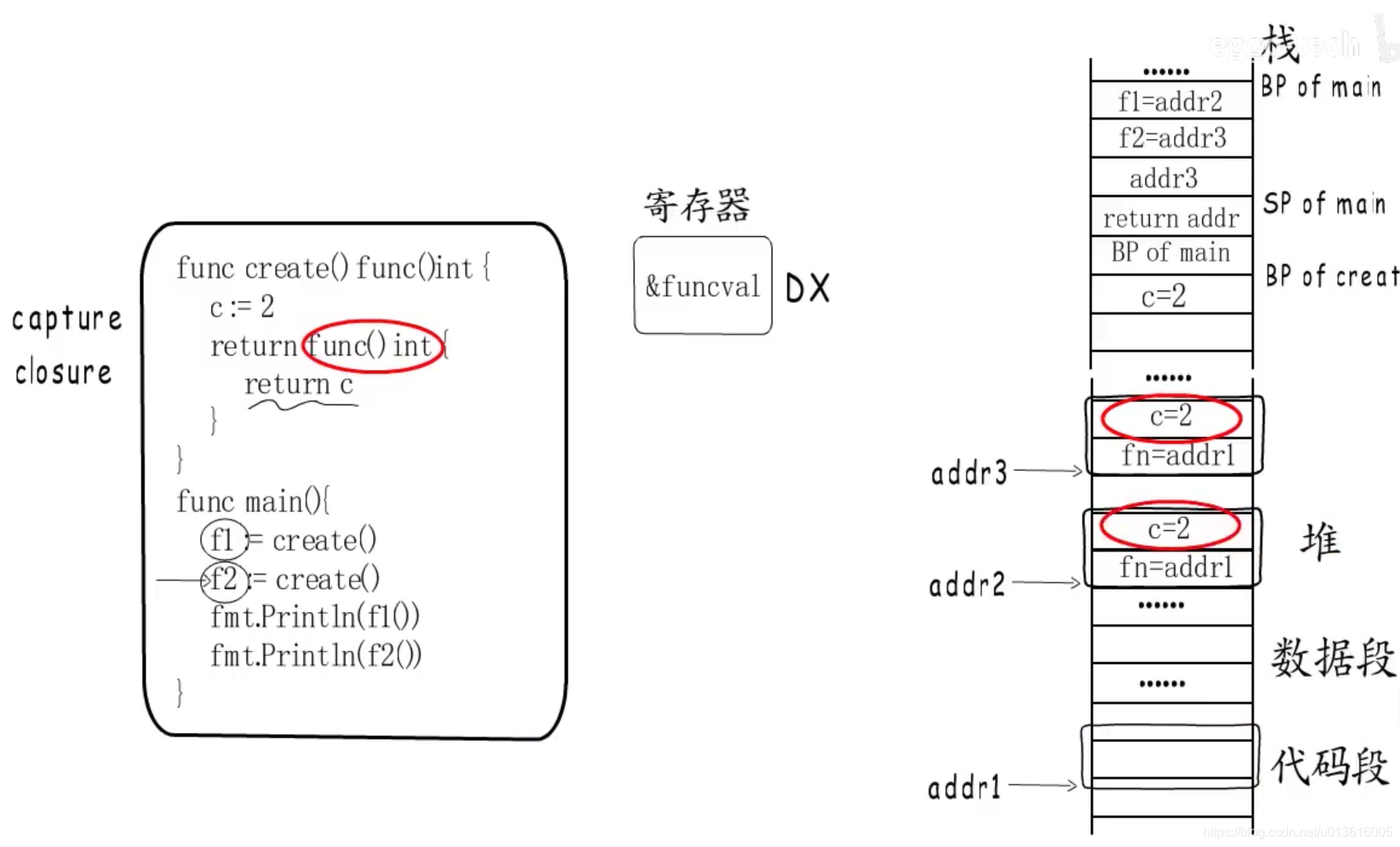
1、
编译阶段会在只读数据段分配一个funcval结构体,指向addr1
2、而它本身的地址为addr2,会在执行阶段赋给f1、f2
3、执行阶段f1通过addr2存储的地址找到对应的funcval结构体,拿到函数入口地址,然后跳转执行
4、既然只要有函数入口地址就能调用,为什么要通过funcval结构体包装这个地址呢?然后使用一个二级指针来调用呢?主要是为了处理闭包的情况
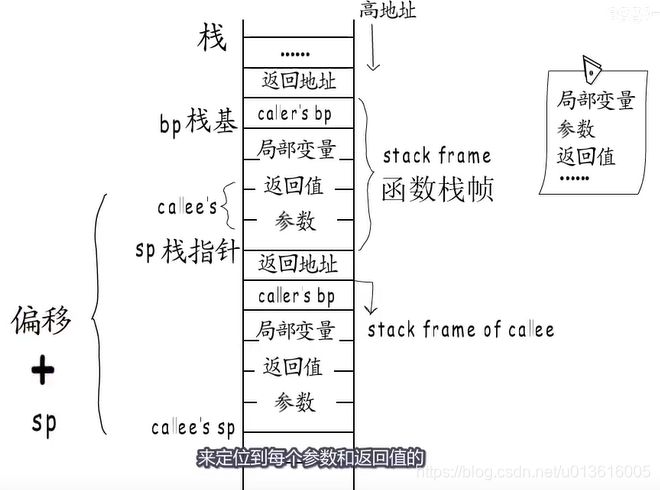
- 函数调用的栈帧分配情况
- go语言中栈指针是
一次性分配所需最大栈空间的位置,为了避免访问越界,编译期间确定;- 然后通过
栈指针加偏移值这种相对寻址方式使用函数栈帧
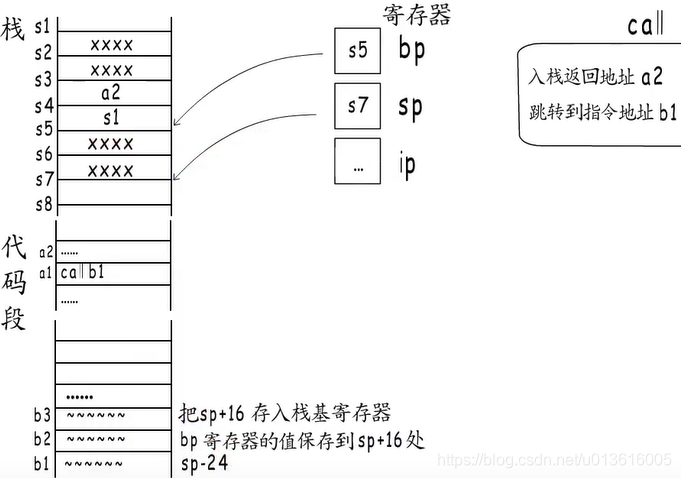
- 调用流程:
函数通过call指令实现跳转
每个函数开始时会分配栈帧
结束前又会释放自己的栈帧
ret指令又会把栈恢复到call之前的样子
