Kaldi AISHELL V1 声纹识别过程记录
前言
因为科研项目需要用到声纹识别,有小伙伴说先跑通kaldi中的aishell v1,就能对声纹识别有一个大致的了解,本小白在Linux和C++基础薄弱的情况下,边看其中的run.sh以及其引用的脚本,再加上其他小伙伴的总结和相关理论知识,用两个月时间理清了整个流程(战线有点长,但其实还有很多细节不明白,都怪C++看不懂,一定恶补!!!),在这里记录一下自己的学习过程,欢迎各位走过路过的大神批评指正。
1 下载和解压数据
1.1 代码&详解
15 data=/export/a05/xna/data #创建存放数据的目录,在这一步我直接用data=data代替了一层层的目录,也不知道原作者为什么要把数据藏的这么深。
16 data_url=www.openslr.org/resources/33 #这是aishell 数据包的地址,下载比较慢,我记得是有镜像文件,我是直接在windows下用镜像地址下载后拷贝到data目录下的,共有两个文件:data_aishell.tgz和resource_aishell.tgz 分别是语音数据和字典,在声纹识别中用不到后者。
18 . ./cmd.sh #多线程并行
19 . ./path.sh #配置环境变量,方便可执行文件的调用
20
21 set -e # exit on error #若有错误则退出
22
1.2 生成文件
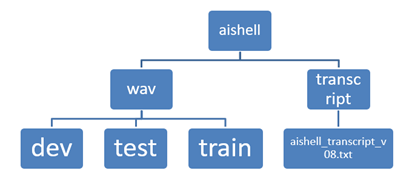
**【注】**解压缩的脚本文件有点问题,所以一直出现找不到文件的情况,在稍作修改之后解压缩成功了,其中wav中一共是400个人,分为dev (开发集,用于优化模型)40人 train训练集340人,test测试集20人,每个人说话的语音条数不一样,大致都为300多条。
2 数据准备
2.1 代码
26 # Data Preparation
27 local/aishell_data_prep.sh $data/data_aishell/wav $data/data_aishell/transcript
2.2 详解
数据准备脚本的细节我直接省略了,大致过程就是在data/local下创建dev test train三个文件夹,然后把语音所需要的各个数据都存放在这三个文件夹中作为中间数据,然后创建data/test data/train 两个文件夹,把data/local下的数据复制到这两个文件夹中。
2.3 生成文件
其实我们只需要知道,最终这个语句做的事情就是在data/test和data/train中生成了以下文件:spk2utt text utt2spk wav.scp
spk2utt和utt2spk 是两个表格,可以用vi打开,格式如下:
spk2utt <说话人编号> <语音编号>
utt2spk <语音编号> <说话人标号>
text <语音编号> <对应文字>
wav.scp<语音编号> <对应地址>
3 特征提取
3.1 代码
29 # Now make MFCC features.30 # mfccdir should be some place with a largish disk where you31 # want to store MFCC features.32 mfccdir=mfcc33 for x in train test; do34 steps/make_mfcc.sh --cmd "$train_cmd" --nj 10 data/$x exp/make_mfcc/$x $mfccdir35 sid/compute_vad_decision.sh --nj 10 --cmd "$train_cmd" data/$x exp/make_mfcc/$x $ mfccdir36 utils/fix_data_dir.sh data/$x
3.2 详解
特征提取有两步:
第一步是steps/make_mfcc.sh提取mfcc特征,生成log文件放入exp/make_mfcc 的test和tr
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!