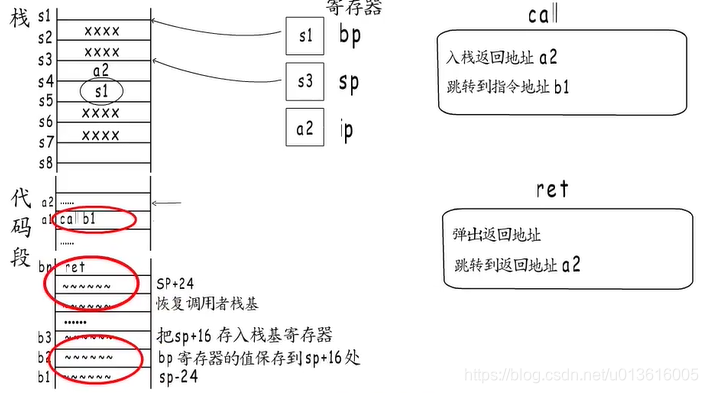
- 函数调用
返回值情况
通常我们认为函数返回值是通过
寄存器传递的
但是,如果要返回值个数比寄存器还多的话,在栈上分配返回值空间更合适
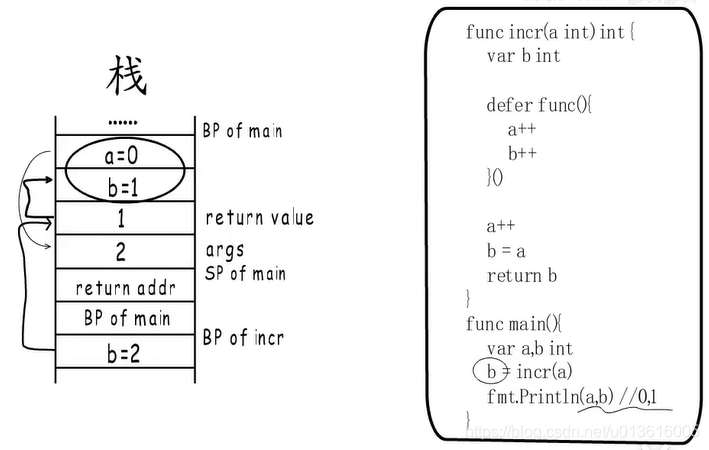
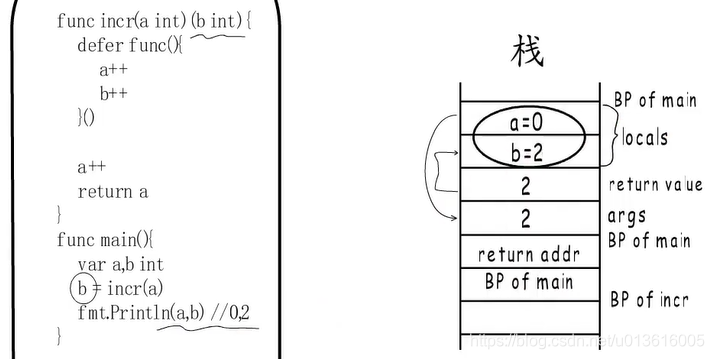
- 这个太重要了,单列:
函数有返回值的情况会
先把局部变量的值拷贝到返回值空间,然后再执行注册的defer函数(匿名、非匿名)
方法
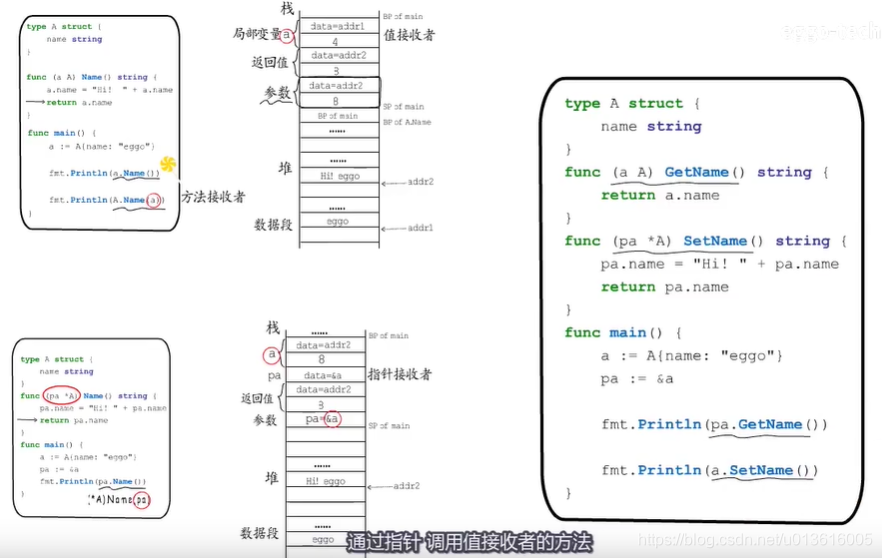
(实例).(方法) 是一种语法糖
函数类型只和参数、返回值相关
方法本质上就是普通的函数,而接收者就是隐含的第一个参数
- a.M() == A.M(a)

- 值可以调用指针调用者;指针可以调用值接收者
编译阶段,编译器会帮你处理
编译期间发挥作用
字面量不能通过编译
why? 字面量 literal只是一个值,不是变量,
变量就是给一段内存空间起名字,字面量不是变量,编译期间,没有自己的内存地址,当然取不了地址

- both method exp and val are funcval
表达式 方法表达式 funcval
变量 方法变量 也是funcval,而且它会捕获方法接收者,形成闭包
f2是局部变量,与a的生命周期相同,所以,编译器会优化
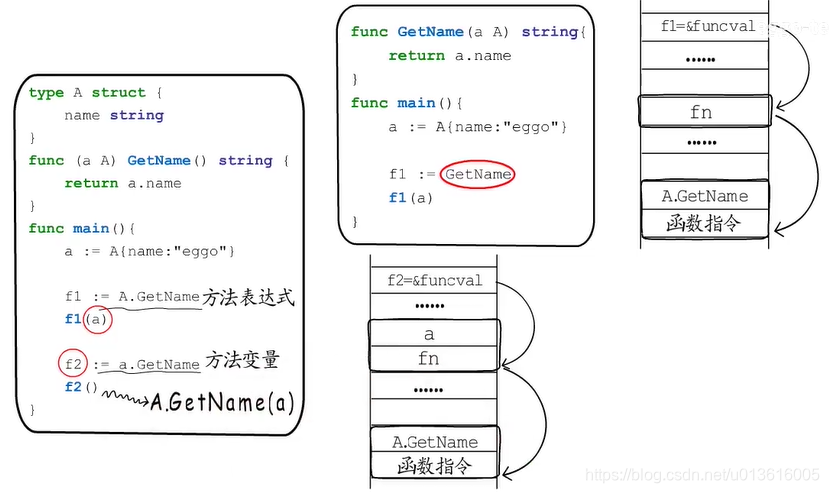
- 返回funcval的例子
可以清晰地看到闭包是如何形成的

闭包
- 定义
在函数外部定义,在函数内部引用的的“自由变量”
脱离了形成闭包的上下文,闭包也能正常使用这些自由变量
闭包就是由编译器构造出来的一个struct
这个struct是运行阶段从堆上分配的
type funcval struct {fn unitptr //函数指针... //各种捕获列表
}
- 捕获变量 和
编译阶段生成指令
1、每个闭包对象都要保存自己的捕获变量,所以要到
执行阶段才创建对应的闭包对象
2、闭包为有状态的函数,各自找各自的,虽然一样
一定要保持捕获变量在外层函数与闭包函数中的一致性- 捕获列表,仅仅是初始化赋值
局部变量
1、,那就拷贝这么简单,是的
- 捕获列表,
修改局部变量
1、闭包函数指定入口地址
2、执行阶段在堆上分配捕获变量
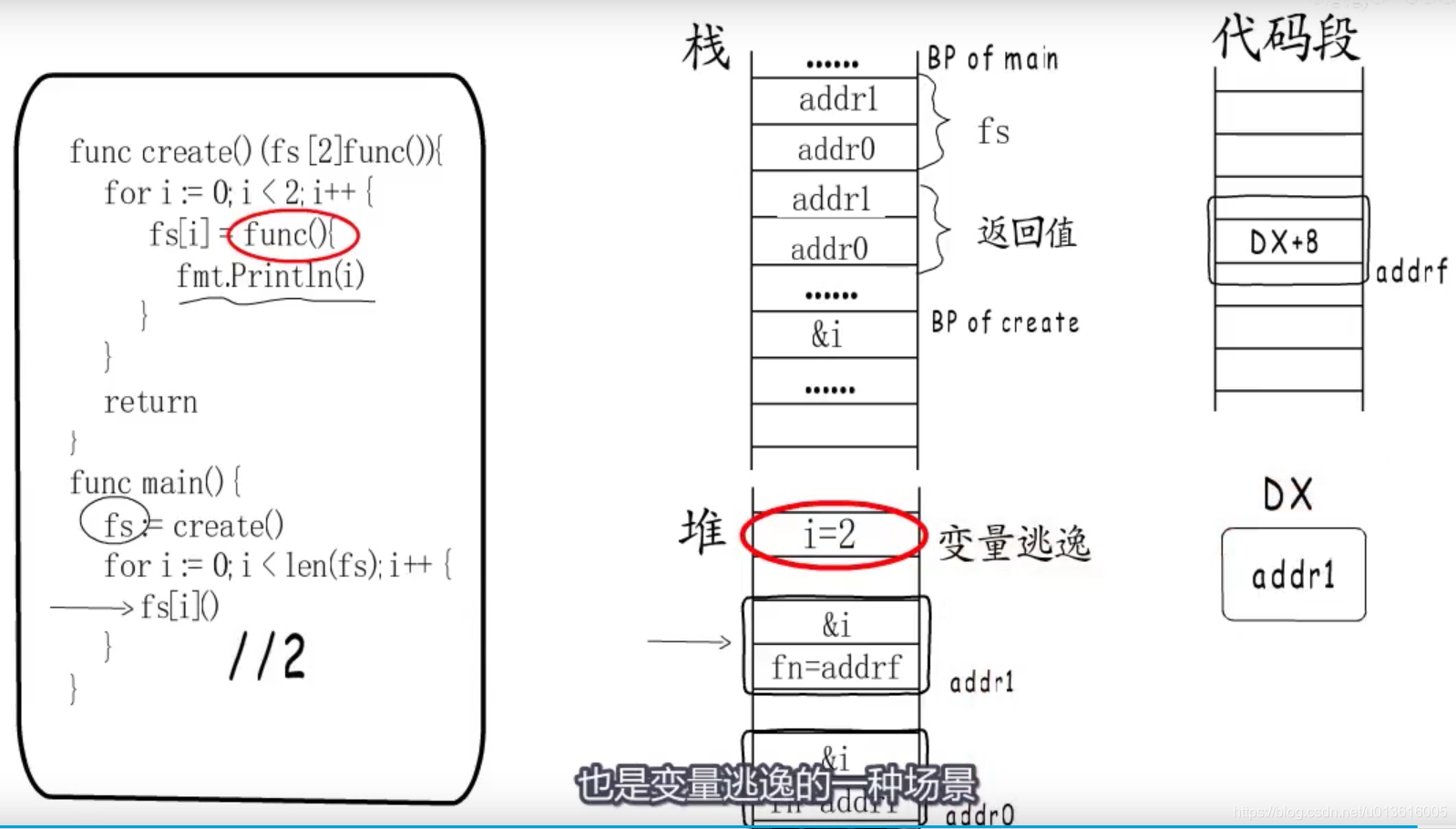
- 捕获列表,修改并被捕获的是
参数,涉及到函数原型
1、参数依然通过调用者栈帧传入
2、编译器栈上这个参数拷贝到堆上一份,内外函数都使用堆上分配的
- 捕获列表,修改并被捕获的是
返回值
1、调用者栈帧上依然会分配返回值空间
2、闭包的外层函数会在堆上也分配一个,内外函数都使用堆上分配的
3、外层函数返回前,需要把堆上的返回值拷贝到栈上的返回值空间
- 方法 == 闭包
闭包属于语言特性,方法变量属于实现方式的一种
Go语言中并没有把闭包从Function Value中区分出来,闭包只是有捕获列表的Function Value而已;
这里说方法变量=闭包,就是因为方法变量本质上就是捕获了方法接收者的Function Value
defer
- 流程
1、
deferproc负责把要执行的函数信息保存起来,defer注册
2、先注册后调用,实现defer的延迟执行
3、defer信息会注册到一个链表,而当前goroutine持有这个链表的头指针
4、当前goroutine上添加defer时,会在链表头进行添加
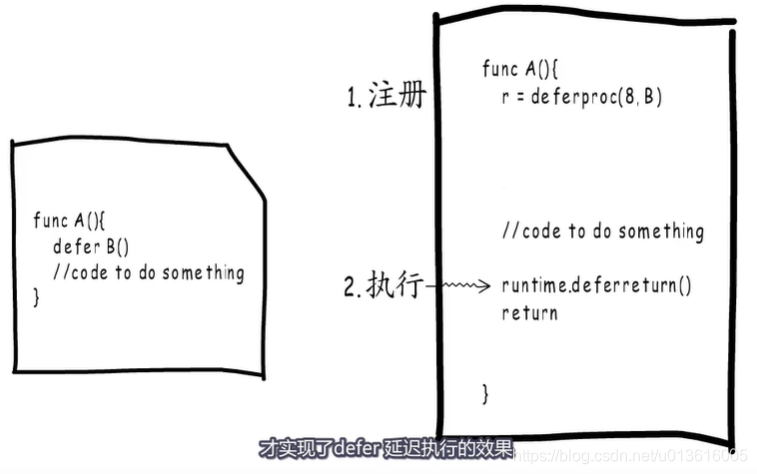
- _defer结构体
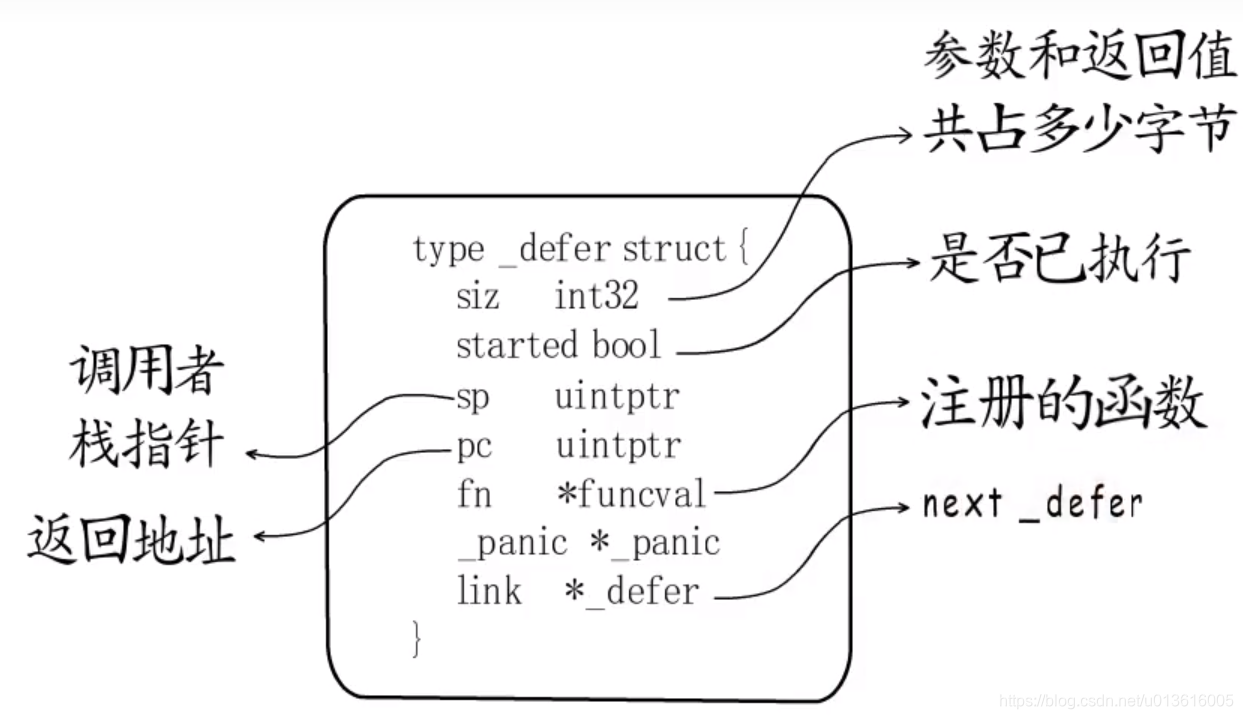
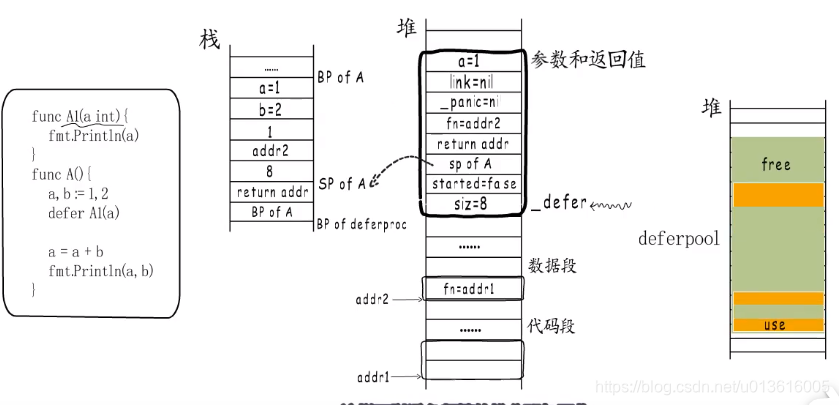
- 注册堆栈变化
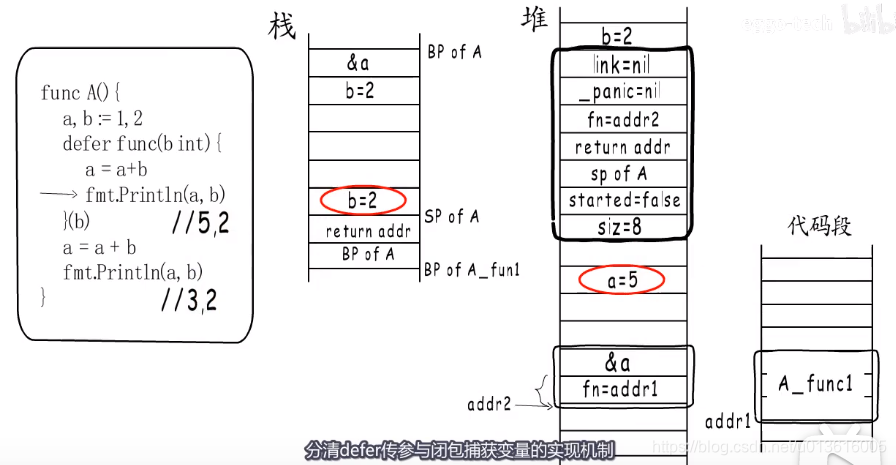
- defer传参与闭包捕获变量的实现机制
deferproc注册的是一个Function Value
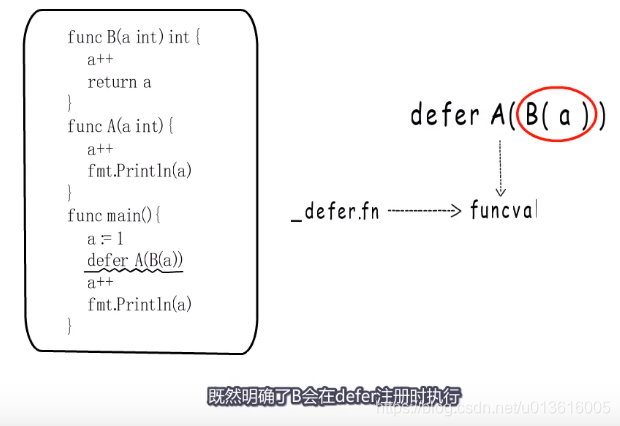
- B会在defer注册时执行
- 注册时添加链表项目,执行时移除链表项
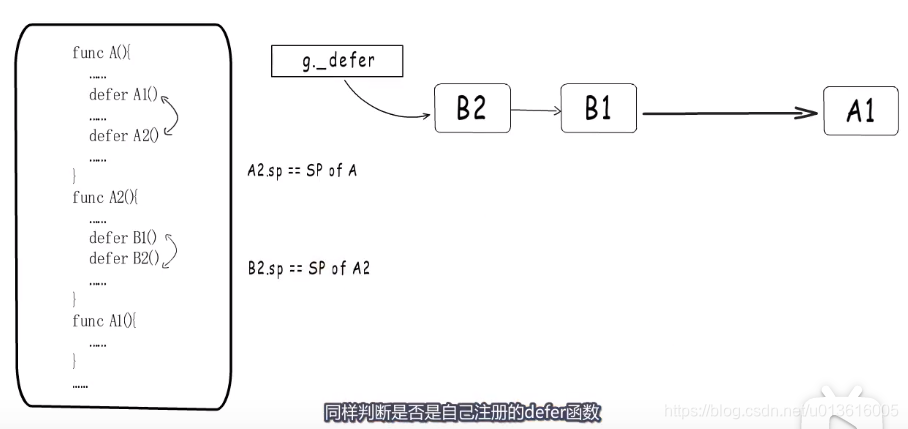
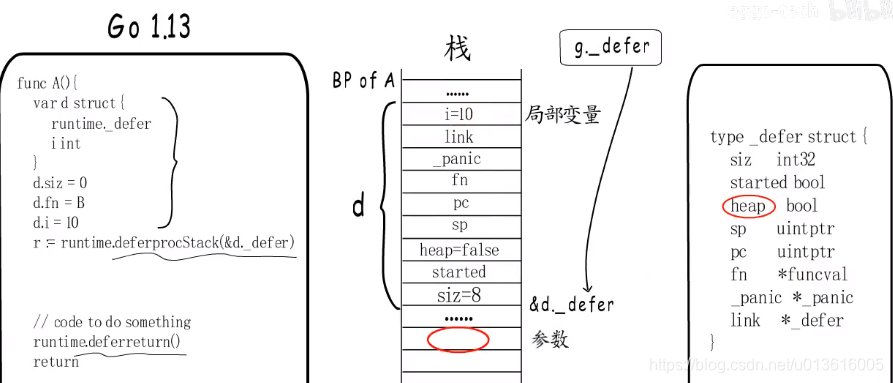
- go 1.13优化
1、
编译阶段,通过局部变量,把defer信息保存在当前函数栈帧的局部变量区域
2、再通过deferprocStack把栈上&d._defer 注册到 g._defer 链表中, 这样就减少了defer信息堆分配的情况
3、显式或隐式循环会继续采用之前的处理策略,直接在堆上处理&d._defer信息
4、heap 标识是否为堆分配
5、defer执行时依然是通过deferreturn实现的,从栈上的局部变量空间拷贝到参数空间
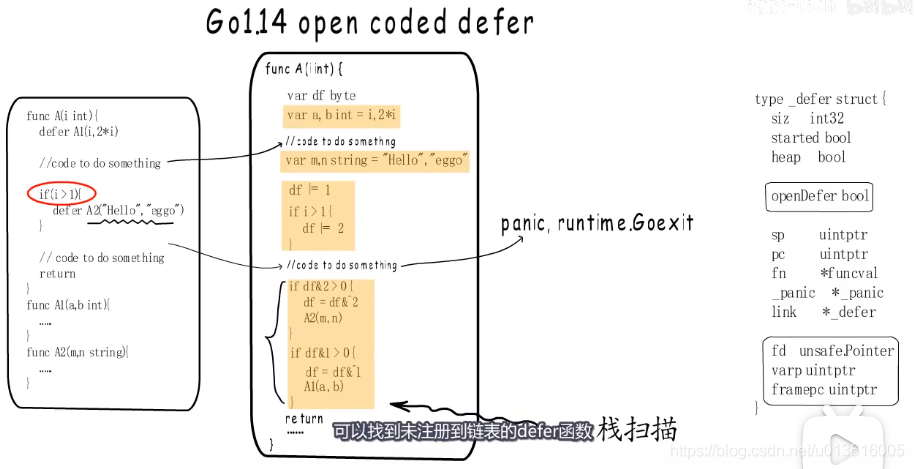
- go 1.14 优化
1、
编译阶段,通过插入代码,把defer函数的执行逻辑展开在当前函数内,省去了构造defer链表项
2、open coded defer的代价就是在发生panic 或 runtime.Goexit时,需要通过栈扫描的方式执行后续的defer函数
3、panic的处理速度慢了,设计理由:panic发生的几率要比defer低

panic
-
_panic
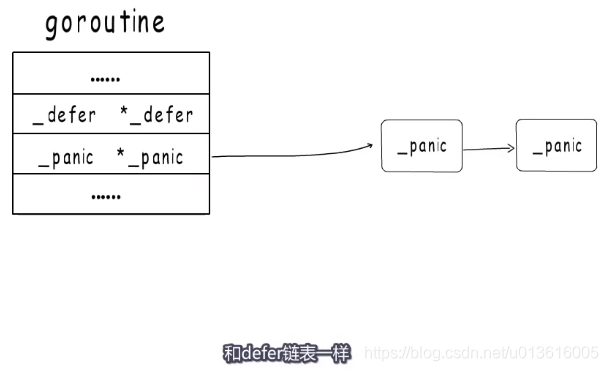
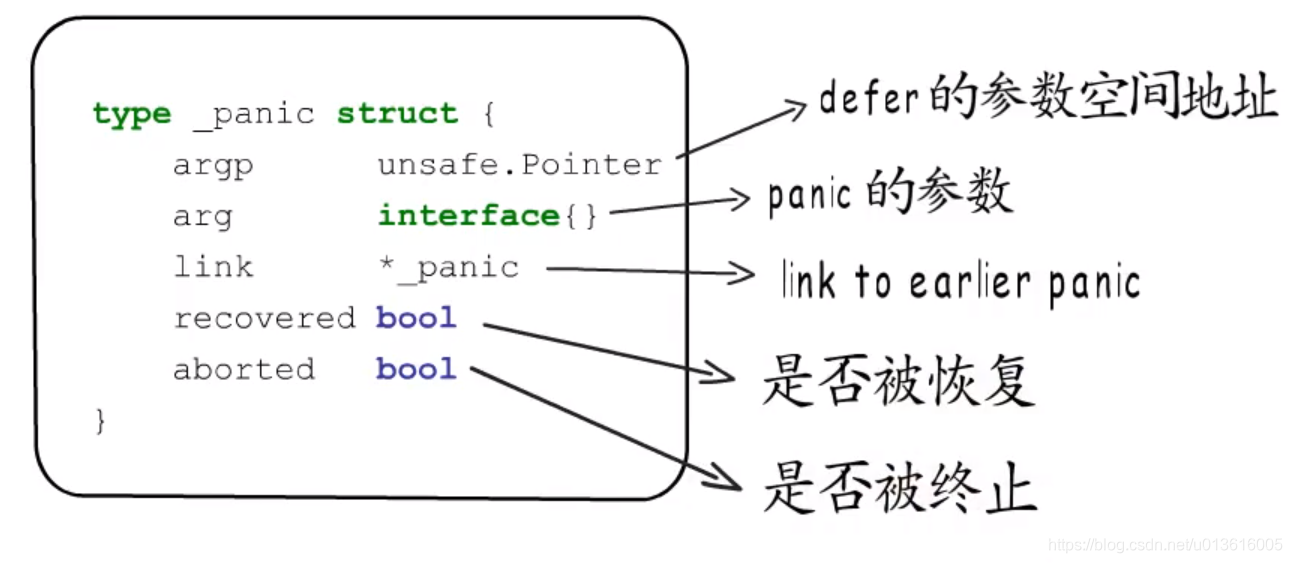
-
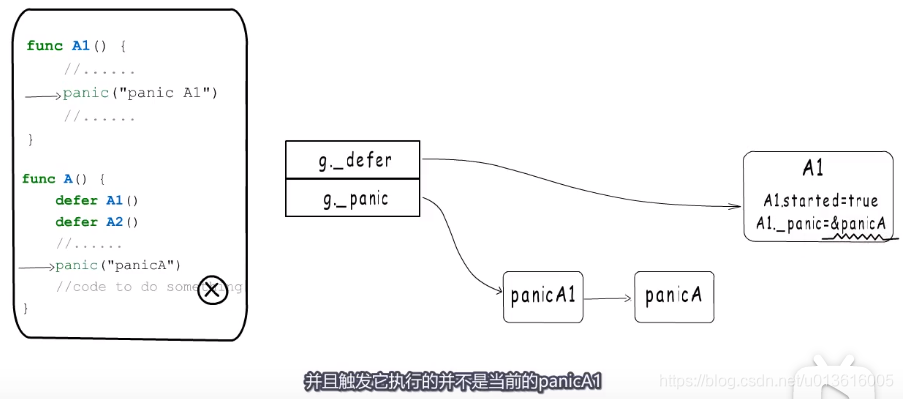
panic执行defer函数逻辑
先标记,表明这个defer是由某个panic触发的,如果正常执行,继续下一个defer,标记。。。
为什么要先标记呢?。。。应对defer函数没有正常结束的情况
后释放,终止之前发生的panic
- panic打印异常信息
顺序:从链表尾开始,== panic发生的顺序逐个输出
recover
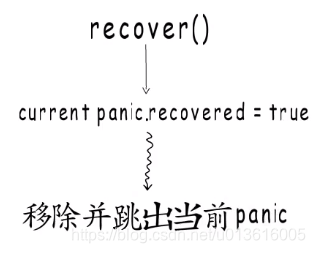
- 它做了什么呢?
1、在
发生recover的函数正常返回以后,才会进入到检测panic是否被恢复的流程,然后才能删除被恢复的panic
2、移除panic,移除defer,但,移除defer之前会保留sp pc信息,用于跳出panic的处理流程,继续执行defer链表,怎么做到的呢?
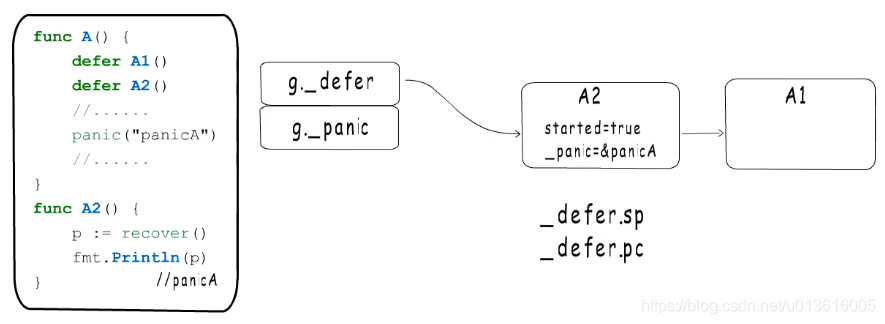
怎么做到继续defer的呢?
1、原来是在编译阶段,pc被编译器保存在一个寄存器中,操作寄存器来的快
2、deferreturn只负责执行当前函数注册的defer函数,是通过栈指针标记defer的所属实现的,
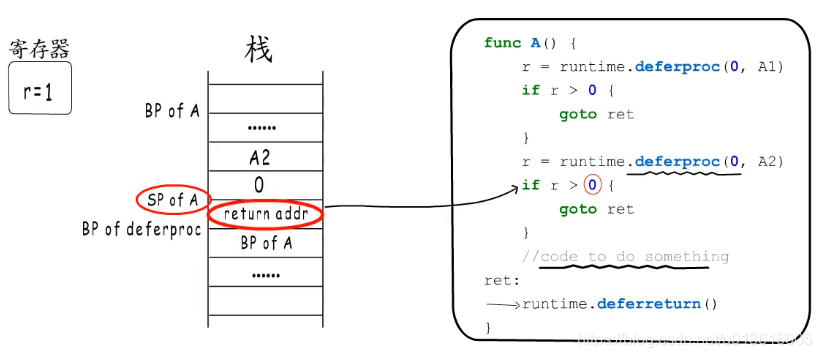
- 执行recover的函数正常返回之前又发生了panic
被恢复的panic什么情况下不会被移除
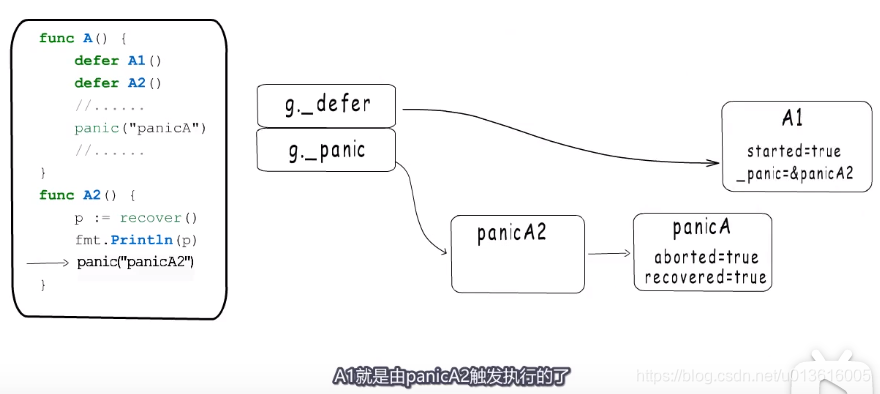
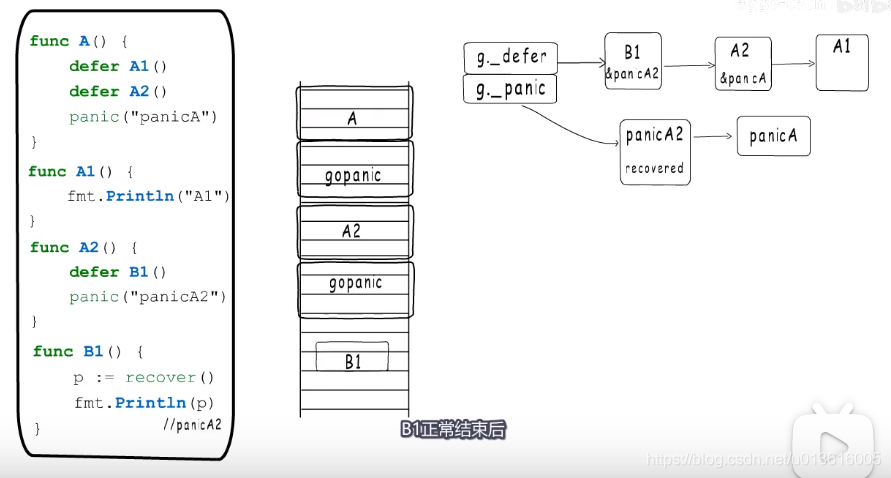
- 要不要这么嵌套,崩了~~ ^^ ~~
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!